
Si tu t'intéresses un peu au monde de la data, tu as forcément déjà vu passer le nom Snowflake. Entre les offres d'emploi, les posts LinkedIn et les slides de consultants, on te parle de "data cloud", de "modern data stack", de plateforme scalable, de séparation stockage et compute… Bref, beaucoup de buzz, pas toujours beaucoup de concret.
Moi aussi, au début, je me suis demandé :
“ OK, mais Snowflake, c'est quoi exactement ?
En quoi c'est différent d'un data warehouse classique ?
”
C'est précisément ce qu'on va voir ensemble dans cet article. On va laisser de côté le marketing pour regarder comment Snowflake fonctionne vraiment. Son architecture, la séparation stockage et compute, le modèle de consommation, et surtout la problématique réelle à laquelle il répond.
Si tu es plutôt team Spark/Databricks, tu verras qu'il y a énormément de points en communs (séparation stockage / compute / services, pay-as-you-go, scalabilité), mais aussi un positionnement un peu différent. Ici, on se concentre sur Snowflake, avec un objectif simple et que à la fin de l'article, tu saches quand, pourquoi et comment l'utiliser et on verra la différence avec databricks dans un autre article.
Snowflake en une phrase
Une plateforme data 100 % cloud, multi-cluster, avec données partagées et managées, qui sépare le stockage, le calcul et les services, et qui te laisse scaler sans gérer de serveurs.
C'est bon, si tu as compris cela, tu peux arrêter de lire l'article car ça couvre 80 % de ce qu'il faut savoir.
Mais sans blague, le point clé, c'est vraiment la séparation du stockage, du calcul et des services. Si tu comprends ça, tu as déjà une grosse partie de la vision.
Pour bien voir pourquoi c'est puissant, il faut d'abord comprendre le problème que ce type de plateforme cherche à résoudre.
Architecture traditionnelle vs architecture Snowflake
Avant de zoomer sur les différentes couches de l'architecture Snowflake, on va faire un pas en arrière et regarder les deux grands types d'architectures qu'on retrouve dans les bases de données “classiques”.
Shared-Disk (mono-cluster)
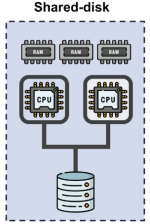
La plupart des bases de données historiques utilisent une architecture shared-disk où plusieurs processus partagent le même disque. Pour scaler, il faut faire du vertical scaling et c'est tout simplement en ajoutant du CPU, de la RAM, du disque… mais dans la même machine.
Sauf qu'on ne peut pas pousser ça à l'infini. À un moment, tu touches la limite physique du serveur, les coûts explosent, et tu te retrouves coincé avec un gros colosse difficile à faire évoluer.
Shared-Nothing
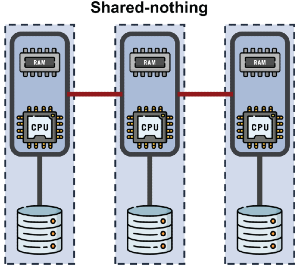
Dans une architecture shared-nothing, chaque nœud (serveur) a son compute et sa part de données. Parfait pour le parallélisme massif où chaque serveur traite sa portion de données en parallèle.
Par contre, ici, stockage et compute scalent ensemble. Tu veux plus de CPU ? Tu ajoutes de nouveau serveur… donc aussi du stockage, même si tu n'en as pas vraiment besoin. Tu veux juste plus de stockage ? Tu ajoutes aussi du compute.
Résultat => tu paies souvent pour une dimension dont tu n'as pas besoin, juste parce que les deux sont liés.
Snowflake : une architecture hybride

Après avoir vu les deux visions, Snowflake essaie clairement de garder le meilleur des deux mondes.
Les données sont partagées et centralisées comme dans un shared-disk donc tout est stocké sur le cloud storage (S3 / Azure Blob / GCS), peu cher et quasiment infini. Le calcul est réparti sur plusieurs moteurs indépendants comme dans un shared-nothing : ce sont les virtual warehouses.
Tu peux lancer 1, 2, 10, 200 warehouses, chacun pour un usage différent (BI, ELT, data science…), et tout le monde travaille sur la même donnée. Pas de copies partout, pas de clusters qui se marchent dessus.
Avec cette architecture, tu peux scaler le stockage et le calcul indépendamment, tout en gardant le contrôle de façon centralisée grâce à la couche Cloud Services (sécurité, métadonnées, gestion des sessions, etc.).
