
Dans les 2 derniers articles, on a vu comment :
- Les streams répondent à “qu'est-ce qui a changé depuis la dernière fois ?”,
- Les tasks décident “quand on exécute le SQL qui consomme ces changements”.
Donc avec Streams + Tasks, on sait construire un pipeline incrémental, mais c'est encore à nous d'orchestrer la mécanique.
Les Dynamic Tables arrivent avec une autre approche :
“Décris-moi le résultat que tu veux (un SELECT) et je m'occupe de le garder à jour pour toi, de manière incrémentale.”
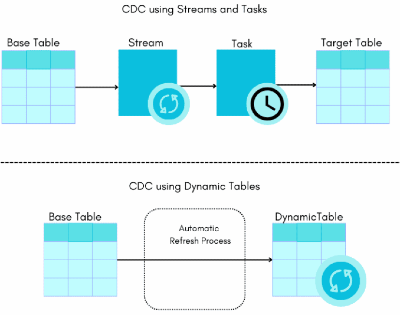
C'est quoi concrètement une Dynamic Table ?
Une Dynamic Table, c’est une table gérée par Snowflake à partir d'un SELECT.
L'idée, c'est d'écrire juste la requête qui décrit le résultat final, et Snowflake s'occupe du reste :
- Matérialise ce résultat dans une table physique,
- Et le maintient à jour automatiquement en se basant sur les changements des sources.
On ne fait pas de INSERT ou UPDATE direct sur une Dynamic Table.
Il faut le voir plutôt comme un modèle (un peu comme une vue matérialisée ++) que Snowflake alimente en continu.
La définition ressemble à :
CREATE OR REPLACE DYNAMIC TABLE members_daily
TARGET_LAG = '5 MINUTE'
WAREHOUSE = COMPUTE_WH
AS
SELECT
id,
name,
age,
DATE_TRUNC('day', created_at) AS day
FROM members;
On lui donne :
- Une requête
AS SELECT ...qui décrit ce qu'on veut, - Un
TARGET_LAGqui fixe l'objectif de rafraîchissement des données, en mode “je veux que cette table ait au plus X minutes de retard par rapport aux sources”, - Et un compute (warehouse ou mode géré) pour faire tourner les refresh.
Ensuite, on peut requêter members_daily comme une table normale :
SELECT *
FROM members_daily
WHERE day >= CURRENT_DATE - 7;
Snowflake, lui, s'occupe de la garder à jour.
Et surtout, il le fait de manière incrémentale, en ne recalculant que ce qui est nécessaire.
Différence avec une vue ou une vue matérialisée
On peut se demander : “OK, mais en quoi c'est différent d'une view ou d'une materialized view ?”
- Une view classique ne stocke rien. À chaque requête, Snowflake ré-exécute tout le
SELECTsur les tables sources. C'est juste une couche logique. - Une materialized view stocke le résultat et le met à jour automatiquement, mais avec pas mal de limitations sur le SQL, et sans vraie notion de pipeline en plusieurs étapes.
- Une Dynamic Table est pensée dès le départ pour faire des pipelines de modèles : elle peut lire d'autres Dynamic Tables, exprimer un objectif de fraîcheur, et Snowflake se sert de ça pour orchestrer les rafraîchissements dans le bon ordre.
Tu peux en empiler plusieurs et Snowflake va comprendre tout seul ce qui dépend de quoi, et ce qu'il faut rafraîchir d'abord, et comment faire tout ça de manière incrémentale.
Là où une view est juste un SELECT bête et une materialized view un “cache plus ou moins intelligent”, une Dynamic Table se positionne plus comme une brique de pipeline déclarative.
Exemple d'un pipeline avec Dynamic Tables
Prenons un exemple simple.
On a des événements bruts dans une table events_raw et on veut :
- les nettoyer en supprimant les événements qui n'ont pas de time, puis stocker ça dans la table
events_clean - ensuite calculer le nb d'events quotidiens par utilisateur
Avec Streams + Tasks, on ferait : table → stream → table intermédiaire → task → autre table, etc...
Avec des Dynamic Tables, on peut exprimer ça comme une suite de modèles :
CREATE OR REPLACE DYNAMIC TABLE events_clean
TARGET_LAG = '10 MINUTE'
WAREHOUSE = COMPUTE_WH
AS
SELECT
event_id,
user_id,
TRY_TO_TIMESTAMP(event_time) AS event_time,
event_type,
payload
FROM events_raw
WHERE event_time IS NOT NULL;
Puis une deuxième Dynamic Table qui se base sur la première :
CREATE OR REPLACE DYNAMIC TABLE events_daily_agg
TARGET_LAG = '15 MINUTE'
WAREHOUSE = COMPUTE_WH
AS
SELECT
user_id,
DATE_TRUNC('day', event_time) AS day,
COUNT(*) AS nb_events
FROM events_clean
GROUP BY user_id, day;
Ce qui est intéressant ici :
events_daily_aggdépend deevents_clean,events_cleandépend deevents_raw,- et on ne gère aucune Task pour dire “rafraîchis d'abord ça, puis ça”.
