
Dans la plupart des projets BI, tu vas toujours avoir besoin à un moment donner d'analyser des données par groupe (par client, par produit, par jour...), tout en gardant le même niveau de granularité. Souvent, on fait un GROUP BY puis on rejoint au détail, ou on passe par des sous-requêtes/CTE. Ça marche, mais ça peut vite devenir lourd à maintenir.
Les window fonctions sont là pour simplifier ça. Elles ne remplacent pas GROUP BY, elles le complètent. Tu gardes tes lignes, et tu ajoutes une colonne calculée autour de la ligne courante comme numéroter (ROW_NUMBER()), classer (RANK(), DENSE_RANK()), faire un cumul ou une moyenne (SUM() OVER, AVG() OVER), trouver un min/max (MIN(), MAX()), comparer avec la ligne d'avant ou d'après (LAG(), LEAD()), ou afficher la première/dernière valeur (FIRST_VALUE(), LAST_VALUE()).
La syntaxe est toujours la même, elle commence avec une fonction suivie d'un OVER(...). Dans OVER, tu peux découper tes données avec PARTITION BY , définir un ordre avec ORDER BY , et parfois préciser une fenêtre de calcul avec ROWS BETWEEN ... AND ... quand tu veux un cumul ou une moyenne ligne par ligne.
<fonction>() OVER (
PARTITION BY ...
ORDER BY ...
ROWS BETWEEN ... AND ...
)
Quelle window function pour quel besoin ?
| Besoin | Fonction | Exemple rapide |
|---|---|---|
| Numéroter les lignes d'un groupe | ROW_NUMBER() |
ROW_NUMBER() OVER (PARTITION BY client ORDER BY date) |
| Classer avec gestion des égalités | RANK() / DENSE_RANK() |
RANK() OVER (ORDER BY montant DESC) |
| Calculer un cumul / running total | SUM() OVER |
SUM(amount) OVER (PARTITION BY client ORDER BY date) |
| Calculer une moyenne mobile | AVG() OVER ... ROWS BETWEEN |
AVG(amount) OVER (ORDER BY date ROWS 2 PRECEDING) |
| Comparer avec ligne précédente | LAG() |
LAG(amount) OVER (PARTITION BY client ORDER BY date) |
| Comparer avec ligne suivante | LEAD() |
LEAD(amount) OVER (PARTITION BY client ORDER BY date) |
| Premier ou dernier d'un groupe | FIRST_VALUE() / LAST_VALUE() |
FIRST_VALUE(amount) OVER (PARTITION BY client ORDER BY date) |
| Filtrer le top-N par groupe | QUALIFY ROW_NUMBER() |
QUALIFY ROW_NUMBER() OVER (...) <= 3 |
Exemples
Comme dans les articles précédents, il n'y a pas mieux que des exemples concrets pour comprendre le concept et voir comment ça fonctionne.
