Si vous travaillez dans la data, peu importe que vous soyez data analyst, data engineer, data scientist, vous entendez sûrement parler de data warehouses, de data lakes ou de lakehouses. Ça peut vite sembler flou, alors que chacun a un rôle bien précis. Comprendre la différence entre ces systèmes permet de savoir où stocker ses données, comment les exploiter et surtout quelles problématiques chaque type d’architecture vient résoudre.
Data warehouse (DW)
Les data warehouses sont apparus parce que les bases de données « classiques » ne sont tout simplement pas faites pour de l’analyse à grande échelle. Une base transactionnelle doit rester rapide pour les traitements pour lesquels elle a été conçue. Et donc si vous commencez à lui balancer des requêtes SQL de 400 lignes avec 15 jointures ou même des requêtes simples mais sur une volumétrie de données énorme pour alimenter votre dashboard de reporting, vous allez finir par :
- impacter les perfs de la prod
- recevoir un mail le lendemain de l’Infra avec pour objet : QUI A LANCÉ ÇA ?
- et potentiellement vous faire quelques ennemis côté métier et Infra. 😁
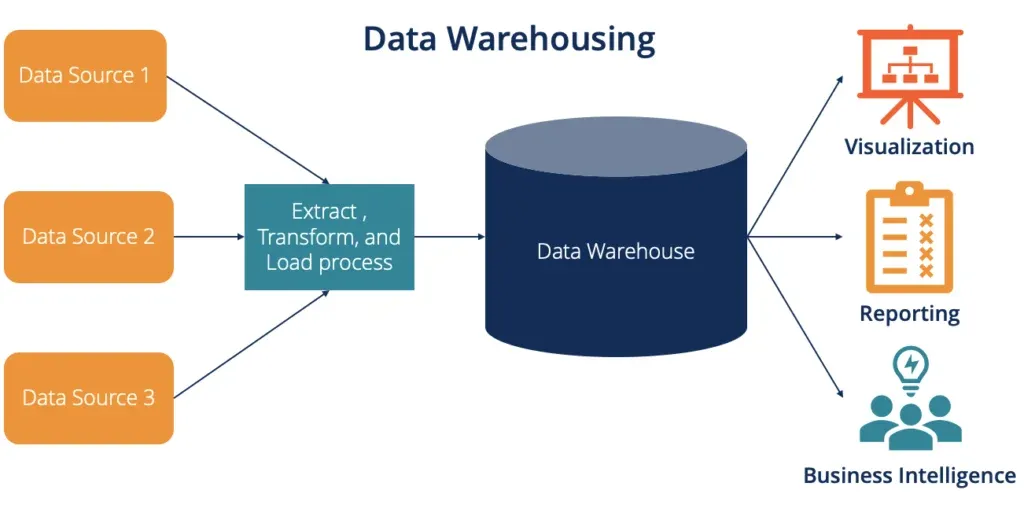
Le data warehouse sert donc d’espace dédié à l’analyse. Donc pour faire simple l’idée est de récupérer les données de plusieurs systèmes (ERP, CRM, applications, fichiers, APIs etc. etc.), de les transformer et nettoyer selon une logique souvent de type ETL (Extract - Transform - Load), puis de les structurer et modéliser pour répondre rapidement aux besoins d’analyse (reporting).
Pour résumer les points importants, une DW se caractérise par :
- des données alimentées par des flux principalement ETL depuis plusieurs sources
- contient principalement des données historiques
- schéma généralement rigide et bien modélisé (modèle en étoile, flocon de neige)
Data Lake (DL)
Les data lakes ont été créés pour répondre aux limites des data warehouses classiques, notamment quand :
- le volume de données explose (logs, events, clics, historiques complets),
- les données ne sont pas toujours structurées (JSON, texte, images, vidéos, fichiers),
- on veut conserver tout le détail brut pour des usages plus tard (IA, data science, exploration), sans devoir décider tout de suite du schéma. (Spoiler : “plus tard” n'arrive pas toujours, mais bon, c'est comme ça)
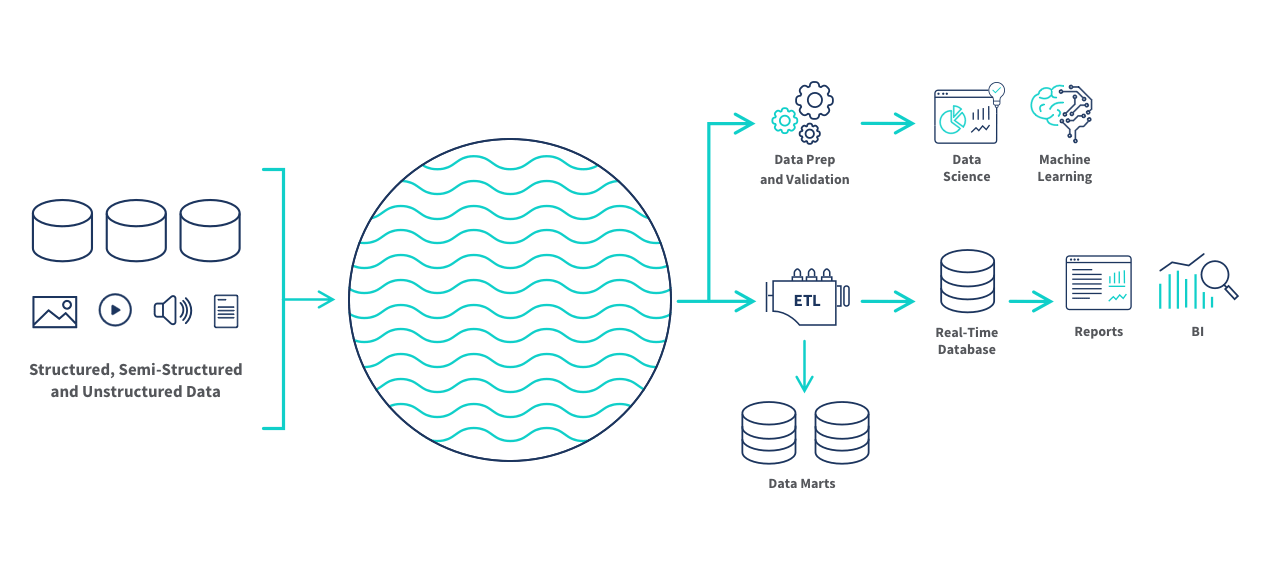
Donc l'objectif d'un data lake est de stocker massivement, à moindre coût, toutes les données brutes au même endroit, puis appliquer la structure et les transformations uniquement quand on en a besoin.
