
Quand j'ai commencé en data en 2011 (oui, ça fait 15 ans, et non, ça ne me rajeunit pas 😅), j'ai lu plusieurs cours SQL d'affilée. À la fin, je savais réciter la syntaxe d'un SELECT, mais devant une vraie table je restais bloqué. Le problème, ce n'est pas la syntaxe. Le vrai sujet, c'est de comprendre comment une requête raisonne, dans quel ordre elle lit les données, et pourquoi le même résultat peut s'écrire de plusieurs façons.
Pour être clair et honnête, tu peux lire tous les articles SQL du monde, tu ne seras jamais bon si tu ne pratiques pas et que tu n'écris pas toi-même les requêtes. C'est exactement pour ça que les exemples viennent tous du SQL Lab de DataCertification, où tu peux écrire chaque requête dans ton navigateur et voir le résultat tout de suite. Pour les sujets plus avancés (window functions, joins spécialisés, CTE récursives), j'ai déjà des articles dédiés.
La seule chose à comprendre avant tout le reste : l'ordre d'exécution
L'erreur qui bloque 90 % des débutants. On croit qu'une requête SQL s'exécute dans l'ordre où on l'écrit, de haut en bas. C'est faux.
Tu écris la requête dans cet ordre :
SELECT ...
FROM ...
WHERE ...
GROUP BY ...
HAVING ...
ORDER BY ...
LIMIT ...
Mais la base de données, elle, l'exécute dans cet ordre :
| Étape | Clause | Ce qu'elle fait |
|---|---|---|
| 1 | FROM / JOIN |
Choisit les tables et les relie |
| 2 | WHERE |
Filtre les lignes, une par une |
| 3 | GROUP BY |
Regroupe les lignes restantes |
| 4 | HAVING |
Filtre les groupes |
| 5 | SELECT |
Choisit les colonnes et calcule les alias |
| 6 | ORDER BY |
Trie le résultat |
| 7 | LIMIT |
Coupe les N premières lignes |
Une fois que tu as ça en tête, plein de comportements bizarres deviennent logiques :
- Tu ne peux pas filtrer un calcul d'agrégat (
COUNT,AVG) dans leWHERE, parce que leWHEREs'exécute avant le regroupement. Pour ça, il y aHAVING. - Tu ne peux pas réutiliser un alias défini dans le
SELECTà l'intérieur duWHERE, parce que leSELECTpasse après leWHERE. La colonne n'existe pas encore. - Le
LIMITarrive en dernier, donc il s'applique au résultat déjà trié, pas aux lignes brutes.
Retiens cet ordre. C'est la clé qui débloque tout le reste de l'article.
La table qu'on va utiliser
Les exemples ci-dessous viennent de plusieurs exercices du SQL Lab. Selon l’exercice, la table utilisée peut changer (employees, products, etc.). Chaque requête est pensée pour fonctionner dans le lab associé.
| id | name | salary | department_id | hire_date | |
|---|---|---|---|---|---|
| 1 | Alice Martin | alice@corp.com | 55000 | 1 | 2022-01-15 |
| 2 | Bob Dupont | bob@corp.com | 62000 | 2 | 2021-06-01 |
| 3 | Charlie Leroy | charlie@corp.com | 48000 | 1 | 2023-03-20 |
| 4 | Diana Moreau | diana@corp.com | 71000 | 3 | 2020-09-10 |
| 5 | Eve Bernard | eve@corp.com | 53000 | 2 | 2022-11-05 |
1. Lire des données : SELECT, ORDER BY, LIMIT
Tout commence par SELECT. Tu choisis les colonnes, tu pars d'une table avec FROM.
-- Toutes les colonnes
SELECT * FROM employees;
-- Seulement deux colonnes
SELECT name, salary FROM employees;
SELECT * retourne tout. Pratique pour explorer mais à éviter en production car tu transportes des colonnes dont tu n'as pas besoin. Nomme toujours les colonnes une fois que tu sais ce que tu veux.
SELECTPour trier, c'est ORDER BY. Par défaut c'est croissant (ASC), tu ajoutes DESC pour l'inverse.
