
Quand une requête est lente dans Snowflake, le réflexe est souvent le même soit
augmenter la warehouse, relancer la requête, ou accepter que "c'est lourd".
Le problème, c'est que sans le Query Profile, on ne sait pas ce que Snowflake fait réellement.
Dans cet article, on va prendre 3 requêtes simples, et regarder comment le moteur Snowflake les exécute.
Comment lire le Query Profile.
Quand tu ouvres un Query Profile, je te conseille de commencer par deux zones : l'Overview et les statistics. L'Overview te dit comment le temps a été utilisé. Les Statistics te disent combien de données ont été lues.
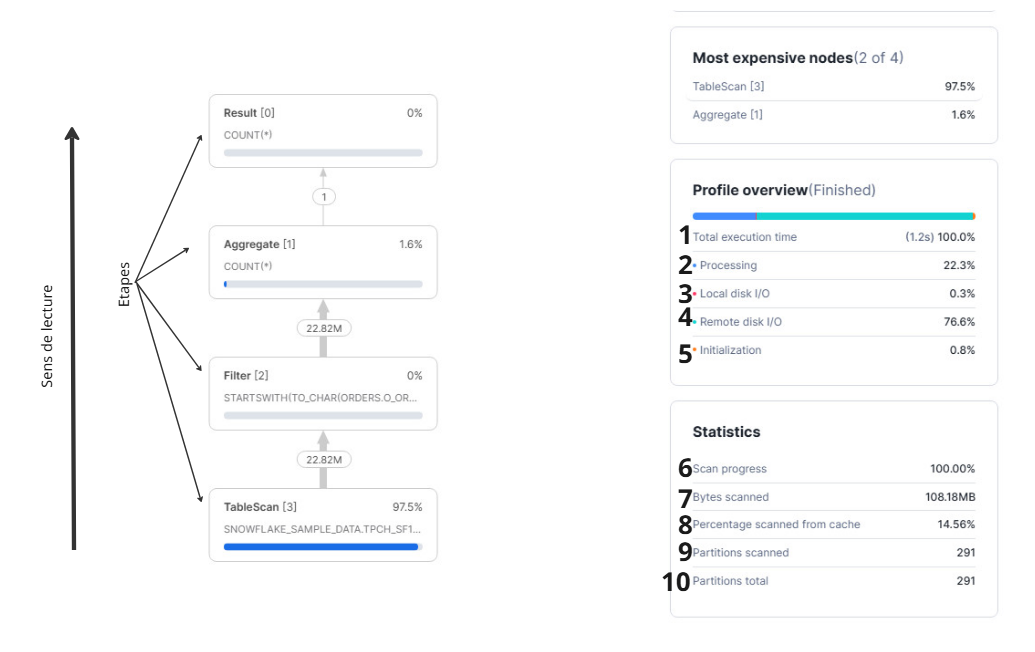
Profile Overview
(1) Total Execution Time
C'est le temps réel d'exécution de la requête.
(2) Processing %
C'est le temps passé côté CPU. Si ce chiffre est haut, la requête est plutôt CPU bound. En général, c'est le signe de calculs lourds, gros tris, grosses jointures, ou transformations complexes.
(3) Local Disk I/O %
C'est l'attente côté disque local (SSD). Ça peut apparaître quand Snowflake écrit ou relit localement, ou quand certaines opérations dépassent la mémoire.
(4) Remote Disk I/O %
C'est le temps passé à attendre la lecture depuis le stockage distant. Si ce chiffre est haut, la requête est surtout "I/O bound". Là, la meilleure optimisation est souvent de lire moins de données.
(5) Initialization %
C'est le temps passé à préparer ou compiler la requête. Normalement c'est faible. Si c'est haut, ça peut indiquer une requête trop complexe pour ce qu'elle fait (beaucoup de sous-requêtes, logique inutile).
Synchronizing %
Ce n'est pas l'indicateur le plus utile, mais quand il monte, ça peut venir d'étapes qui demandent beaucoup de coordination entre processus, souvent des sorts ou des échanges de données.
Statistics
(6) Scan Progress
Utile quand la requête est encore en cours. Ça te donne l'avancement du scan et une idée du temps restant.
(7) Bytes Scanned
Le volume de données lu. Snowflake est colonnaire, donc il lit surtout les colonnes nécessaires, mais ce chiffre te donne une idée très claire de 'combien tu payes en lecture'.
(8) Percentage Scanned from Cache
C'est la part des données servies depuis le cache. Attention car ça peut te donner une fausse impression. Une requête "mauvaise" peut sembler rapide avec un cache chaud. Et une requête "bonne" peut sembler plus lente si le cache est froid.
