
Dans le premier article de la formation Snowflake, on a fait le tour des bases de son architecture, notamment la séparation entre le storage, le compute et les cloud services .
Et c'est justement cette séparation qui rend, selon moi, le FinOps sur Snowflake assez "mécanique" car dès que tu sais où part l'argent, tu vois assez vite quoi ajuster.
D'ailleurs, comme je l'ai vu passer sur un post Reddit à propos des coûts :
La majorité des dérapages Snowflake viennent du compute mal piloté, pas du storage. Trois leviers à actionner dans l'ordre : (1) visualiser ce qui consomme, (2) poser des garde-fous avec Resource Monitors et Budgets, (3) optimiser auto-suspend, séparation des warehouses, refresh BI et chargements incrémentaux.
Donc dans cet article, je vais me baser sur les trois leviers qui, à mon sens, sont les plus importants à connaitre pour maîtriser les coûts sur Snowflake ( visibilité → garde-fous → optimisation ), sachant que aucun d'entre eux ne suffit seul car leur efficacité dépend du contexte, et surtout de la manière dont ils sont combinés et gouvernés.

Avant de plonger dans les resource monitors et les budgets, il y a un prérequis est de comprendre comment fonctionne vraiment un virtual warehouse. Sizing, multi-cluster, scaling, concurrence... Si tu passes directement au FinOps sans avoir ces bases, c'est un peu comme optimiser la consommation d'une voiture sans savoir ce qu'est un moteur. (voir l'article)
1) Ce que tu payes vraiment sur Snowflake
Avant de chercher à optimiser les coûts, il faut bien savoir d'abord ce qui cout de l'argent :
Le compute (Virtual Warehouses)
Un warehouse consomme des crédits quand il tourne. Snowflake facture à la seconde, mais avec un minimum de 60 secondes à chaque start ou resume. Donc si tu réveilles un warehouse toutes les 2 minutes pour des petites requêtes, tu peux te retrouver à payer une taxe du démarrage en boucle.
La logique à garder en tête est simple et c'est coût = taille × durée × nombre de warehouses.
Le serverless
Certaines features utilisent du compute géré par Snowflake (serverless). C'est facturé à l'usage, et ça peut faire monter la facture en flèche si tu actives des features sans mesurer derrière.
Storage
Le storage est en général plus prédictible, mais il peut gonfler en silence quand tu multiplies l'historique (Time Travel) ou quand tu fais beaucoup de DML (UPDATE/MERGE) sur de gros volumes.
2) FinOps Snowflake
Maintenant qu'on a vu les principales opérations facturées par Snowflake, on va appliquer les trois leviers que j'ai cité en introduction pour contrôler les coûts :
- Visualiser : identifier les warehouses, utilisateurs, requêtes qui coûtent vraiment.
- Contrôler : empêcher un dérapage (budget, seuils, suspension).
- Optimiser : réduire le compute inutile et améliorer les requêtes.
A) Visualiser : Trouver ce qui brûle des crédits
Avant d'optimiser, il faut répondre à une question simple "où part le compute ?" et sur Snowflake, on a la chance de pouvoir descendre au niveau des requêtes, parce que c’est elles qui déclenchent la consommation.
Coût par requête
Snowflake fournit une vue dédiée et c'est QUERY_ATTRIBUTION_HISTORY. Elle permet d'estimer le coût compute attribué à une requête exécutée sur un warehouse, sur une période donnée. L'objectif est d'identifier rapidement les requêtes les plus coûteuses, puis de comprendre le pourquoi du comment (fréquence, SQL, warehouse, usage BI, etc..).