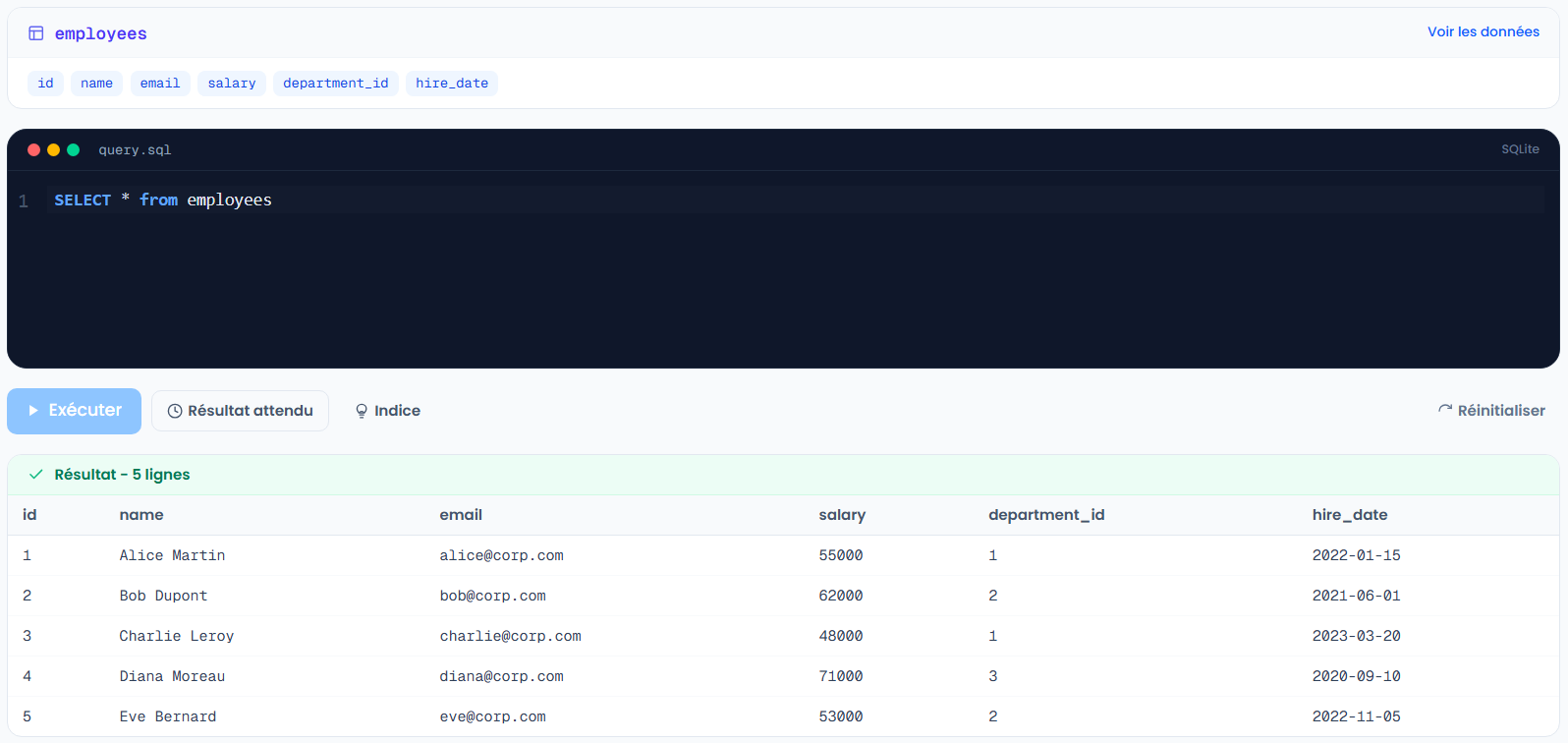
SELECT name, salary
FROM employees
ORDER BY salary DESC;
Résultat : Diana (71000) en haut, puis Bob, Alice, Eve, Charlie. Et si tu ne veux que le top 3, tu ajoutes LIMIT 3.
💡 À toi de jouer : Tous les employés (sb-01) puis Trier par salaire (sb-04) dans le module Les bases SELECT.
2. Filtrer les lignes : WHERE
WHERE garde uniquement les lignes qui respectent une condition.