USE DATABASE Demo_db;
USE SCHEMA demo;
--Créer une table de démo
CREATE OR REPLACE TABLE demo_orders (
order_id INTEGER,
customer_id INTEGER,
order_date DATE,
amount NUMBER(10,2),
channel VARCHAR
);
Insert (20 lignes) :
INSERT INTO demo_orders (order_id, customer_id, order_date, amount, channel) VALUES
(1001, 101, DATE '2025-01-03', 120.00, 'WEB'),
(1002, 101, DATE '2025-01-07', 80.00, 'STORE'),
(1003, 101, DATE '2025-01-10', 200.00, 'WEB'),
(1004, 101, DATE '2025-01-10', 50.00, 'WEB'),
(1005, 101, DATE '2025-02-02', 90.00, 'STORE'),
(1006, 101, DATE '2025-02-15', 300.00, 'WEB'),
(2001, 102, DATE '2025-01-05', 60.00, 'WEB'),
(2002, 102, DATE '2025-01-20', 400.00, 'STORE'),
(2003, 102, DATE '2025-02-01', 150.00, 'WEB'),
(2004, 102, DATE '2025-02-01', 75.00, 'STORE'),
(2005, 102, DATE '2025-03-12', 220.00, 'WEB'),
(3001, 103, DATE '2025-01-02', 500.00, 'STORE'),
(3002, 103, DATE '2025-01-18', 40.00, 'WEB'),
(3003, 103, DATE '2025-02-10', 120.00, 'WEB'),
(3004, 103, DATE '2025-02-28', 120.00, 'STORE'),
(3005, 103, DATE '2025-03-05', 90.00, 'WEB'),
(4001, 104, DATE '2025-01-11', 30.00, 'WEB'),
(4002, 104, DATE '2025-02-11', 35.00, 'WEB'),
(4003, 104, DATE '2025-03-01', 25.00, 'STORE'),
(4004, 104, DATE '2025-03-15', 60.00, 'STORE');