Snowflake construit un graphe de dépendances, et se débrouille pour rafraîchir les Dynamic Tables dans le bon ordre, en respectant les TARGET_LAG que tu as définis. Et oui c'est magique.
Comment penser TARGET_LAG pour le rafraîchissement des données
Le paramètre TARGET_LAG est central dans les Dynamic Tables.
C'est lui qui fixe la fréquence de rafraîchissement des données dans les tables dynamique.
- Si tu mets un lag très court (genre
'1 MINUTE'), tu demandes à Snowflake de rafraîchir très souvent et donc la table sera quasi temps réel, mais tu consommeras plus de compute et cela peut faire mal à la facture. - Si tu mets un lag plus large (
'30 MINUTE','1 HOUR'…), tu acceptes un peu de retard, mais tu réduis la fréquence des refresh.
Parce que derrière, à chaque refresh, Snowflake lit les changements des sources, calcule ce qu'il faut, met à jour la Dynamic Table.
Donc TARGET_LAG, c'est un vrai curseur coût / rafraîchissement des données, qu'il faut bien dimensionner en fonction des besoins.
Dynamic Tables vs Streams + Tasks
La question qu'on finit toujours par se poser, et que je me suis aussi posée quand j'ai vu les Dynamic Tables, c'est:
“Bon, je fais ça avec Dynamic Tables, ou je reste avec mon combo Streams + Tasks ?”
Pour faire simple :
- Avec Streams + Tasks, on construit toute la mécanique à la main donc on déclare les streams, on écrit les
MERGE, on planifie les Tasks, on gère les dépendances. Au final, on garde un contrôle très fin sur ce qui se passe à chaque étape. - Avec les Dynamic Tables, on monte d'un niveau et on mise sur la simplicité. On décrit juste “voilà le modèle que je veux” via un
SELECT, on règle leTARGET_LAG, et Snowflake se charge de l'incrémental et du scheduling pour nous.
Par défaut, si ton pipeline est 100 % Snowflake et surtout une suite de transformations SQL, les Dynamic Tables sont souvent l'option la plus simple. Sinon, ou si tu as besoin de plus de contrôle et d'intégrations externes l'option Streams + Tasks reste plus adaptée.
Limitations à connaître
Avant de tout migrer en Dynamic Tables, il faut connaître quelques contraintes :
- Pas tous les SQL supportés : certaines fonctions non déterministes comme
CURRENT_TIMESTAMP(),RANDOM()ouUUID_STRING()posent problème dans le refresh incrémental. Snowflake bascule alors en mode "FULL REFRESH" qui recalcule tout, ce qui peut coûter cher. - Les sources doivent être identifiables : Snowflake doit pouvoir tracker les changements des sources. Les vues, les external tables avec auto-refresh et les tables avec change tracking activé fonctionnent. Les UDF non déterministes peuvent forcer un FULL REFRESH.
- TARGET_LAG minimum : 1 minute, comme pour les Tasks. Pour du quasi-temps réel sous la minute, regarde du côté de Snowpipe Streaming.
- Édition Enterprise minimum : non disponible en Standard.
- Coût à anticiper : un TARGET_LAG très court (1-5 minutes) sur une grosse Dynamic Table peut consommer beaucoup de compute. Surveille la consommation via
INFORMATION_SCHEMA.DYNAMIC_TABLE_REFRESH_HISTORY.
Pour vérifier qu'une Dynamic Table fait bien du refresh incrémental (et non FULL), tu peux interroger :
SELECT name, target_lag_type, refresh_mode, last_completed_refresh_state
FROM TABLE(INFORMATION_SCHEMA.DYNAMIC_TABLE_REFRESH_HISTORY(
NAME => 'events_clean'
));
Si refresh_mode retourne FULL, ta Dynamic Table recalcule tout à chaque refresh et tu perds le bénéfice incrémental.
Aller plus loin : préparer la SnowPro Core
Les Dynamic Tables sont une feature relativement récente de Snowflake, mais déjà testée à l'examen SnowPro Core (surtout sur les notions de TARGET_LAG et le mode déclaratif). Sur DataCertification.fr, le module SnowPro Core couvre les pipelines incrémentaux dans leur ensemble (Streams, Tasks, Dynamic Tables, Snowpipe) avec 700 questions scenario-based au format de l'examen.
👉 Préparer la SnowPro Core sur DataCertification.fr
Pour aller plus loin sur Snowflake en général, j'ai regroupé tous mes articles dans un parcours complet.
👉 Accéder à la Formation Snowflake
Tu veux que je t'accompagne sur ton projet data (Snowflake, pipelines déclaratifs avec Dynamic Tables, dbt, FinOps refresh) ?
👉 Réserver un appel de 30 minutes
Questions
C'est quoi une Dynamic Table dans Snowflake ?
