
Si tu t'intéresses un peu à la data, tu as forcément déjà vu passer le schéma Bronze / Silver / Gold. C'est surtout Databricks qui a popularisé ces noms et qui a mis l’étiquette “Medallion” dessus, mais en réalité le principe existe depuis longtemps, juste sous d'autres formes comme par exemple (extract → transform → load) ou (raw → cleaned → curated).
D'ailleurs, il y a un débat sur le mot "architecture". Certains vont dire que ce n'est pas une architecture, mais plutôt un modèle, certain vont dire que c'est plutôt un pattern ou une structure... bref peu importe. Le vrai sujet n'est pas vraiment le terme.
Le plus important, c'est de comprendre ce que ça veut dire concrètement, et surtout ce que ça change quand tu construis une stack data et donc savoir où stocker le brut, où fiabiliser, et où exposer une donnée réellement prête à être consommée par le métier.
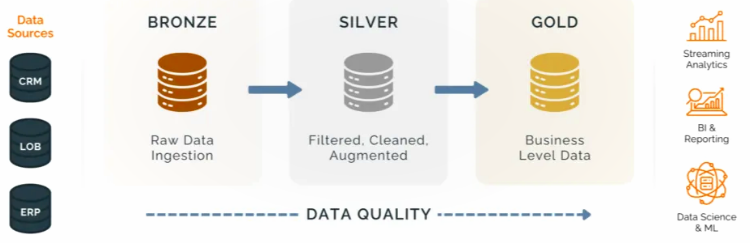
L'architecture Médaillon, c'est juste une façon claire d'organiser une plateforme data ou tu assumes que la donnée passe par des états (bronze, silver, gold). Donc tu ne mélanges jamais "brut", et "métier" dans les mêmes tables.
Bronze
Pour faire simple, la couche Bronze sert à une seule chose, conserver toutes les données brutes sans rien perdre.
Tu ingères la donnée comme elle arrive, en ajoutant le strict minimum pour pouvoir le reloader et l'auditer comme par exemple ajouter une date d’ingestion, la source, le offset si besoin. Donc l'objectif est de faire des contrôles de base (schéma) pour isoler les cas invalides, sans transformer la donnée.
Pourquoi c'est indispensable ? Parce que le jour où tu dois corriger une règle, reconstruire une période, ou comprendre un bug, tu veux pouvoir repartir de ce que tu as reçu, pas d'une version déjà "nettoyée". Et si un jour tu dois faire un full reload mais que la source ne te donne plus l'historique, tu seras très content d'avoir ton brut stocké proprement.
En bref Bronze, c'est : “voilà exactement ce que j'ai reçu.”
Silver
Silver, c'est là où tu passes du brut à du fiable.
Ici tu fais tout ce qui rend la donnée propre et stable : typage (dates, nombres…), formats standard, suppression des doublons, lignes invalides, règles de cohérence, valeurs manquantes gérées… bref, la base.
Le but de Silver, ce n'est pas le reporting mais d'avoir une donnée réutilisable pour plusieurs usages, sans refaire les mêmes corrections partout.
Et souvent, c'est aussi ici que tu gères l'incrémental car tu ne fais pas juste un append. Tu prends le delta (les nouvelles lignes, les mises à jour, parfois les suppressions) et tu mets à jour la table correctement.
Si tu dois arbitrer où mettre ton énergie, c'est ici. Parce qu'une Silver solide te fait gagner du temps partout dans la BI, data science ...
Gold
Gold, c'est ce que le métier consomme.
Ici, tu assumes la partie business donc les KPI, agrégats, tables prêtes pour les dashboards BI (qlik sense, power bi ...), bref des datasets qui ont un sens clair (sales, finance, marketing…) et une définition stable.
L'idée, c'est que la BI et les analyses doivent pointer sur cette zone, pas sur du brut ou du semi-propre. Comme ça, tout le monde a les mêmes chiffres, avec les mêmes règles.