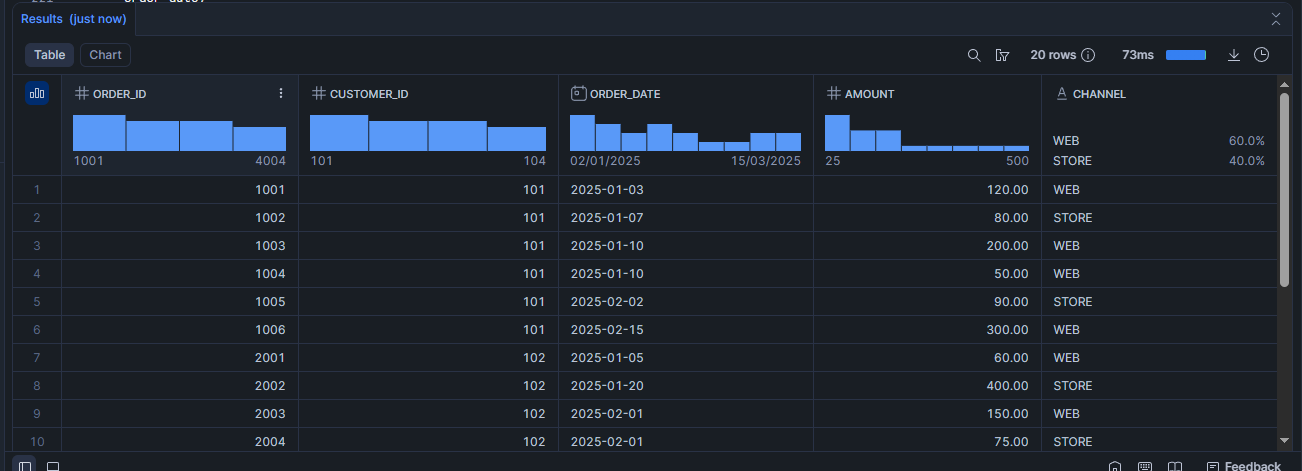
Voir le contenu de la table :
SELECT *
FROM demo_orders;
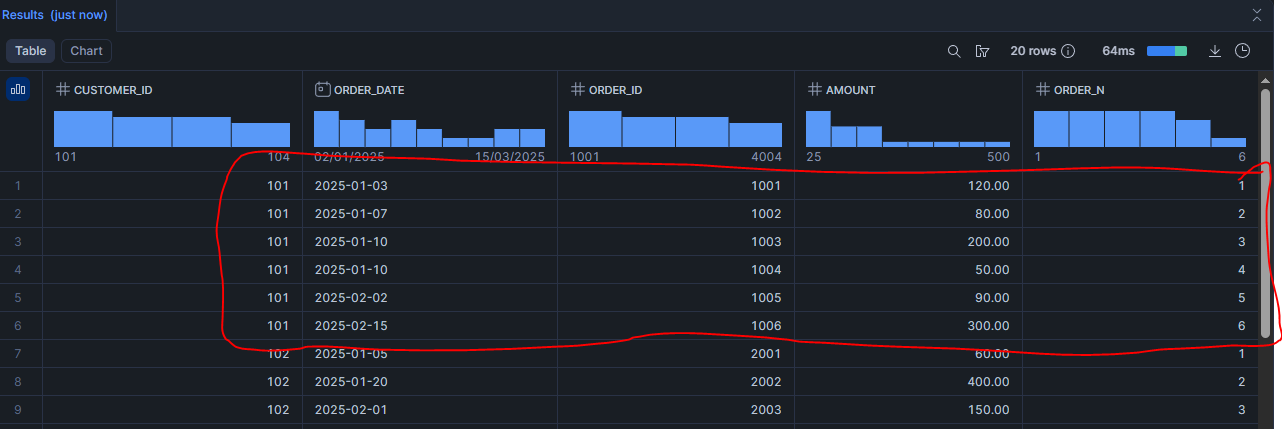
Scénario 1 : Numéroter les commandes d’un client (ROW_NUMBER)
SELECT
customer_id,
order_date,
order_id,
amount,
ROW_NUMBER() OVER (
PARTITION BY customer_id
ORDER BY order_date, order_id
) AS order_n
FROM demo_orders
ORDER BY customer_id, order_date, order_id;
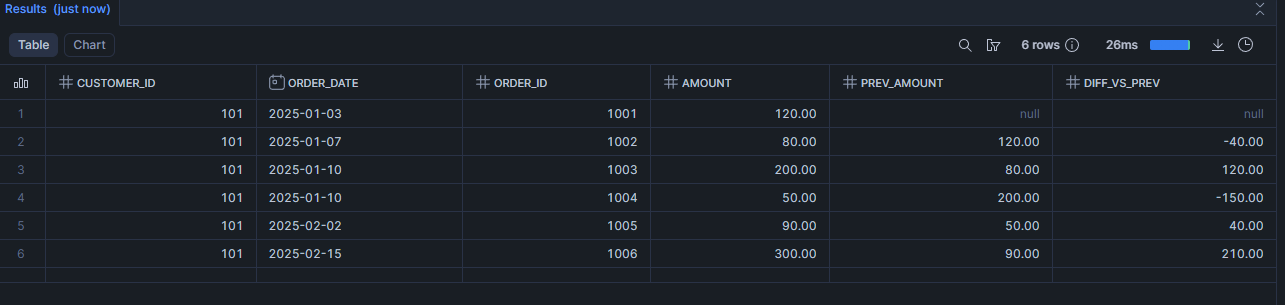
Scénario 2 : Mesurer l’évolution entre deux commandes (calculer la variation (LAG))
Concrètement dans ce use case, la fonction Lag va permettre de récupérer la valeur de la ligne précédente (du même client, dans l’ordre des dates), sans faire de self-join.
SELECT
customer_id,
order_date,
order_id,
amount,
LAG(amount) OVER (
PARTITION BY customer_id
ORDER BY order_date, order_id
) AS prev_amount,
amount - LAG(amount) OVER (
PARTITION BY customer_id
ORDER BY order_date, order_id
) AS diff_vs_prev
FROM demo_orders
WHERE customer_id = 101
ORDER BY order_date, order_id;
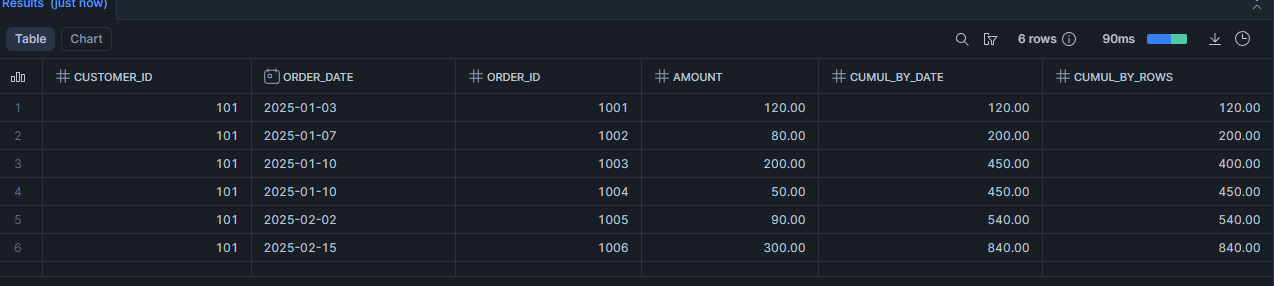
Scénario 3 : Suivre le cumul des dépenses client après chaque commande (calculer un cumul)
Objectif : afficher, pour chaque commande, le total dépensé par le client jusqu’à cette commande.