Une Dynamic Table est une table gérée par Snowflake à partir d'un SELECT. Tu décris le résultat final, et Snowflake matérialise ce résultat et le maintient à jour automatiquement de manière incrémentale selon le TARGET_LAG que tu définis. C'est un mode déclaratif : on ne fait pas d'INSERT ou UPDATE direct, Snowflake gère le rafraîchissement et l'ordre des dépendances entre Dynamic Tables.
À quoi sert TARGET_LAG dans une Dynamic Table ?
TARGET_LAG définit le retard maximum acceptable entre les données sources et la Dynamic Table. Par exemple TARGET_LAG = '5 MINUTE' signifie que Snowflake garantit un rafraîchissement au moins toutes les 5 minutes. Un lag court coûte plus cher (refresh plus fréquent), un lag long est plus économique mais introduit une latence. Le minimum est 1 minute. C'est le curseur principal entre fraîcheur et coût.
Quelle différence entre Dynamic Table et Materialized View dans Snowflake ?
Une materialized view est limitée (une seule table source, pas de JOIN, pas de UNION, pas de sous-requêtes dans le FROM) et sert principalement à cacher un agrégat sur une table. Une Dynamic Table supporte un SQL bien plus riche (JOIN, UNION, window functions, agrégats complexes), peut chaîner plusieurs niveaux avec un graphe de dépendances automatique, et expose un objectif de fraîcheur via TARGET_LAG. Dynamic Table est pensée pour les pipelines, materialized view pour le cache.
Dynamic Tables ou Streams + Tasks : que choisir ?
Dynamic Tables si ton pipeline est 100% SQL et linéaire : tu décris le résultat, Snowflake gère l'orchestration. Plus simple à opérer en équipe. Streams + Tasks si tu as besoin d'un contrôle fin sur chaque étape, d'intégrations externes (stored procedures Python, appels API), ou de conditions custom complexes. La règle simple : commence par Dynamic Tables, passe à Streams + Tasks seulement si tu hits une limitation.
Quelle édition Snowflake est requise pour les Dynamic Tables ?
Les Dynamic Tables nécessitent l'édition Enterprise minimum. Elles ne sont pas disponibles en édition Standard. C'est une feature au même niveau que les materialized views, le multi-cluster warehouse ou le masquage dynamique. Pour les comptes Standard, il faut utiliser Streams + Tasks comme alternative.
Peut-on chaîner plusieurs Dynamic Tables ?
Oui, c'est même un des points forts. Tu peux créer une Dynamic Table qui lit une autre Dynamic Table dans son SELECT. Snowflake construit automatiquement le graphe de dépendances entre toutes tes Dynamic Tables et orchestre les rafraîchissements dans le bon ordre, en respectant les TARGET_LAG de chaque niveau. Tu n'as pas à gérer manuellement quel rafraîchissement déclenche quoi.
Comment vérifier qu'une Dynamic Table fait du refresh incrémental ?
Interroge INFORMATION_SCHEMA.DYNAMIC_TABLE_REFRESH_HISTORY pour vérifier la colonne refresh_mode. Si elle retourne INCREMENTAL, Snowflake ne recalcule que les changements (mode optimal). Si elle retourne FULL, Snowflake recalcule toute la table à chaque refresh, ce qui peut coûter cher. Les causes courantes de FULL : présence de fonctions non déterministes (CURRENT_TIMESTAMP, RANDOM), UDF complexes, certaines clauses SQL non supportées en incrémental.
Quelles sont les limitations des Dynamic Tables ?
Quatre limitations principales : (1) certaines fonctions non déterministes (CURRENT_TIMESTAMP, RANDOM, UUID_STRING) forcent un FULL REFRESH au lieu de l'incrémental, (2) TARGET_LAG minimum 1 minute (pour du sub-second, regarder Snowpipe Streaming), (3) édition Enterprise minimum, (4) le coût peut être significatif avec un lag court sur une grosse table. Toujours monitorer DYNAMIC_TABLE_REFRESH_HISTORY pour vérifier le mode de refresh.
Comment utiliser Dynamic Tables avec dbt ?
L'adapter dbt-snowflake supporte les Dynamic Tables via la matérialisation dynamic_table. Tu écris ton modèle dbt comme d'habitude avec un SELECT, et tu spécifies dans le config block : {{ config(materialized='dynamic_table', target_lag='5 minutes', snowflake_warehouse='compute_wh') }}. dbt prend en charge la création, le refresh et la gestion des dépendances. C'est l'option recommandée pour combiner gouvernance dbt et déclarativité Snowflake.
Combien coûte une Dynamic Table Snowflake ?
Une Dynamic Table coûte le stockage des données matérialisées (comme une table classique), le compute des refresh, qui peut être un warehouse classique ou un compute serverless. Le coût dépend principalement du TARGET_LAG (plus court = plus de refresh = plus de compute) et de la complexité du SQL. Pour optimiser : démarrer avec un TARGET_LAG large (15-30 min), monitorer la consommation, puis réduire si nécessaire.