

Quand on regarde les offres de missions aujourd'hui autour de Snowflake, dbt revient presque tout le temps. Et dans une Modern Data Stack, il est généralement placé juste entre l’ingestion des données et la BI. Autant dire qu'il est devenu difficile de l'ignorer.

Du coup, j'ai décidé d'écrire cet article pour montrer ce que dbt fait vraiment, quel problème il résout, et pourquoi il est devenu aussi populaire dans l'écosystème data.
Cet article est le premier de cette série. On pose les bases ici avec le pourquoi, le comment, les concepts clés. Et dans les prochains, on passera à la pratique, étape par étape. L'objectif c'est qu'à la fin de la série, tu sois capable de monter un projet dbt de bout en bout, pareil que la formation Snowflake.
Pourquoi on a besoin de dbt
Le vrai problème
Soyons honnêtes. Dans beaucoup d'équipes data, la couche de transformation ressemble à ça :
- Des transformations qui dépendent les unes des autres, mais l'ordre d'exécution est dans la tête d'une seule personne.
- Zéro test. Si la table source change de format, tu t'en rends compte quand le métier t'appelle parce que les dashboards affichent n'importe quoi.
- La documentation ? C'est un fichier Confluence de 2021 que plus personne ne lit, ou elle n'existe tout simplement pas et il faut regarder le code.
Je caricature un peu, mais pas tant que ça. Et ce n'est la faute de personne, c'est juste qu'il n'y avait pas d'outil adapté pour organiser le SQL comme on organise du code applicatif.
Le cloud
Avec les warehouses cloud comme Snowflake, le game a changé. Au lieu de transformer les données à l'extérieur (dans un ETL classique type Talend ou Informatica), on les charge d'abord brutes dans le warehouse, puis on les transforme directement en SQL à l'intérieur.
Pourquoi ? Parce que le compute est devenu pas cher et scalable. Tu allumes un virtual warehouse, tu fais tes transformations, tu l'éteins. Pas besoin d'un serveur ETL à côté.
Mais du coup, quand ta logique de transformation est du SQL. Beaucoup de SQL. Et sans un cadre pour l'organiser, ça devient vite ingérable.
dbt, c'est ce cadre. Il prend ton SQL et il en fait un projet structuré, testé, documenté et versionné.
dbt, c'est quoi concrètement
Pas besoin de tourner autour du pot. dbt, c'est un outil open source qui fait une chose et qui le fait bien, il permet d'exécuter tes transformations SQL dans le bon ordre, avec des tests et de la documentation, et rien de plus.
Il ne s'occupe pas d'extraire les données depuis tes sources (ça c'est le job de Fivetran, Airbyte, Snowpipe, stitch de Qlik....). Il ne s'occupe pas non plus de charger les données brutes. Il part du principe que tes données sont déjà dans le warehouse, et il gère que la partie transformation.
Concrètement, un projet dbt c'est :
- Des fichiers
.sql, appelés modèles, qui contiennent chacun unSELECT. - Un système de dépendances entre ces modèles.
- Des tests pour vérifier la qualité des données.
- De la documentation générée automatiquement.
- Le tout versionné avec Git, comme du vrai code.
Les modèles
Un modèle dbt, c'est tout simplement un fichier SQL avec un SELECT.
Quand tu lances dbt run, dbt prend ce SELECT, l'exécute dans ton warehouse et matérialise le résultat en table ou en vue. C'est tout.
Par exemple quand tu as une table brute raw_orders qui arrive de ton ERP dans Snowflake :
-- models/staging/stg_orders.sql
SELECT
order_id,
customer_id,
order_date,
UPPER(status) AS status,
amount_cents / 100 AS amount
FROM raw_orders
WHERE order_date IS NOT NULL
Tu lances dbt run, et dbt crée une table (ou une vue) stg_orders dans Snowflake. Propre, et prête à être utilisée.
Les références ref()
Là où ça devient intéressant, c'est quand un modèle dépend d'un autre. Au lieu d'écrire le nom de la table en dur dans ton FROM, tu utilises ref() :
-- models/marts/fct_orders.sql
SELECT
o.order_id,
o.order_date,
o.amount,
c.customer_name,
c.segment
FROM {{ ref('stg_orders') }} o
LEFT JOIN {{ ref('stg_customers') }} c
ON o.customer_id = c.customer_id
Ce {{ ref('stg_orders') }} dit à dbt : 'ce modèle a besoin de stg_orders pour tourner.' et donc dbt comprend 'construit un graphe de dépendances et exécute tout dans le bon ordre'. Tu n'as rien à orchestrer toi-même.