SELECT
customer_id,
order_date,
order_id,
amount,
-- cumul "par date" (si plusieurs lignes le même jour, ça peut regrouper)
SUM(amount) OVER (
PARTITION BY customer_id
ORDER BY order_date
) AS cumul_by_date,
-- cumul "ligne par ligne"
SUM(amount) OVER (
PARTITION BY customer_id
ORDER BY order_date, order_id
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
) AS cumul_by_rows
FROM demo_orders
WHERE customer_id = 101
ORDER BY order_date, order_id;
Scénario 4 : Top 3 commandes les plus chères par client
QUALIFY est l'équivalent de WHERE pour les window functions. Au lieu d'enrouler ta requête dans un CTE pour filtrer sur le résultat d'un ROW_NUMBER(), tu peux filtrer directement avec QUALIFY. Disponible sur Snowflake, BigQuery, Databricks et DuckDB. Ne fonctionne pas sur PostgreSQL ni MySQL.Avant (avec CTE) :WITH ranked AS (
SELECT *, ROW_NUMBER() OVER (PARTITION BY customer_id ORDER BY amount DESC) AS rn
FROM demo_orders
)
SELECT * FROM ranked WHERE rn <= 3;
Après (avec QUALIFY) :SELECT *
FROM demo_orders
QUALIFY ROW_NUMBER() OVER (PARTITION BY customer_id ORDER BY amount DESC) <= 3;
Plus compact, plus lisible, même résultat.
SELECT
customer_id,
order_id,
order_date,
amount
FROM demo_orders
QUALIFY ROW_NUMBER() OVER (
PARTITION BY customer_id
ORDER BY amount DESC, order_date DESC, order_id DESC
) <= 3
ORDER BY customer_id, amount DESC, order_id DESC;
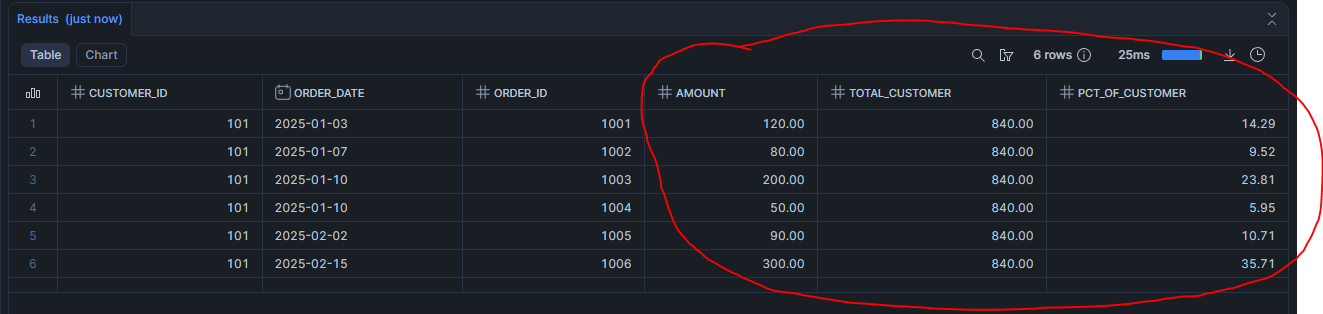