Exemple : top 20 des requêtes les plus chères des 30 derniers jours
SELECT
query_id,
user_name,
warehouse_name,
credits_attributed_compute,
start_time
FROM snowflake.account_usage.query_attribution_history
WHERE start_time >= DATEADD('day', -30, CURRENT_TIMESTAMP())
ORDER BY credits_attributed_compute DESC
LIMIT 20;
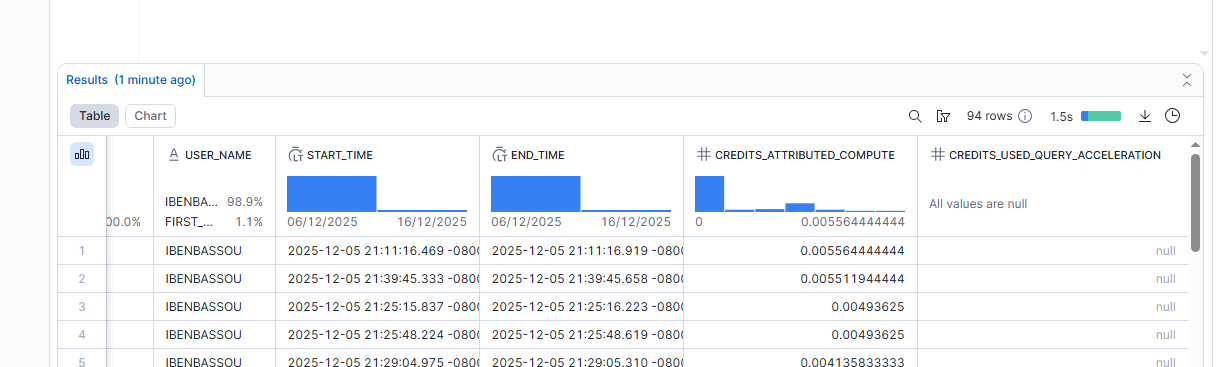
Une fois que tu as cette liste, tu regardes qui les lance, à quelle fréquence, sur quel warehouse, et tu identifies ce qui est réellement actionnable.
Coût par warehouse
Après avoir vu la consommation par requête, il faut analyser les warehouses, mais surtout le coût idle car un warehouse qui tourne alors que peu de requêtes sont réellement attribuées. C'est souvent là qu'on trouve le problème à régler rapidement (auto-suspend mal réglé, warehouse partagé laissé allumé, ping-pong start/resume).
Exemple : estimer le coût "idle" sur 10 jours
SELECT
SUM(credits_used_compute) as credits_used_compute,
(SUM(credits_used_compute) -
SUM(credits_attributed_compute_queries)) AS idle_cost,
warehouse_name
FROM SNOWFLAKE.ACCOUNT_USAGE.WAREHOUSE_METERING_HISTORY
WHERE start_time >= DATEADD('days', -10, CURRENT_DATE())
AND end_time < CURRENT_DATE()
GROUP BY warehouse_name;
Pourquoi les tags sont importants
À ce stade, tu sais quelles requêtes et quels warehouses coûtent... mais pas forcément quelle équipe ou quel projet est derrière (surtout si un warehouse est partagé). Les tags permettent d'ajouter ce contexte et de faire une attribution propre. Je ferai un article dédié sur la mise en place et l'exploitation des tags pour le FinOps.
B) Contrôler (Mettre des garde-fous)
Resource Monitors
Un resource monitor sert à contrôler les coûts et à éviter une consommation inattendue de crédits. Comme on l'a vu, un warehouse consomme des crédits tant qu'il tourne. Donc c'est primordial d' avoir des notifications (et éventuellement des seuils de suspension) pour suivre la consommation et éviter que ça dérape.
Exemple simple :
CREATE OR REPLACE RESOURCE MONITOR rm_bi_monthly
WITH CREDIT_QUOTA = 300
FREQUENCY = MONTHLY
START_TIMESTAMP = IMMEDIATELY
TRIGGERS
ON 70 PERCENT DO NOTIFY
ON 90 PERCENT DO SUSPEND
ON 100 PERCENT DO SUSPEND_IMMEDIATE;
ALTER WAREHOUSE BI_WH SET RESOURCE_MONITOR = rm_bi_monthly;
Détail important et souvent méconnu, les quotas des resource monitors comptent aussi la conso Cloud Services, et que les limites ne tiennent pas compte de l'ajustement quotidien des 10%. Donc pour simplifier, Snowflake utilise toute la conso Cloud Services pour savoir si une limite est atteinte, même si elle n'est pas facturée.
Contrôle du Budgets
L'idée du contrôle via un budget est simple, tu surveilles la consommation du compte en fixant une limite mensuelle, et tu reçois une alerte avant de la dépasser.