(9) Partitions Scanned
Le nombre de micro-partitions réellement lues. C'est souvent le meilleur indicateur pour comprendre la performance, surtout quand la requête est dominée par le Remote Disk I/O.
(10) Partitions Total
Le total de micro-partitions disponibles sur les tables lues. À lire avec (9). Plus le ratio scanné/total est faible, plus Snowflake a réussi à éviter de lire.
Exemples :
Comme d'habitude dans les articles de la formation, y'a pas mieux d'un exemple pour comprendre le concept et tous les exemples sont basés sur la table suivante :
SNOWFLAKE_SAMPLE_DATA.TPCH_SF100.ORDERS
Exemple 1 : Le filtre qui peut côuter cher
SELECT COUNT(*) AS nb_orders_1996
FROM SNOWFLAKE_SAMPLE_DATA.TPCH_SF100.ORDERS
WHERE EXTRACT(YEAR FROM O_ORDERDATE) = 1996;
Fonctionnellement, la requête est correcte.
Mais regardons le Query Profile.
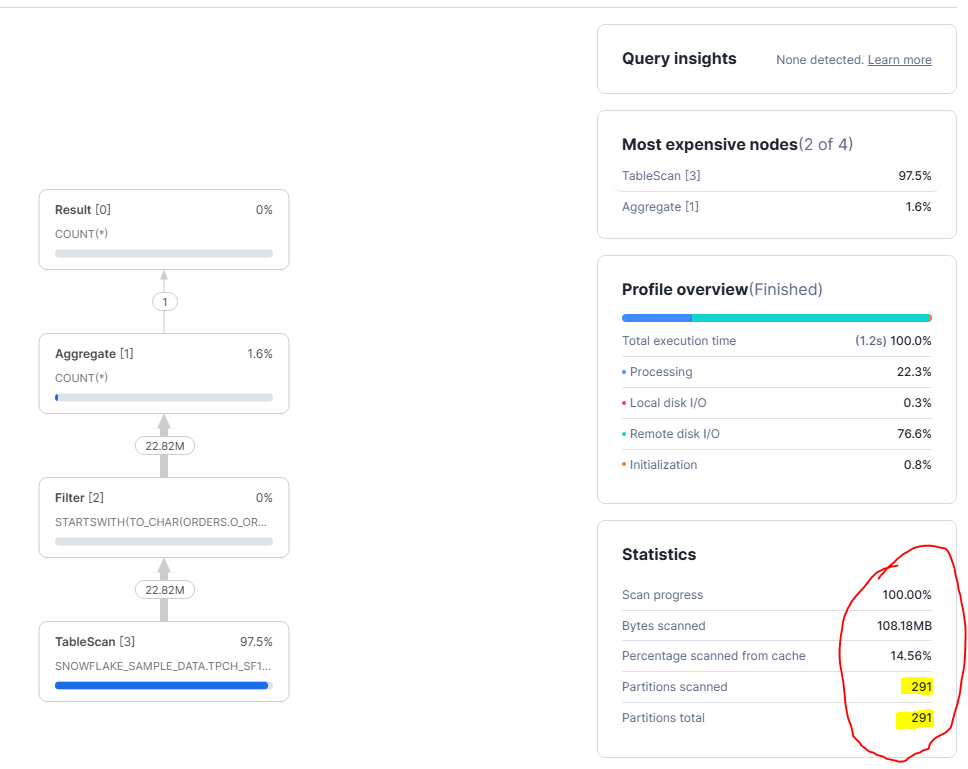
Sur cette requête, Snowflake a lu toute la table.
Quand tu vois :
- Partitions scannées : 291
- Partitions totales : 291
ça veut dire une chose très simple :
👉 aucune micro-partition n'a pu être éliminée.
Snowflake n'a pas eu le choix. Il a dû lire 100 % des partitions pour répondre à la requête.
La raison est dans la condition de filtre : STARTSWITH(TO_CHAR(O_ORDERDATE), '1996'). Ici, on transforme la colonne O_ORDERDATE en texte avant de filtrer. Pour Snowflake, ça casse l'utilisation des métadonnées des micro-partitions. Il ne peut plus se dire “je prends uniquement les partitions qui contiennent 1996”. Il est obligé de lire les données, convertir chaque valeur en chaîne, puis vérifier si ça commence par 1996. Le filtre fonctionne, mais il arrive trop tard, après la lecture.
Le point important, c'est que ce n'est pas le COUNT(*) qui coûte cher. L'agrégation est presque gratuite (1,6%). Le problème est entièrement dans la lecture. Donc une requête qui paraît simple, mais qui force Snowflake à travailler à l'ancienne donc tout lire, puis filtrer ligne par ligne.