JOIN LATERAL, qui s'exprime parfois plus naturellement. Quand N est petit (1 à 5), LATERAL peut même être plus rapide grâce au early termination. Voir LATERAL JOIN et CROSS APPLY : exécuter une sous-requête par ligne en SQL.Scénario 5 : Part et poids de chaque commande dans le total du client
SELECT
customer_id,
order_date,
order_id,
amount,
SUM(amount) OVER (PARTITION BY customer_id) AS total_customer,
ROUND(100 * amount / SUM(amount) OVER (PARTITION BY customer_id), 2) AS pct_of_customer
FROM demo_orders
ORDER BY order_date, order_id;
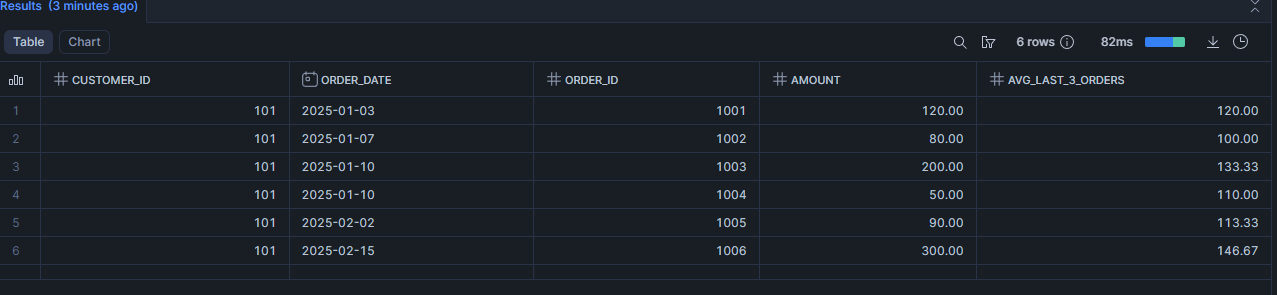
Scénario 6 : Moyenne des 3 dernières commandes
SELECT
customer_id,
order_date,
order_id,
amount,
ROUND(
AVG(amount) OVER (
PARTITION BY customer_id
ORDER BY order_date, order_id
ROWS BETWEEN 2 PRECEDING AND CURRENT ROW
), 2
) AS avg_last_3_orders
FROM demo_orders
ORDER BY order_date, order_id;
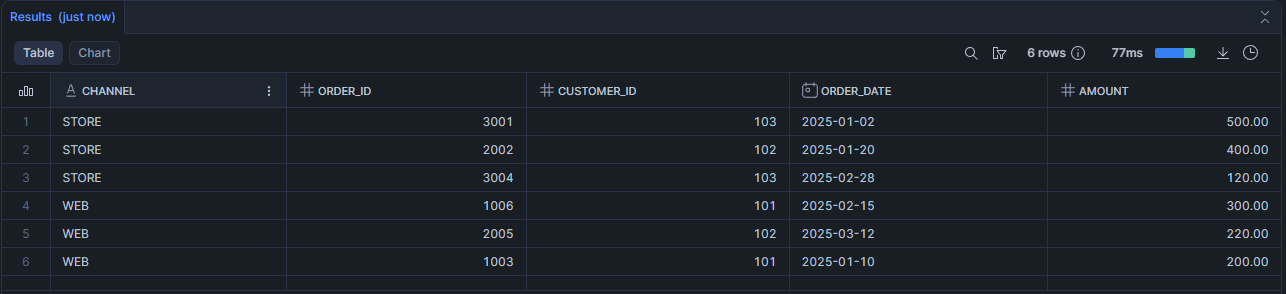
Scénario 7 : Top 3 commandes par canal
SELECT
channel,
order_id,
customer_id,
order_date,
amount
FROM demo_orders
QUALIFY ROW_NUMBER() OVER (
PARTITION BY channel
ORDER BY amount DESC, order_date DESC, order_id DESC
) <= 3
ORDER BY channel;
Scénario 8 : Calculer l'écart en jours entre commandes consécutives (LAG + DATEDIFF)
SELECT
customer_id,
order_id,
order_date,
DATEDIFF(
'day',
LAG(order_date) OVER (PARTITION BY customer_id ORDER BY order_date, order_id),
order_date
) AS days_since_prev
FROM demo_orders