Et c'est aussi là que tu commences à raisonner en data product car une table Gold n'est pas “juste une table finale”. C'est un produit data, avec un périmètre clair, un owner, une définition (glossaire), et une qualité attendue.
Tableau comparatif Bronze vs Silver vs Gold
| Couche | But | Transformations | Qualité attendue |
|---|---|---|---|
| Bronze | Conserver le brut + audit | Minimales (métadonnées d’ingestion) | Contrôles de base (schéma, champs) |
| Silver | Rendre fiable + réutilisable | Typage, standardisation, dédoublonnage, gestion des nulls, incrémental etc... | Stable et cohérente |
| Gold | Servir le métier | Agrégats, KPI, datasets orientés usages | Ready pour la BI + définitions stables |
Exemple concret
Comme d'habitude dans les articles du blog, y'a pas mieux d'un exemple pour comprendre le concept. On prend un cas simple, dans le quel chaque magasin envoie l'état de stock (produit, quantité) plusieurs fois par jour.
L’objectif reste le même : Bronze = je garde tout, Silver = je fiabilise, Gold = je sers le métier.
Bronze
Tu stockes les fichiers tels qu’ils arrivent en ajoutant le strict minimum pour auditer comme par exemple date d'ingestion, source.
Si un fichier est incomplet ou mal formé, tu le mets de côté, tu ne casses pas toute l'ingestion.
Silver
Tu mets au propre :
- Produits et magasins bien identifiés (mapping des codes)
- Quantités en nombre, dates au bon format
- Suppression des doublons (si le même fichier arrive deux fois)
- Si le magasin renvoie une mise à jour, tu prends la plus récente
- etc....
Gold
Là, tu exposes des tables prêtes à consommer, avec les indicateurs attendus, par exemple une table gold qui contient le stock actuel par jour et par magasin et par produit.
Erreurs à éviter (celles qui te coûtent cher)
Comme pour n'importe quel outil, une mauvaise utilisation peut vite le transformer en problème. Et ce que je liste ici, ce ne sont que quelques exemples parmi les plus fréquents.
La première erreur, c'est d'ignorer la conformité des données et donc pas de contrôle de schéma, pas de règles de base, pas de checks qualité sur ce qui entre en raw. Et c'est simple ==> mauvaise data en entrée = mauvaise data en sortie.
Deuxième erreur : mélanger Silver et Gold. Quand les équipes dupliquent les règles “métier” dans la Silver, ou quand la Gold devient une Silver bis, tu finis avec de la donnée dupliquée.. et des chiffres qui varient d'un dashboard à l'autre.
Troisième erreur et d'ignorer metadata et lineage. Sans traçabilité, tu ne sais plus d'où vient un chiffre, qui l'a transformé, ni quand ça a changé. Et sans gouvernance (accès, règles, périmètre), tu risques d'exposer des données sensibles ou instables.
Il ne faut pas oublier que les trois couches ne sont pas une religion. Si une transformation est légère et stable, elle peut très bien rester en Silver sans forcément créer une Gold dédiée. L'objectif, c'est la clarté et la qualité et donc pas systématiquement créer trois niveaux pour chaque source, même quand ce n'est pas nécessaire.
Si tu as d'autres points de vigilance, n'hésite pas à les partager en commentaire.
Implémenter Bronze/Silver/Gold dans Snowflake
Si tu veux passer du modèle à la pratique dans Snowflake, ces articles t’aident :
- Types de tables (permanent/transient/temporary/external)
- Time Travel & Fail-safe (audit / restauration)
- Streams Incrémental (CDC)
- Orchestration
- Dynamic tables
- Parcours complet Snowflake
Implémenter Bronze/Silver/Gold avec dbt
dbt est probablement l'outil le plus naturel pour matérialiser une architecture Médaillon. Le mapping est direct :
- Bronze →
sources/etstaging/(ingestion brute + renommage de colonnes, typage léger) - Silver →
intermediate/(déduplication, jointures, règles de qualité) - Gold →
marts/(KPI, agrégats métier, datasets prêts pour la BI)
Cette structure est aussi celle que recommande dbt-labs dans ses guidelines officielles. Chaque couche correspond à un répertoire dbt, et chaque modèle hérite des couches précédentes via la fonction ref().