-- 1) Activer le budget du compte
CALL SNOWFLAKE.LOCAL.ACCOUNT_ROOT_BUDGET!ACTIVATE();
-- 2) Fixer une limite mensuelle (ex: 1000 crédits)
CALL SNOWFLAKE.LOCAL.ACCOUNT_ROOT_BUDGET!SET_SPENDING_LIMIT(1000);
-- 3) Déclencher les notifications plus tôt (ex: dès 80% de la limite)
CALL SNOWFLAKE.LOCAL.ACCOUNT_ROOT_BUDGET!SET_NOTIFICATION_THRESHOLD(80);
-- 4) Envoyer les notifications par email (emails vérifiés)
CALL SNOWFLAKE.LOCAL.ACCOUNT_ROOT_BUDGET!SET_EMAIL_NOTIFICATIONS(
'<MAIL@MAIL.COM>'
);
Soyant réaliste, le suivi du budget au niveau du compte n'est pas idéal. Il est préférable de suivre et de piloter les dépenses plus finement, par Env, par projet, par tags. (Et oui, on retombe sur le même point que dans la section précédente, les tags sont essentiels pour attribuer et suivre les coûts.)
USE SCHEMA FINANCE_DB.MART_FINANCE;
CREATE SNOWFLAKE.CORE.BUDGET bi_budget();
CALL bi_budget!SET_SPENDING_LIMIT(300);
CALL bi_budget!SET_EMAIL_NOTIFICATIONS('<MAIL@MAIL.COM>');
CALL FINANCE_DB.MART_FINANCE.bi_budget!ADD_TAG(
(SELECT SYSTEM$REFERENCE('TAG', 'FINANCE_DB.MART_FINANCE.team_tag', 'SESSION', 'APPLYBUDGET')),
'QLIK'
);
NB : Par défaut, l’intervalle de refresh d'un budget est d'environ 6,5 heures. Si tu souhaites le réduire à 1 heure :
CALL FINANCE_DB.MART_FINANCE.bi_budget!SET_REFRESH_TIER('TIER_1H');
Attention : le TIER_1H coûte nettement plus cher. Il est à utiliser avec précaution, idéalement de façon temporaire (par exemple pendant une migration ou une période de forte variabilité), puis revenir au tier par défaut une fois la situation stabilisée.
Cost Anomalies
Les cost anomalies détectent des pics ou creux de consommation quotidienne par rapport à l'historique des consommations. Mais il y'a deux prérequis à connaître. Il faut au moins 30 jours d'historique, et si ta conso sur les 7 derniers jours est < 10 crédits, Snowflake peut ne rien flagger.
CALL SNOWFLAKE.LOCAL.ANOMALY_INSIGHTS!SET_ACCOUNT_NOTIFICATION_EMAILS(
'<MAIL@MAIL.COM>'
);
C) Optimisation
1) Bien organiser ses warehouses
La meilleure optimisation reste toujours de bien organiser les warehouse et donc ne jamais mélanger BI, ETL, Data science sur le même warehouse cela permet de d'ajuster auto-suspend, timeouts, taille, et garde-fous proprement.
2) Auto-suspend
Auto-suspend coupe le warehouse après X secondes d'inactivité. C'est un levier énorme.... mais mal réglé, ça peut faire l'effet inverse.
Selon les recommandations de Snowflake :
- Pour les tasks : suspension immédiate,
- Pour DevOps/DataOps/Data Science : ~5 minutes,
- Pour le rafraîchissement des dashboard BI : au moins 10 minutes pour maintenir le cache.
NB : comme mentionné précédemment chaque start/resume déclenche un minimum de 60 secondes facturées. Donc si ton warehouse fait du ping-pong (suspend/reprend très souvent), tu risques de payer plus cher. L'objectif est de trouver une durée d'auto-suspend optimale donc assez courte pour éviter l'idle, mais assez longue pour éviter les reprises inutiles et profiter du cache et surtout sur des refresh fréquents.
CREATE WAREHOUSE MON_WAREHOUSE
WAREHOUSE_SIZE = 'MEDIUM'
AUTO_SUSPEND = 600 -- suspend après 10 minutes
AUTO_RESUME = TRUE;
3) Réduire la cadence de refresh
Un levier important dans l'optimisation des coûts, c'est de réduire le nombre de requêtes inutiles.
Par exemple, recharger un dashboard Qlik Sense toutes les heures alors que la table source n'est mise à jour que une fois par jour, ça n'apporte aucune valeur donc la plupart des refresh vont relancer les mêmes requêtes, pour afficher les mêmes résultats… tout en consommant des crédits.