//QUALIFY days_since_prev IS NOT NULL
ORDER BY customer_id, order_date, order_id;
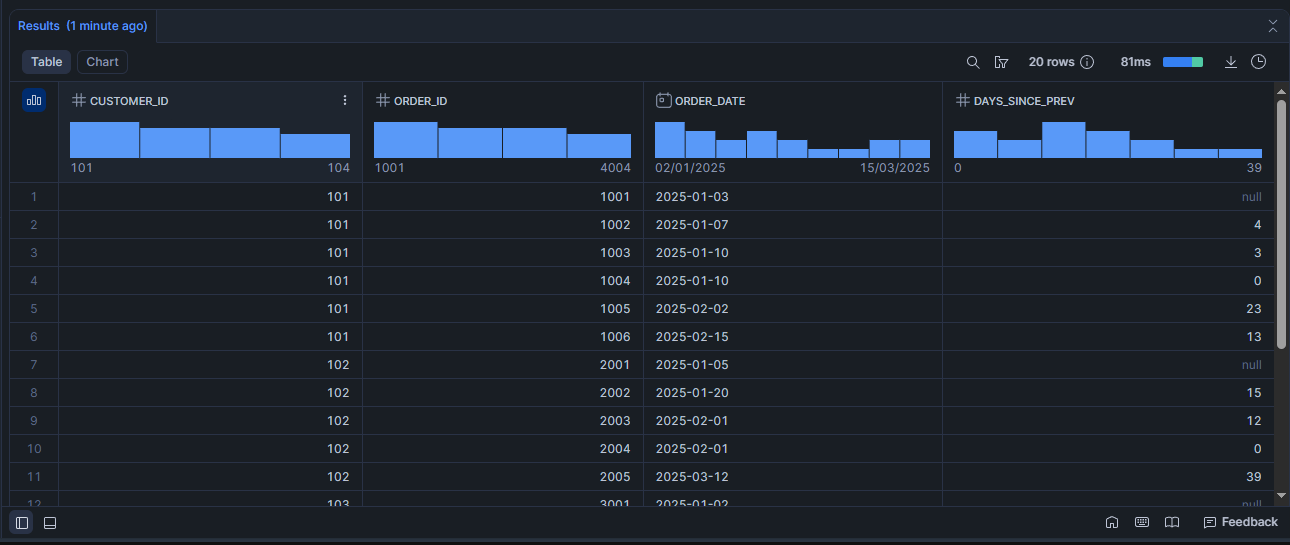
DATEDIFF calcule l'écart en jours, semaines, mois ou heures entre deux dates. Pour creuser toutes les fonctions de date, voir Manipuler les dates en SQL Snowflake : DATE_TRUNC, DATEADD, DATEDIFF.Aller plus loin : pratiquer les window functions
Les window functions, comme la plupart du SQL avancé, ne s'apprennent vraiment qu'en pratiquant. Sur DataCertification.fr, le module SQL Lab propose 240+ exercices interactifs avec une partie dédiée aux window functions (ROW_NUMBER, LAG, cumul, top-N avec QUALIFY).
👉 Pratiquer les window functions sur DataCertification.fr
Pour aller plus loin sur Snowflake, j'ai regroupé tous mes articles dans un parcours complet :
👉 Accéder à la Formation Snowflake
Tu veux que je t'accompagne sur ton projet data (modélisation, performance SQL, Snowflake, dbt) ?
👉 Réserver un appel de 30 minutes
Questions
C'est quoi une window function en SQL ?
Une window function est une fonction SQL qui calcule une valeur sur un sous-ensemble de lignes (la fenêtre) tout en gardant la granularité d'origine. Contrairement à GROUP BY qui agrège et réduit le nombre de lignes, une window function ajoute une colonne calculée à chaque ligne. La syntaxe est fonction() OVER (PARTITION BY ... ORDER BY ...).
Quelle différence entre OVER, PARTITION BY et ORDER BY dans une window function ?