Caractéristiques :
- accepte des données structurées, semi-structurées et non structurées,
- alimenté par des flux principalement ELT,
- stockage peu coûteux et scalable (cloud, fichiers, objets),
- idéal pour la data science, le machine learning, l’exploration avancée,
Data Lakehouse : le pont entre data lake et data warehouse
Avoir à la fois un data lake et un data warehouse crée de la complexité. On stocke les données brutes dans le data lake, puis on en recopie une partie dans le data warehouse pour le reporting. Cela peut apparaitre bien sur le papier mais en réalité cela entraîne des doublons, des coûts supplémentaires, une synchronisation difficile et parfois deux versions différentes de la “vérité”. Et donc c’est pour répondre à cette problématique que le lakehouse est apparu.
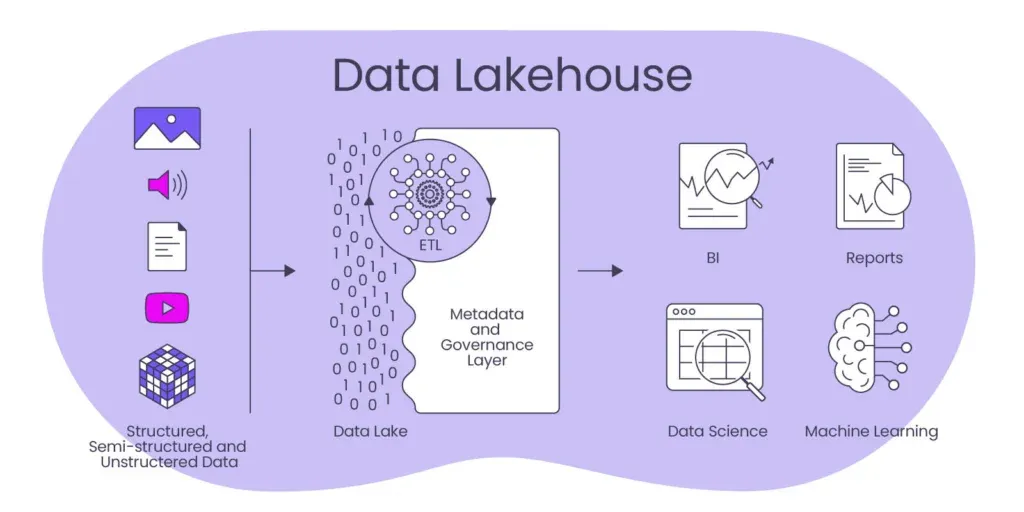
Le lakehouse réunit le meilleur des deux mondes dans une seule plateforme. Comme un data lake, il permet de stocker de grandes quantités de données brutes à faible coût et comme un data warehouse, il apporte une structure de tables, des schémas gérés, des garanties ACID et de bonnes performances pour le SQL et l’analytics.
Concrètement, il permet d’utiliser le même socle de données pour la BI , la data science et le machine learning, sans multiplier les copies.
Caractéristiques :
- stockage type data lake (souvent des fichiers Parquet sur du stockage objet)
- tables structurées
- schéma géré
- transactions ACID
- bonnes performances pour l’analytics.
Exemples de solutions lakehouse :
- Databricks Lakehouse Platform (avec Delta Lake)
- Apache Iceberg (exemple : qlik open lakehouse) , Apache Hudi.
Pour résumer, le choix du type de la base de données va dépendre principalement des besoins réels.
Si le besoin est principalement du reporting sur des données structurées ( tableaux de bord, suivi métier), un data warehouse bien conçu est souvent la solution la plus simple, et économique. Mettre en place un data lake ou un lakehouse dans ce cas peut ajouter une complexité inutile.
Si vous avez une forte demande en data science, machine learning, exploration de données, stockage de données brutes ou variées (logs, fichiers, événements, etc.), se limiter à un data warehouse peut vite devenir contraignant et vous pousser plus tard à réarchitecturer. Dans ce contexte, un data lake ou, mieux, une approche lakehouse devient plus adaptée.