Si cette vision d'architecture hybride est claire, on peut maintenant descendre d'un niveau et regarder plus en détail les 3 principales couches qui composent Snowflake et comment elles interagissent.
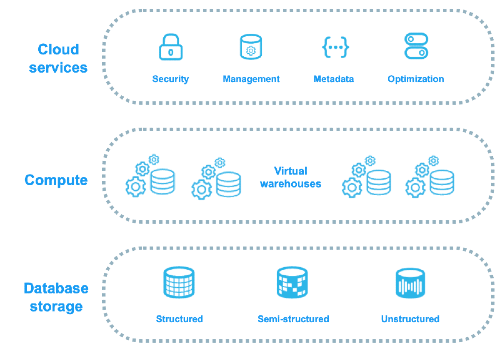
Les 3 couches de l'architecture Snowflake
Maintenant qu'on a la vue globale de l'architecture hybride de snowflake, on peut rentrer dans le détail de ce qui fait vraiment tourner Snowflake.
La plateforme est organisée autour de trois grandes couches : le stockage, le compute (les virtual warehouses) et la couche Cloud Services.
Chaque couche a un rôle bien précis :
- Storage : où et comment les données sont stockées et organisées ?
- Compute : comment les requêtes sont exécutées et les données traitées ?
- Cloud Services : comment l'ensemble est piloté, sécurisé et optimisé ?
Si tu gardes ce modèle en tête pendant la suite (stockage / compute / services), tu verras que toute la logique de Snowflake devient beaucoup plus simple à comprendre.
Le storage
Le virage vers des plateformes comme Snowflake n'a été possible que parce que le stockage objet dans le cloud est devenu très peu cher. Snowflake en profite à fond en s'appuyant sur les gros cloud providers (AWS, Azure, GCP) et en imposant sa propre façon d'organiser tes données via les micro-partitions.
Snowflake peut gérer des données structurées (tables relationnelles classiques), semi-structurées (JSON, Avro, Parquet, etc.) et même non structurées à travers des fichiers stockés dans des stages et référencés via le type FILE.
Mais s'il y a une notion à retenir côté storage, c'est clairement celle des micro-partitions.
Quand tu charges des données dans une table, Snowflake les stocke dans un format colonnaire compressé et les découpe automatiquement en petits blocs contigus : les micro-partitions.
Pour chaque micro-partition, Snowflake garde des métadonnées (valeurs min / max par colonne, nombre de lignes, etc.). Tu peux imaginer ta table comme une grille de petits blocs, chacun avec une fiche d'identité ultra concise.
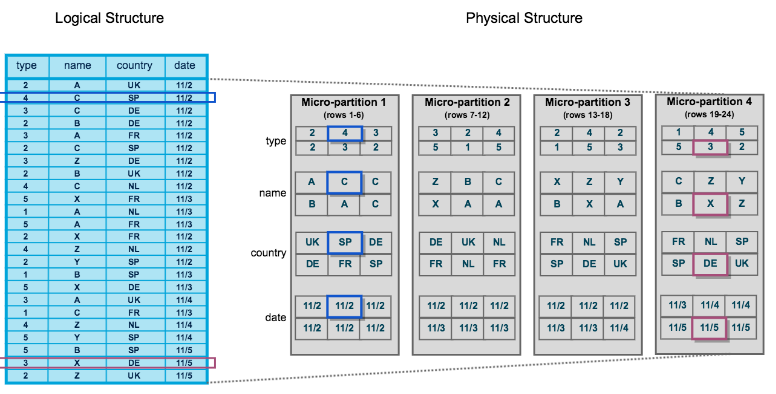
Grâce à ça, le moteur d'exécution peut lire uniquement les blocs pertinents pour une requête donnée au lieu de tout balayer. Résultat : des temps de réponse plus rapides et un coût réduit, parce qu'il y a moins de données scannées.
Ce mécanisme sert aussi de fondation à des fonctionnalités comme Time Travel (remonter dans le temps sur tes données) et Zero-Copy Clone (cloner tables, schémas ou bases sans dupliquer physiquement les données). On pourrait y consacrer un article à part, mais pour l'instant retiens surtout que les micro-partitions, c'est le cœur du storage Snowflake.
En plus des tables “classiques”, Snowflake propose aussi des Iceberg tables, où les données restent dans ton propre stockage au format Iceberg et Snowflake se contente de les lire, et des Hybrid tables, pensées pour des besoins plus transactionnels, plus proches de petits workloads OLTP.
Inscris-toi pour recevoir les prochains articles par email.