L'objectif est d'arrêter de dire qu'il faut lancer le script A avant B, mais le tout après C et E. dbt gère l'ordre automatiquement.
Organiser le projet (staging, intermediate, marts)
Si tu as lu mon article sur l'architecture Médaillon : Bronze, Silver, Gold, tu vas retrouver la même logique ici.
Les tables raw (celles que tu charges brutes dans Snowflake via Snowpipe, COPY INTO ou un outil d'ingestion comme Fivetran) correspondent au Bronze donc la donnée est dans son état brut, sans transformation. Dans dbt, ces tables ne sont pas des modèles, ce sont des sources. dbt commence son travail à partir de là. Le staging et l'intermediate correspondent au Silver et c'est là qu'on nettoie, qu'on type, qu'on déduplique et qu'on enrichit.
Les marts correspondent au Gold et donc les tables finales, prêtes à être consommées par le métier.
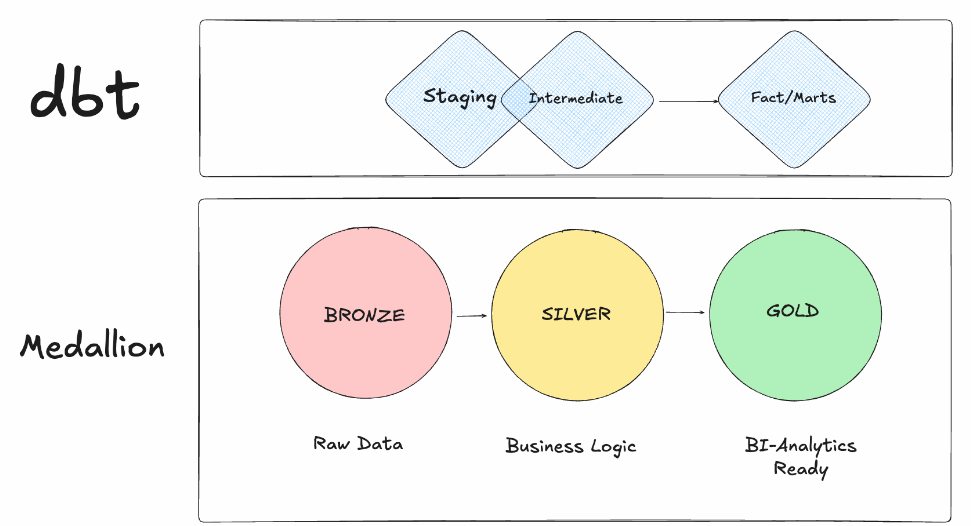
Quand tu commences à avoir 10, 20, 50 modèles, il te faut une structure. La convention la plus courante (et celle qu'on utilisera dans la série), c'est de découper en trois couches.
Staging : le nettoyage (Bronze → Silver)
Tu prends chaque table brute (Bronze) et tu la transformes en donnée propre. Renommage de colonnes, conversions de types, filtres basiques. Un modèle de staging = une source. C'est la première étape vers le Silver.
-- models/staging/stg_customers.sql
SELECT
id AS customer_id,
TRIM(name) AS customer_name,
LOWER(email) AS email,
created_at
FROM {{ source('raw', 'raw_customers') }}
Intermediate : la logique métier (Silver)
Tu fais les jointures, les calculs intermédiaires, les agrégations partielles. Ces modèles servent de briques internes mais ils ne sont pas consommés directement par les dashboards. On est en plein dans le Silver et donc la donnée est fiable, structurée, mais pas encore orientée métier.
-- models/intermediate/int_orders_enriched.sql
SELECT
o.order_id,
o.order_date,
o.amount,
o.status,
c.customer_name,
c.segment
FROM {{ ref('stg_orders') }} o
LEFT JOIN {{ ref('stg_customers') }} c
ON o.customer_id = c.customer_id
Marts : les tables finales (Gold)
C'est ce que tes utilisateurs consomment. Tes tables de faits, tes dimensions, tes agrégats. C'est ça qui alimente Qlik Sense, Power BI ou Looker. On est dans le Gold, donc la donnée est prête, avec les indicateurs attendus par le métier.
-- models/marts/fct_revenue_daily.sql
{{ config(materialized='table') }}
SELECT
order_date,
segment,
COUNT(*) AS total_orders,
SUM(amount) AS total_revenue,
AVG(amount) AS avg_order_value
FROM {{ ref('int_orders_enriched') }}
WHERE status = 'COMPLETED'
GROUP BY order_date, segment
Le flux complet ressemble à ça :
Bronze (raw) Silver (dbt) Gold (dbt)
------------- ------------------------------------- --------------------
raw_orders --> stg_orders ---┐
├---> int_orders_enriched ---> fct_revenue_daily
raw_customers -> stg_customers-┘
Chaque fichier fait une chose. Tu sais exactement d'où vient chaque donnée. Et si tu veux modifier le calcul du revenue, tu sais où aller.