Pour creuser, voir l'article dbt : à quoi ça sert (exemples SQL) qui détaille les principes (sources, ref, matérialisations).
Aller plus loin : pratiquer la modélisation data
L'architecture Médaillon est un pattern, mais la vraie compétence est en aval : savoir construire chaque couche (déduplication, SCD, modélisation dimensionnelle, gestion de l'incrémental). Sur DataCertification.fr, l'Analytics Lab propose 100+ exercices interactifs sur la modélisation data (faits, dimensions, SCD type 1/2/6, incrémental).
👉 Pratiquer la modélisation sur DataCertification.fr
Pour aller plus loin sur Snowflake, j'ai regroupé tous mes articles dans un parcours complet :
👉 Accéder à la Formation Snowflake
Questions
C'est quoi l'architecture Médaillon ?
L'architecture Médaillon est un pattern d'organisation des données en trois couches : Bronze (données brutes, conservées telles quelles pour audit et reload), Silver (données fiabilisées, typées, dédoublonnées et stables) et Gold (données métier, agrégats et KPI prêts pour la BI). Popularisé par Databricks, le pattern existait avant sous d'autres noms (raw/cleaned/curated, extract/transform/load). Il s'applique à n'importe quelle plateforme data.
Est-ce qu'il faut toujours 3 couches ?
Non. Comme mentionné dans ma conclusion, les trois couches ne sont pas une religion et si les transformations sont légères et stables, tu peux rester en Silver sans créer une Gold dédiée.
Où mettre les règles métier ?
En général en Gold pour garder une Silver réutilisable et éviter la duplication. Si une règle métier est mise en Silver, elle se retrouve appliquée à tous les usages, ce qui peut poser problème quand un autre cas d'usage a besoin de règles différentes. Garder Silver générique et Gold spécialisée par domaine métier (sales, finance, marketing) est le meilleur compromis.
Quelle différence entre Bronze, Silver et Gold ?
Bronze conserve les données brutes telles qu'elles arrivent, sans transformation, avec des métadonnées d'audit (date d'ingestion, source). Silver applique les transformations qui rendent la donnée fiable et réutilisable : typage, dédoublonnage, standardisation, gestion des nulls, incrémental. Gold expose les datasets prêts pour le métier : agrégats, KPI, tables orientées dashboards BI avec des définitions stables.
Comment implémenter l'architecture Médaillon avec dbt ?
Le mapping est direct car sources et staging pour Bronze (ingestion + typage léger), intermediate pour Silver (déduplication, jointures, qualité), marts pour Gold (KPI, agrégats métier). C'est la structure recommandée par dbt-labs. Chaque couche correspond à un répertoire dbt et chaque modèle hérite des couches précédentes via la fonction ref().
L'architecture Médaillon est-elle spécifique à Databricks ?
Non, malgré son nom popularisé par Databricks. Le pattern Bronze/Silver/Gold est applicable sur n'importe quelle plateforme data : Snowflake, BigQuery, Redshift, Postgres, Fabric. C'est un pattern d'organisation conceptuel, pas une technologie. Snowflake l'implémente très bien avec ses types de tables, Streams, Tasks et Dynamic Tables.
Quelles sont les erreurs courantes en architecture Médaillon ?
Trois erreurs reviennent souvent : (1) ignorer la conformité des données et ne pas faire de contrôles de schéma sur la Bronze, ce qui propage les erreurs en aval, (2) mélanger Silver et Gold en dupliquant les règles métier, ce qui crée des chiffres différents selon les dashboards, (3) ignorer le lineage et la gouvernance, ce qui rend impossible de tracer d'où vient un chiffre et qui peut y accéder.