Le compute
Si tu as bien suivi jusqu'à là, le deuxième pilier qui fait la puissance de Snowflake, c'est le compute et sa capacité à scaler dans tous les sens. Et là, tout tourne autour d'un concept " les virtual warehouses."
Un virtual warehouse, c'est tout simplement un groupe de serveurs que Snowflake met à ta disposition pour exécuter tes requêtes. Tu l'allumes, il consomme des crédits. Tu le suspends, le compteur s'arrête. Les données, elles, restent posées tranquillement dans le storage, partagées pour tout le monde.
Snowflake a choisi de classer les warehouses avec une logique très simple, façon t-shirt : X-Small, Small, Medium, Large, X-Large, 2X-Large, 3X-Large, 4X-Large etc...
On démarre avec un X-Small. Ensuite, à chaque taille au-dessus, on a deux fois plus de capacité de calcul donc un Small = deux fois plus qu'un X-Small, un Medium = quatre fois plus, un Large = huit fois plus, etc..
Même logique pour la consommation de crédits : 1 crédit/heure pour un X-Small, 2 pour un Small, 4 pour un Medium… jusqu'à 512 crédits/heure pour un 6X-Large.
Tu doubles la taille, tu doubles la puissance… et la facture. Rien de magique, mais au moins c'est lisible et prédictible.
Si tu veux retenir un truc sur le compute :
les virtual warehouses sont indépendants du storage, tu peux en avoir autant que tu veux, et tu payes uniquement quand ils tournent.
Comment Snowflake facture le compute ?
Le compute est facturé en crédits. Tu es facturé sur trois choses :
1 - combien de warehouses tu utilises,
2- leur taille,
3- et combien de temps ils tournent.
Snowflake facture le compute à la seconde, avec un minimum d'une minute. Tant qu'un warehouse est en marche, il consomme des crédits. Quand tu le suspends (ou qu'il s'auto-suspend si tu l'as configuré), le compteur s'arrête.
Moralité : allumer un gros warehouse pour une courte période peut être plus rentable que de laisser un petit warehouse tourner pendant des heures à la traîne.
Bien organiser ses warehouses : le vrai jeu
Une fois que tu as compris comment ça facture, le vrai jeu, ce n'est pas de connaître tous les paramètres par cœur, c'est de bien organiser tes warehouses.
L'idée de base est simple : tout le monde n'a pas besoin du même moteur de calcul. Tu n'as pas envie que ton gros job d'ETL du matin vienne plomber les dashboards des analystes ou les notebooks des data scientists. Donc tu découpes : un warehouse pour l'ETL / ELT, un autre pour la BI, éventuellement un dédié au chargement continu ou au rechargement des données des dashboards (Qlik sense, power bi etc...) . Chacun a sa taille, son auto-suspend, sa petite vie.
Pour aller plus loin, Snowflake te laisse jouer sur deux tableaux : muscler un warehouse ou déployer une petite armée de clusters.
- Quand les requêtes sont lourdes mais pas si nombreuses, tu joues la carte scale up. Tu passes de Medium à Large, puis de Large à X-Large, juste le temps de faire ton job. Tu profites de plus de CPU / RAM / SSD sur un seul cluster, tu laisses tourner, puis tu comptes sur l'auto-suspend pour couper proprement une fois que c'est terminé. C'est le mode “bulldozer” : un seul engin, mais costaud.
- Quand le problème, ce n'est pas la complexité des requêtes mais le nombre de personnes qui tirent en même temps (beaucoup d'utilisateurs sur Qlik Sense, Power BI, etc.), là tu passes en mode scale out avec les Multi-Cluster Warehouses. Côté utilisateur, tout le monde voit un seul warehouse, mais derrière Snowflake ouvre plusieurs clusters identiques, répartit les requêtes entre eux, puis les ferme tout seul quand la pression retombe. Tu gardes le même nom de warehouse, la même taille, juste plus de copies en parallèle pendant le rush.
Au final, pour scaler, on s'appuie principalement sur trois leviers :
- la taille du warehouse → scale up,
- le nombre de clusters derrière → scale out,
- et le temps pendant lequel tu les laisses tourner → suspend / auto-suspend.
Cloud Services
Après le storage et le compute, il manque encore une pièce pour faire une vraie plateforme. Tout ce qui gère la sécurité, les métadonnées, l'optimisation et la gouvernance. C'est exactement le rôle de la couche Cloud Services.