Et c'est justement le type d'optimisation qui ne demande pas d'action côté Snowflake. La plupart du temps, c'est simplement une question de bon sens : à quelle fréquence a-t-on vraiment besoin de rafraîchir les données ?
4) Exploiter le Result Cache
Snowflake persiste les résultats des requêtes et le cache expire après 24 heures. Donc si une requête identique repasse et que rien n’a changé, Snowflake peut renvoyer le résultat sans recalculer.
Le piège, c’est que beaucoup de requêtes BI contiennent des éléments variables (timestamps, “now()”, etc.) qui cassent la cache. Une approche très simple est de faire pointer la BI sur une vue matérialisée stable.
5) Réduire les full reload
C’est un classique, mais c'est important de le rappeler : l'optimisation la plus rentable en ETL, c’est souvent de traiter uniquement le delta, au lieu de recalculer la table complète à chaque exécution. Quand tu reprocesses en boucle des données anciennes, tu gaspilles du compute, tu rallonges les temps de run.. et tu payes plus pour un résultat identique.
Et attention aussi aux "petits jobs" très fréquents car si chaque run réveille un warehouse, tu peux payer le minimum d'une minute à répétition. Dans ce cas, il est recommandé de regrouper les exécutions (batch) ou revoir l'architecture d'orchestration peut faire une vraie différence sur la facture.
Pièges fréquents
Sur le papier, activer les contrôles et les seuils suffit à maîtriser la facture. En réalité, comme souvent, le diable est dans les détails :
- Resource Monitors trop agressifs = interruptions de prod.
Suspendre un warehouse critique sur un seuil mal calibré peut casser des pipelines, des refresh BI. En pratique, on commence souvent par NOTIFY, puis on passe à SUSPEND une fois les usages stabilisés. - Budgets globaux ≠ responsabilisation.
Un budget plateforme est utile, mais pas réaliste et il ne crée pas d'ownership. Le vrai sujet FinOps vient quand les coûts sont attribués (par env./par domaine/produit/équipe) et discutés en revue mensuelle. - Cost anomalies : attention aux faux positifs.
Un pic peut être légitime (migration, reprocessing). La clé est de définir une baseline par type de charge (ETL, BI, data science) et d'alerter sur les écarts par famille plutôt que sur un global. - Auto-suspend mal paramétré : l'illusion des économies.
Si le warehouse s'endort trop vite et redémarre sans cesse, tu augmentes la latence et tu dégrades l'expérience. Il faut trouver le bon compromis entre coût et confort d’usage. - Le top requêtes coûteuses ne suffit pas.
Une requête peut être chère mais rare (ok), ou moyenne mais exécutée 10 000 fois (pas ok). Il faut regarder coût × fréquence.
Comme mentionné dans l'introduction, maîtriser les coûts sur Snowflake ne repose pas sur un réglage unique, mais sur un équilibre entre les trois leviers (visibilité, garde-fous et optimisation). Les outils sont là mais la différence se joue dans leur gouvernance et dans la capacité à les faire évoluer au rythme des usages.
Aller plus loin : maîtriser le FinOps Snowflake
Le FinOps Snowflake est un domaine clé de la certification SnowPro Core (Cost Management et Performance) et un sujet récurrent en entretien data engineer. Sur DataCertification.fr, le module SnowPro Core couvre 700 questions sur l'ensemble des domaines de l'examen, dont la partie FinOps.
👉 Préparer la SnowPro Core sur DataCertification.fr
Pour aller plus loin sur Snowflake en général, j'ai regroupé tous mes articles dans un parcours complet.
👉 Accéder à la Formation Snowflake
Tu veux que je t'accompagne sur l'optimisation de ta facture Snowflake (audit, tagging, gouvernance, dashboard FinOps) ?
👉 Réserver un appel de 30 minutes
Questions
Comment réduire la facture Snowflake ?
Trois leviers à activer dans l'ordre : (1) visualiser ce qui consomme avec QUERY_ATTRIBUTION_HISTORY et WAREHOUSE_METERING_HISTORY, (2) poser des garde-fous avec Resource Monitors et Budgets, (3) optimiser auto-suspend, séparer les warehouses BI/ETL/Data Science et exploiter le result cache. La majorité des économies vient du compute mal piloté, pas du storage.
Comment Snowflake facture-t-il le compute ?"