Les matérialisations
dbt propose plusieurs façons de matérialiser un modèle. Pour commencer, les trois plus utiles à comprendre dans un premier temps sont : view, table et incremental.
- View : dbt crée une vue SQL tout simplement.
- Table : dbt crée une vraie table (
CREATE TABLE AS SELECT). - Incremental : dbt évite de recalculer toute la table à chaque exécution. Il permet de ne traiter que les nouvelles données, ou les données qui ont changé, selon la logique met en place.
On détaillera ça dans un article dédié avec des exemples concrets.
Les tests
C'est probablement la fonctionnalité la plus sous-estimée de dbt, et pourtant c'est ce qui change tout par rapport au SQL classique. Tu peux écrire des tests sur tes données directement dans ton projet, et les lancer en une commande.
Exemple d'un tests dans un fichier YAML :
# models/staging/_stg_models.yml
models:
- name: stg_orders
columns:
- name: order_id
tests:
- unique
- not_null
- name: status
tests:
- accepted_values:
values: ['COMPLETED', 'PENDING', 'CANCELLED']
- name: customer_id
tests:
- relationships:
to: ref('stg_customers')
field: customer_id
L'objectif, c'est que si un test échoue, tu le sais tout de suite. Pas trois jours plus tard quand quelqu'un remarque un truc bizarre sur un dashboard en prod.
La documentation : elle se génère toute seule
Tu ajoutes des descriptions dans tes fichiers YAML :
models:
- name: fct_revenue_daily
description: "CA journalier par segment client, sur les commandes complétées uniquement."
columns:
- name: total_revenue
description: "Somme des montants des commandes (en euros)."
Tu lances dbt docs generate, et dbt te sort un site web interactif avec le schéma de chaque table, les descriptions, les tests, et surtout le graphe de dépendances complet dans lequel tu peux voir visuellement d'où vient chaque donnée et où elle va.
dbt en 2026 : Core, Cloud et Fusion
Avant de coder, un point sur les versions, parce que ça a bougé beaucoup récemment et que tu vas voir passer ces noms partout.
dbt Core, c'est la version open source, en ligne de commande. Tu l'installes, tu tapes dbt run, c'est parti. C'est gratuit, c'est la base historique, et largement suffisant pour apprendre comme pour des projets en petite équipe.
dbt Cloud c'est la version SaaS avec une interface web, un IDE, un scheduler intégré, de la CI/CD. Plus pratique en entreprise, mais payant.
Le moteur Fusion c'est la nouveauté, et c'est ce qui change la donne. dbt Labs a réécrit le moteur de dbt entièrement en Rust (à la place de Python) pour qu'il soit beaucoup plus rapide. Depuis 2026, c'est le moteur par défaut des nouveaux projets, et Snowflake l'intègre nativement.
Dans cette série, je vais utiliser Fusion avec l'extension VS Code connecté à Snowflake car pour moi c'est la meilleure façon d'apprendre ce qui se passe vraiment sous le capot.
Pourquoi cette série tombe bien si tu fais du Snowflake
Si tu suis déjà ma formation Snowflake, tu as les bases du warehouse avec l'architecture, le stockage, le compute, la sécurité, les rôles. Tout ça, c'est la fondation.
Mais Snowflake ne te dit pas comment structurer ton SQL. Il te donne la puissance de calcul, mais c'est à toi d'organiser tes transformations. Et c'est exactement le rôle de dbt.
Le duo Snowflake + dbt, c'est le standard du marché en ce moment. C'est ce qu'on retrouve dans la grande majorité des offres freelance data engineer et analytics engineer. Maîtriser les deux est pour moi un vrai levier.
La suite ?
Cet article, c'était le "pourquoi" et le "comment ça marche avec une vision globale". Dans les prochains, on passe à la pratique, donc abonne-toi à la newsletter pour recevoir la suite directement dans ta boîte mail ;)
Aller plus loin : Formation Snowflake
Cet article fait partie de la formation dbt complète, du premier modèle au déploiement en production.
👉 Suivre toute la formation dbt
Consolide tes bases Snowflake.
👉 Accéder à la Formation Snowflake
Tu veux que je t'accompagne sur ton projet data (Snowflake, dbt, modélisation, performance, industrialisation) ?