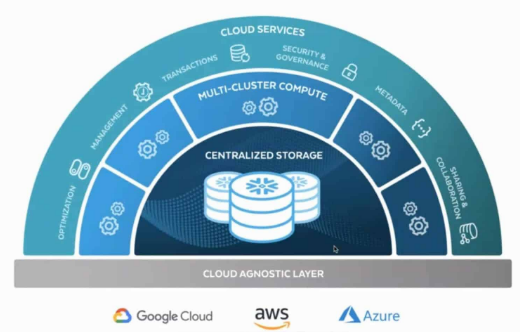
C'est elle qui gère tout ce qui fait qu'une plateforme data est utilisable en vrai, pas juste “un cluster qui tourne dans un coin” :
- Sécurité & gouvernance : authentification, rôles, privilèges, masquage de données, policies, gestion fine de qui voit quoi.
- Métadonnées & catalogue : définition des objets (tables, vues, stages, etc.), schémas, stats, micro-partitions, tout ce qui permet au moteur de savoir où aller chercher l'info.
- Optimisation des requêtes : parsing SQL, plan d'exécution, réécriture, choix des micro-partitions à scanner, gestion du cache.
- Gestion des sessions & des transactions : contrôle de la concurrence, isolation, reprise après incident, time travel, clones, etc.
- Fonctionnalités plateforme : data sharing, marketplace, replication, failover, tasks, streams…
L'info importante à garder en tête à propos de la couche Cloud Services, c'est qu'elle est partagée par tous les warehouses d'un même compte Snowflake.
Ce n'est pas un “gros warehouse central”, mais une couche de contrôle qui orchestre le reste : elle décide comment exécuter une requête, sur quel compute, sur quelles données, et applique la sécurité au passage.
C'est aussi grâce à elle que tu peux :
- créer un nouveau warehouse sans te soucier de la façon dont il accède aux données,
- partager un dataset avec un autre compte Snowflake sans faire de copie,
- restaurer l'état d'une table à un instant T via le Time Travel,
- cloner une base entière en quelques secondes sans exploser ton stockage.
J'espère qu'à ce stade, tu as une vision globale de comment Snowflake fonctionne, où se situe vraiment sa puissance et surtout quelle problématique il vient résoudre.
On rentrera plus en détail dans de prochains articles, donc n'hésite pas à t'abonner à la newsletter pour recevoir la suite.
Inscris-toi pour recevoir les prochains articles par email.
Récap. des 3 couches
| Couche | Rôle | Composants clés | Facturation |
|---|---|---|---|
| Storage | Stocke les données en format colonnaire compressé sur le cloud (S3, Azure, GCS) | Micro-partitions, métadonnées (min/max, row count), Time Travel, Fail-safe | Au volume de données stocké par mois |
| Compute | Exécute les requêtes via des virtual warehouses indépendants | Virtual warehouses (XS à 6X-Large), multi-cluster, auto-suspend, scale up/out | En crédits, à la seconde (min 60s par démarrage) |
| Cloud Services | Pilote la plateforme : sécurité, métadonnées, optimisation, gouvernance | Authentification, RBAC, query planner, cache, data sharing, replication | Gratuit tant que < 10% du compute quotidien |
La règle clé à retenir : les 3 couches sont découplées. Tu peux scaler le storage sans toucher au compute, multiplier les warehouses sans dupliquer les données, et la couche Cloud Services s'occupe d'orchestrer tout ça automatiquement.
Aller plus loin : Formation Snowflake
J'ai regroupé tous mes articles Snowflake dans un parcours complet.
👉 Accéder à la Formation Snowflake
Tu prépares la certification SnowPro ? Entraîne-toi avec 700+ questions d'examens blancs chronométrés, corrections détaillées et suivi de progression.
👉 S'entraîner sur DataCertification.fr
Tu veux que je t'accompagne sur ton projet data (Snowflake, ingestion, modélisation, performance, coûts, gouvernance) ?
👉 Réserver un appel de 30 minutes
Questions
Quelles sont les 3 couches de l'architecture Snowflake ?
Snowflake repose sur 3 couches découplées : le Storage (données en format colonnaire compressé dans le cloud, découpées en micro-partitions de 50 à 500 MB), le Compute (virtual warehouses indépendants pour exécuter les requêtes) et le Cloud Services (orchestration : authentification, optimisation, métadonnées, contrôle d'accès). Tu peux scaler ces 3 couches indépendamment.
Quelle différence entre architecture Snowflake et data warehouse classique ?