Snowflake facture le compute à la seconde, mais avec un minimum de 60 secondes facturées à chaque démarrage ou reprise d'un warehouse. Donc un warehouse qui démarre 10 fois pour des requêtes de 10 secondes coûtera 600 secondes facturées, pas 100. C'est pour ça qu'un auto-suspend trop court peut faire exploser la facture.
Comment trouver les requêtes Snowflake les plus chères ?
Utilise la vue QUERY_ATTRIBUTION_HISTORY dans le schéma SNOWFLAKE.ACCOUNT_USAGE. Elle attribue un coût en crédits à chaque requête exécutée sur un warehouse. Tu peux trier par credits_attributed_compute pour obtenir le top des requêtes les plus coûteuses sur une période donnée.
Quelle valeur d'auto-suspend choisir sur Snowflake ?
Selon les recommandations Snowflake : suspension immédiate pour les tasks, environ 5 minutes pour DevOps, DataOps et Data Science, au moins 10 minutes pour les warehouses BI pour conserver le cache. Chaque démarrage facture un minimum de 60 secondes, donc trop court fait l'effet inverse en multipliant les démarrages.
Quelle différence entre Resource Monitor et Budget Snowflake ?
Le Resource Monitor est attaché à un warehouse ou un compte et peut suspendre automatiquement quand un seuil est atteint. Le Budget est plus orienté pilotage car il surveille la consommation avec des notifications par email mais ne suspend pas automatiquement. Le Budget supporte aussi le tagging pour attribuer les coûts à des équipes ou projets.
Comment détecter les anomalies de coût sur Snowflake ?
Snowflake propose une fonctionnalité Cost Anomalies qui détecte les pics ou creux de consommation quotidienne par rapport à l'historique. Deux prérequis : avoir au moins 30 jours d'historique, et une consommation supérieure à 10 crédits sur les 7 derniers jours. L'activation se fait avec SNOWFLAKE.LOCAL.ANOMALY_INSIGHTS!SET_ACCOUNT_NOTIFICATION_EMAILS.
Pourquoi mon warehouse consomme des crédits alors qu'il est inactif ?
Un warehouse consomme des crédits tant qu'il tourne, même sans requête en cours. Ce coût idle vient souvent d'un auto-suspend mal réglé, d'un warehouse partagé entre plusieurs équipes, ou de petites requêtes très fréquentes qui le réveillent en permanence. Pour le mesurer, calcule la différence entre credits_used_compute et credits_attributed_compute_queries dans WAREHOUSE_METERING_HISTORY.
Pourquoi le storage Snowflake gonfle-t-il en silence ?
Le storage Snowflake peut gonfler à cause de la rétention Time Travel (jusqu'à 90 jours sur l'édition Enterprise) et des fichiers Fail-safe (7 jours supplémentaires). Si tu fais beaucoup d'UPDATE ou MERGE sur de gros volumes, chaque opération crée de nouvelles micro-partitions et conserve les anciennes pendant la durée de rétention donc la solution est d'ajuster DATA_RETENTION_TIME_IN_DAYS sur les tables non critiques.
Comment activer le Result Cache Snowflake ?
Le Result Cache est activé par défaut dans Snowflake. Il conserve les résultats pendant 24 heures. Si une requête identique est relancée et que rien n'a changé, Snowflake renvoie le résultat sans recalculer mais attention car la moindre différence de syntaxe (espace, casse, alias) casse le cache.
Combien coûte un Virtual Warehouse Snowflake ?
Le coût d'un Virtual Warehouse dépend de sa taille et de sa durée d'utilisation. Les crédits consommés par heure doublent à chaque palier donc X-Small consomme 1 crédit par heure, Small 2, Medium 4, Large 8, X-Large 16, et ainsi de suite jusqu'à 6X-Large à 512 crédits par heure. Le prix du crédit dépend de l'édition (Standard, Enterprise, Business Critical) et du cloud provider.
Pourquoi utiliser des tags pour le FinOps Snowflake ?
Les tags permettent d'attribuer les coûts à des dimensions métier (équipe, projet, environnement, application) au-delà de la simple attribution par warehouse. Sans tags, tu sais quel warehouse consomme mais pas forcément qui est derrière. Avec les tags, tu peux faire des revues mensuelles par équipe, créer des budgets par projet, et responsabiliser les utilisateurs sur leur consommation.