Exemple 2 : Même résultat, exécution complètement différente
On reprend le même exemple que précédemment, mais on modifie le filtre pour que Snowflake puisse exploiter les métadonnées des micro-partitions.
SELECT COUNT(*) AS nb_orders_1996
FROM SNOWFLAKE_SAMPLE_DATA.TPCH_SF100.ORDERS
WHERE O_ORDERDATE >= '1996-01-01'
AND O_ORDERDATE < '1997-01-01';
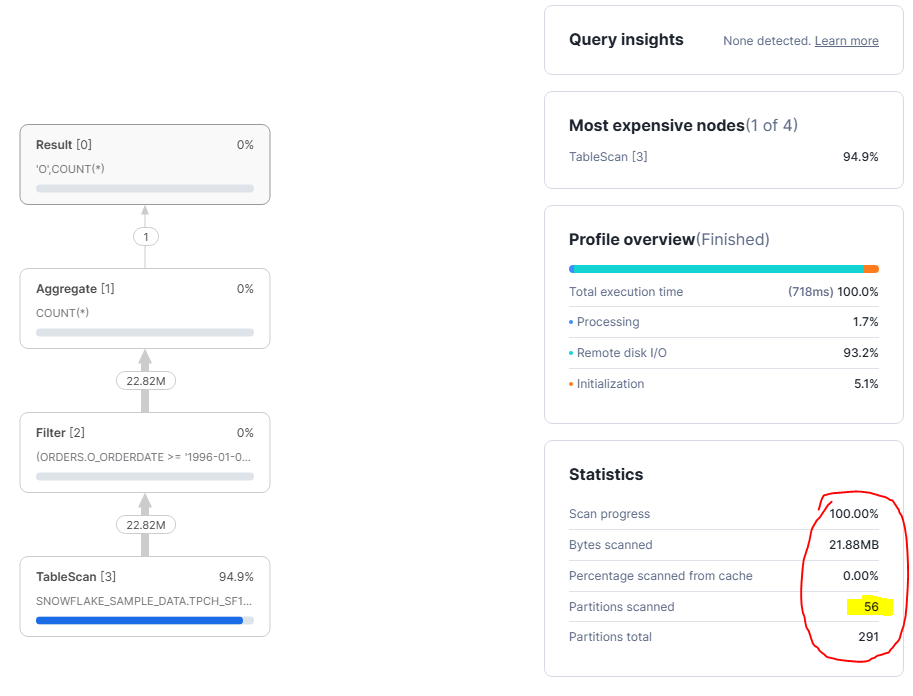
On voit clairement que Snowflake n'a plus lu toute la table. Cette fois, il a scanné 56 partitions sur 291. C'est la différence fondamentale avec l'exemple précédent. Le moteur a réussi à éliminer une grande partie des micro-partitions avant même de lire les données. Ça veut dire que le filtre a été compris et utilisé par Snowflake dès le début du scan.
La raison est simple car le filtre est maintenant une comparaison directe sur la colonne O_ORDERDATE. Snowflake peut comparer les bornes de dates avec les métadonnées des micro-partitions et décider lesquelles sont pertinentes. Il lit uniquement les partitions qui peuvent contenir des commandes de 1996, et ignore toutes les autres. Le filtrage se fait au moment de la lecture, pas après.
La requête est donc plus saine, plus stable, et surtout plus prévisible en production. Ici, le moteur travaille comme il est censé le faire.