Un data warehouse classique utilise une architecture shared-disk (un seul gros serveur) ou shared-nothing (plusieurs serveurs avec leurs données). Dans les deux cas, le stockage et le compute scalent ensemble : impossible d'augmenter l'un sans l'autre. Snowflake adopte une approche hybride : les données sont centralisées dans le cloud storage (S3/Azure/GCS), et plusieurs virtual warehouses indépendants peuvent les requêter en parallèle. Tu scales storage et compute séparément.
C'est quoi une micro-partition dans Snowflake ?
Une micro-partition est un bloc de stockage contigu de 50 à 500 MB compressés, créé automatiquement par Snowflake quand tu charges des données. Snowflake conserve pour chaque micro-partition des métadonnées (valeurs min/max par colonne, nombre de lignes), ce qui permet le pruning donc le moteur ne lit que les blocs pertinents pour une requête au lieu de tout balayer. Les micro-partitions sont immutables ce qui veut dire qu'un UPDATE crée une nouvelle micro-partition.
C'est quoi un virtual warehouse Snowflake ?
Un virtual warehouse est un groupe de serveurs que Snowflake met à disposition pour exécuter les requêtes. Il consomme des crédits quand il tourne et s'arrête quand on le suspend (ou avec l'auto-suspend). Les warehouses sont indépendants : tu peux en avoir autant que tu veux pour différents usages (ETL, BI, data science), tous lisant les mêmes données. Les tailles vont de X-Small (1 crédit/h) à 6X-Large (512 crédits/h), avec doublement de capacité et de coût à chaque palier.
Quelle est la différence entre scale up et scale out dans Snowflake ?
Scale up consiste à augmenter la taille du warehouse (de X-Small à 6X-Large) pour accélérer une requête individuelle. Scale out consiste à activer le multi-cluster warehouse pour gérer plus de requêtes en parallèle. Pour des requêtes lourdes mais peu nombreuses, scale up. Pour beaucoup d'utilisateurs simultanés sur des dashboards, scale out.
Comment Snowflake facture-t-il le compute ?
Snowflake facture le compute en crédits, à la seconde, avec un minimum d'une minute par démarrage de warehouse. Le coût dépend de trois facteurs : combien de warehouses tu utilises, leur taille (1 crédit/h pour X-Small, 2 pour Small, 4 pour Medium, jusqu'à 512 pour 6X-Large), et combien de temps ils tournent. Un gros warehouse pendant 2 minutes coûte souvent moins qu'un petit warehouse pendant 30 minutes pour le même calcul.
Qu'est-ce que la couche Cloud Services dans Snowflake ?
Le Cloud Services layer est le cerveau de Snowflake. Il gère l'authentification, les rôles et privilèges, les métadonnées des objets, l'optimisation des requêtes (parsing SQL, plan d'exécution, choix des micro-partitions), le cache, les sessions et transactions, et les fonctionnalités plateforme (data sharing, replication, Time Travel, tasks, streams). Cette couche est partagée par tous les warehouses d'un même compte. Elle est gratuite tant qu'elle représente moins de 10% du compute quotidien.
Quels types de données Snowflake peut-il gérer ?
Snowflake gère trois types : structuré (tables relationnelles classiques), semi-structuré (JSON, Avro, Parquet, XML via le type VARIANT et la fonction FLATTEN) et non structuré (PDF, images, audio via les stages et les directory tables avec le type FILE). Cette couverture étendue fait que Snowflake n'est plus seulement un data warehouse, mais une plateforme data complète. Les formats Iceberg et Hybrid tables sont aussi supportés pour des cas d'usage spécifiques.
Sur quel cloud Snowflake fonctionne-t-il ?
Snowflake est nativement disponible sur les trois principaux cloud providers : AWS (S3), Microsoft Azure (Azure Blob) et Google Cloud Platform (GCP). Tu choisis le cloud et la région au moment de créer ton compte. Tu peux aussi configurer la replication entre régions ou clouds pour la haute disponibilité ou le data sharing cross-cloud.
Pourquoi Snowflake est-il plus rapide qu'un data warehouse classique ?
Trois raisons principales : Le pruning des micro-partitions évite de scanner les données non pertinentes pour une requête, le format colonnaire compressé réduit la quantité de données lues, et le scale out via multi-cluster permet de paralléliser massivement sur des requêtes lourdes. Le cache à 3 niveaux (metadata, result, warehouse) accélère aussi les requêtes répétées. Et la séparation storage/compute permet d'allouer la puissance exactement quand on en a besoin.