OVER déclare qu'il s'agit d'une window function. PARTITION BY définit le groupe sur lequel calculer (équivalent du GROUP BY mais sans réduire les lignes). ORDER BY définit l'ordre à l'intérieur de chaque groupe, ce qui est obligatoire pour ROW_NUMBER, LAG, LEAD et les calculs cumulés.
ROW_NUMBER, RANK ou DENSE_RANK : quelle différence ?
ROW_NUMBER attribue un numéro unique à chaque ligne dans l'ordre (1, 2, 3, 4...). RANK attribue le même rang aux égalités et saute des rangs après (1, 2, 2, 4...). DENSE_RANK attribue le même rang aux égalités sans sauter (1, 2, 2, 3...). Pour numéroter sans ambiguïté, ROW_NUMBER. Pour classer avec gestion des égalités, RANK ou DENSE_RANK.
Comment faire un top N par groupe en SQL Snowflake ?
Deux approches en Snowflake : (1) avec QUALIFY directement : SELECT * FROM commandes QUALIFY ROW_NUMBER() OVER (PARTITION BY client ORDER BY date DESC) <= 3. (2) avec un CTE qui calcule ROW_NUMBER puis filtre. QUALIFY est plus compact et est aussi disponible sur BigQuery et Databricks. Sur PostgreSQL ou MySQL, il faut passer par un CTE.
À quoi sert QUALIFY en SQL Snowflake ?
QUALIFY est l'équivalent de WHERE mais pour les window functions. Il permet de filtrer directement sur le résultat d'une window function sans passer par un CTE intermédiaire. C'est une clause spécifique à Snowflake, BigQuery, Databricks et DuckDB. Très utile pour le top-N par groupe : QUALIFY ROW_NUMBER() OVER (...) <= 3.
Comment calculer un cumul (running total) en SQL ?
Utilise SUM(colonne) OVER (PARTITION BY groupe ORDER BY ordre). Pour un cumul ligne par ligne strict, ajoute ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW. Sans cette clause, Snowflake calcule par défaut en mode RANGE qui peut regrouper les lignes de même ordre. La clause ROWS est explicite et donne un cumul ligne par ligne déterministe.
Quelle différence entre LAG et LEAD ?
LAG renvoie la valeur de la ligne précédente dans l'ordre du window. LEAD renvoie la valeur de la ligne suivante. Les deux prennent un offset optionnel (par défaut 1). LAG(montant) OVER (PARTITION BY client ORDER BY date) compare avec la commande précédente. C'est pratique pour calculer une variation, un écart en jours, ou détecter un changement.
Quelle différence entre ROWS BETWEEN et RANGE BETWEEN ?
ROWS BETWEEN définit un cadre par nombre physique de lignes (2 PRECEDING = exactement 2 lignes avant la ligne courante). RANGE BETWEEN définit le cadre par valeurs de l'ORDER BY (2 PRECEDING = toutes les lignes dont la valeur d'ordre est dans une plage de 2). RANGE peut donc embarquer plusieurs lignes si plusieurs ont la même valeur d'ordre.
Quelle différence entre GROUP BY et window function ?
GROUP BY agrège les lignes et réduit le nombre de résultats (une ligne par groupe). Window function calcule sur un groupe (PARTITION BY) mais conserve toutes les lignes d'origine en ajoutant une colonne calculée. GROUP BY répond à 'quel est le total par client'. Window function répond à 'pour chaque commande, quel est le total cumulé du client'.
Comment calculer une moyenne mobile (rolling average) en SQL ?
Utilise AVG(colonne) OVER (PARTITION BY groupe ORDER BY ordre ROWS BETWEEN N PRECEDING AND CURRENT ROW). Par exemple, pour la moyenne des 3 dernières commandes : AVG(amount) OVER (PARTITION BY customer_id ORDER BY date ROWS BETWEEN 2 PRECEDING AND CURRENT ROW). Le 2 PRECEDING + CURRENT ROW couvre bien 3 lignes.