Exemple 3 : Le cas des jointures
SELECT COUNT(*) AS nb_lines_1996
FROM SNOWFLAKE_SAMPLE_DATA.TPCH_SF100.ORDERS O
JOIN SNOWFLAKE_SAMPLE_DATA.TPCH_SF100.LINEITEM L
ON L.L_ORDERKEY = O.O_ORDERKEY
WHERE O.O_ORDERDATE >= '1996-01-01'
AND O.O_ORDERDATE < '1997-01-01';
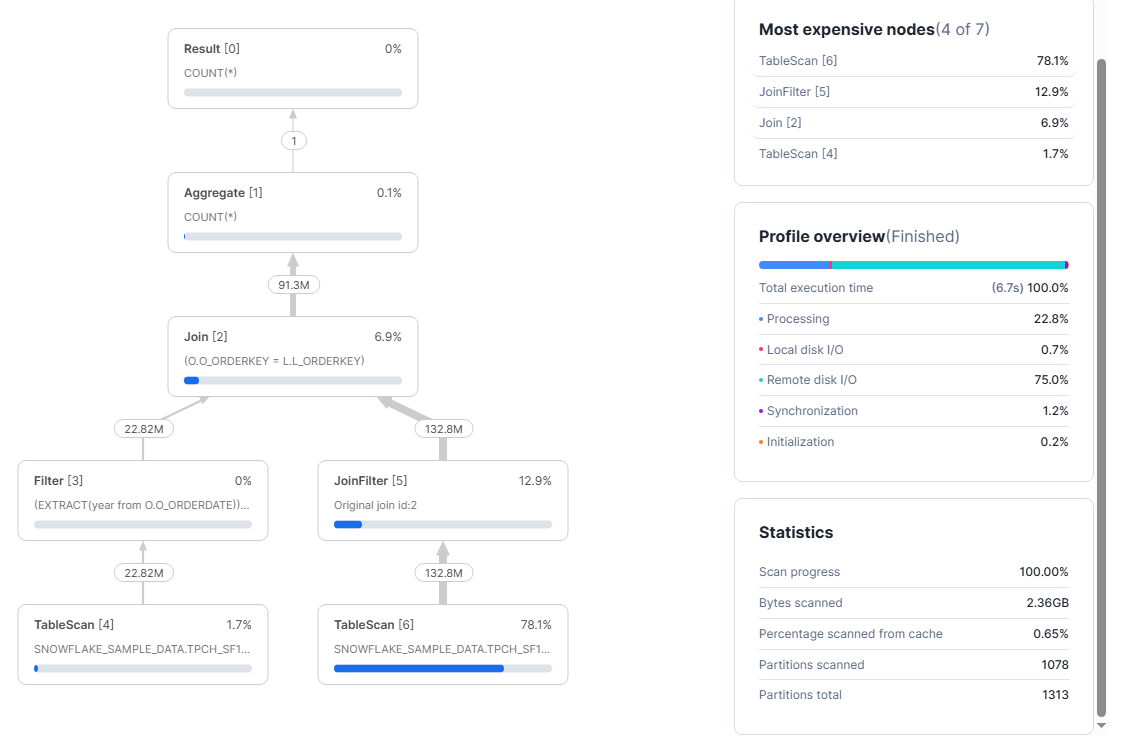
Dans cet exemple, on n'est plus sur une requête avec une seule table. Dès qu'on joint ORDERS avec LINEITEM, Snowflake doit gérer beaucoup plus de données. Et ça se voit direct dans le Query Profile. La requête dure environ 6,7 secondes, et la plupart du temps part en Remote disk I/O (environ 75%). Donc le problème n'est pas le COUNT(*). Le problème, c'est surtout la lecture des données.
Ce qui coûte le plus cher ici, c'est le TableScan de LINEITEM (TableScan [6]). Il représente 78,1% du coût. C'est normal, parce que LINEITEM est beaucoup plus grosse que ORDERS. Snowflake lit environ 2,36 GB, et le cache n'aide presque pas (0,65%). Et surtout, il scanne 1078 partitions sur 1313. En clair, il lit presque toute la table LINEITEM.
Ce profil montre un cas très courant. Tu filtres sur l'année, mais cette information est dans ORDERS. Or la table la plus lourde à lire, c'est LINEITEM, et elle n'a pas la date. Donc Snowflake ne peut pas vraiment réduire LINEITEM avant la jointure. Résultat : il lit énormément de LINEITEM, fait la jointure, puis seulement après le filtre a un vrai effet.
Si tu veux optimiser, le premier réflexe n'est pas de grossir la warehouse. Ça peut aider un peu, mais ça ne change pas le fond du problème. Le vrai levier, c'est de lire moins de données, surtout côté LINEITEM. Pour ça, il faut trouver un moyen de réduire le volume dès le début (souvent en adaptant le modèle de données ou en préparant une table déjà filtrable).
Au final, tous ces exemples montrent la même chose. Le Query Profile ne sert pas à faire de la micro-optimisation ou à comparer des requêtes au milliseconde près. Il sert plutôt à comprendre où Snowflake passe vraiment son temps. Très souvent, le problème n'est pas le calcul, mais la lecture. Et tant que tu lis trop de données, aucune réécriture SQL ni aucune grosse warehouse ne feront de miracle.
Le Query Profile te permet de voir si un filtre aide réellement le scan, ou s'il arrive trop tard. Il te montre aussi quand une jointure fait exploser les volumes, et surtout quelle table est réellement responsable du coût.
Aller plus loin : Formation Snowflake
J'ai regroupé tous mes articles Snowflake dans un parcours complet.
👉 Le parcours complet (articles + pratique)
Vous voulez que je vous accompagne sur votre projet data (Snowflake, ingestion, modélisation, performance, coûts, gouvernance) ?
👉 Réserver un appel de 30 minutes