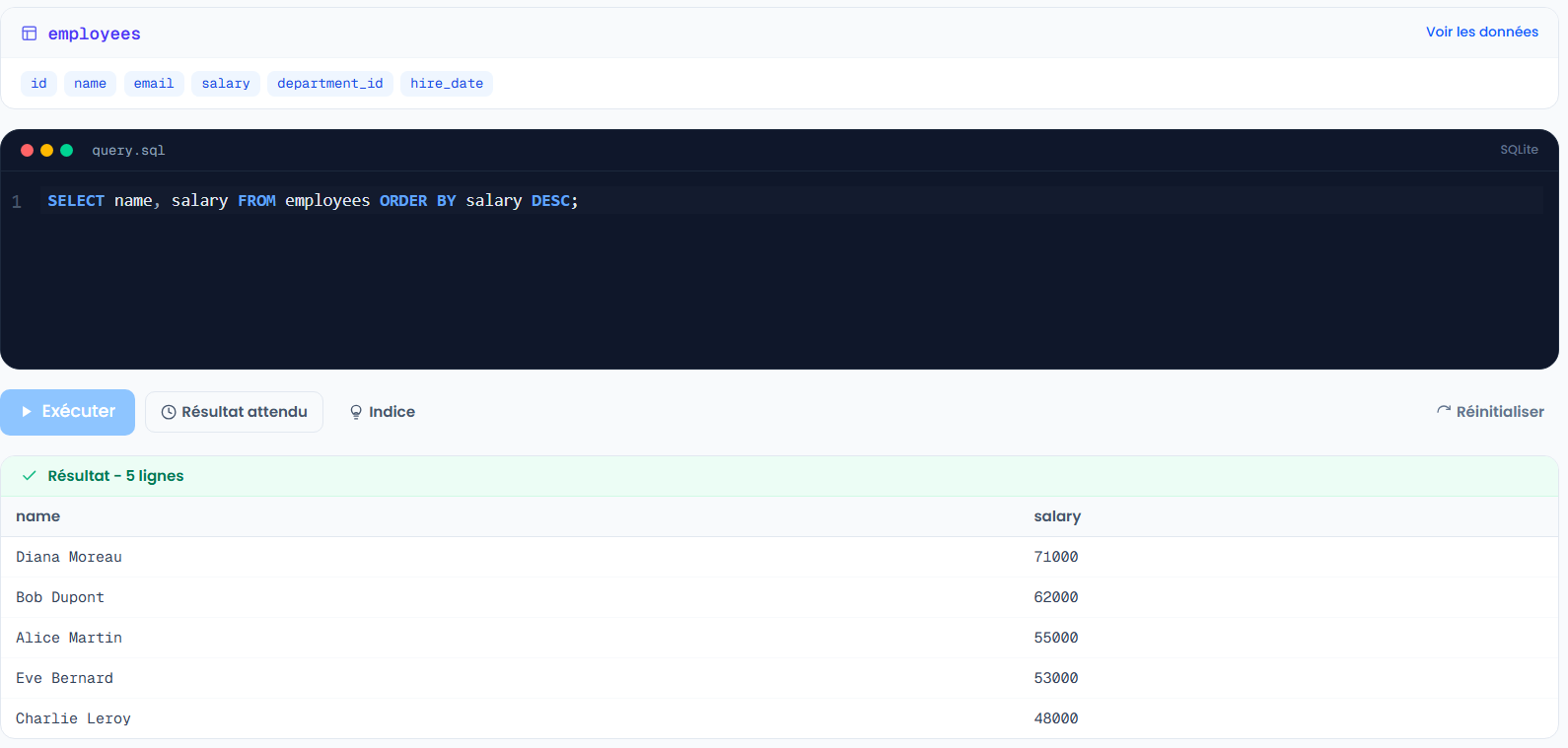
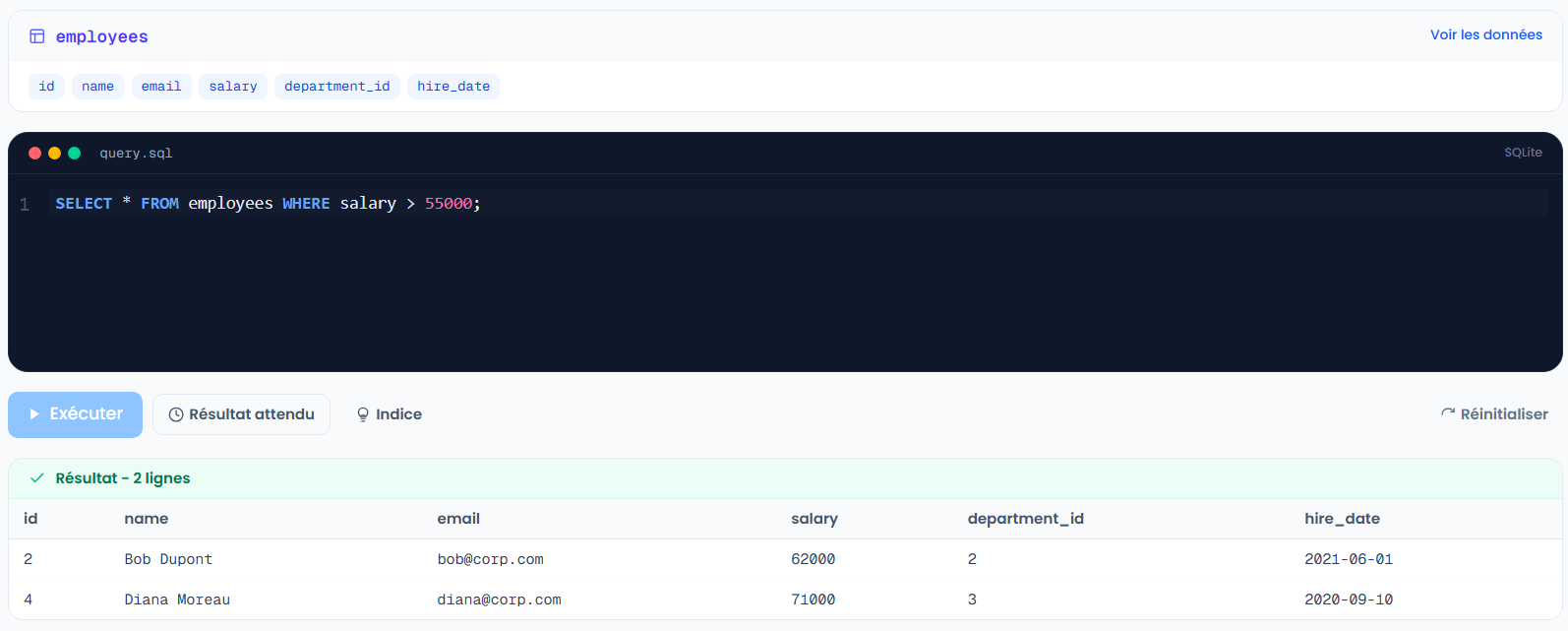
SELECT *
FROM employees
WHERE salary > 55000;
Sur notre table, ça retourne Bob (62000) et Diana (71000). Les opérateurs de comparaison (>, <, =, >=, <=, <>) marchent aussi bien sur les nombres que sur les dates.
WhereTu peux combiner les conditions avec AND et OR, et utiliser quelques opérateurs bien pratiques :
-- Plusieurs valeurs possibles
WHERE department_id IN (1, 2)
-- Un intervalle
WHERE salary BETWEEN 50000 AND 60000
-- Un motif de texte (% = n'importe quoi)
WHERE email LIKE '%@corp.com'
-- Une valeur manquante
WHERE email IS NULL
NULL avec =. WHERE email = NULL ne renvoie rien, même s'il y a des valeurs nulles. Un NULL veut dire "inconnu", et inconnu n'est égal à rien, pas même à lui-même. Toujours IS NULL ou IS NOT NULL. Ce piège revient en permanence, j'en parle en détail dans NOT IN vs NOT EXISTS : pourquoi le résultat diffère.💡 À toi de jouer : Filtrer par salaire (sb-03).
3. Agréger : COUNT, SUM, AVG, GROUP BY, HAVING
Jusqu'ici, on lit des lignes. Maintenant on calcule sur des paquets de lignes et c'est le coeur de l'analyse des données.
Une fonction d'agrégation prend plusieurs lignes et renvoie une seule valeur :
SELECT COUNT(*) AS total_produits FROM products;
SELECT MIN(price) AS prix_min, MAX(price) AS prix_max FROM products;
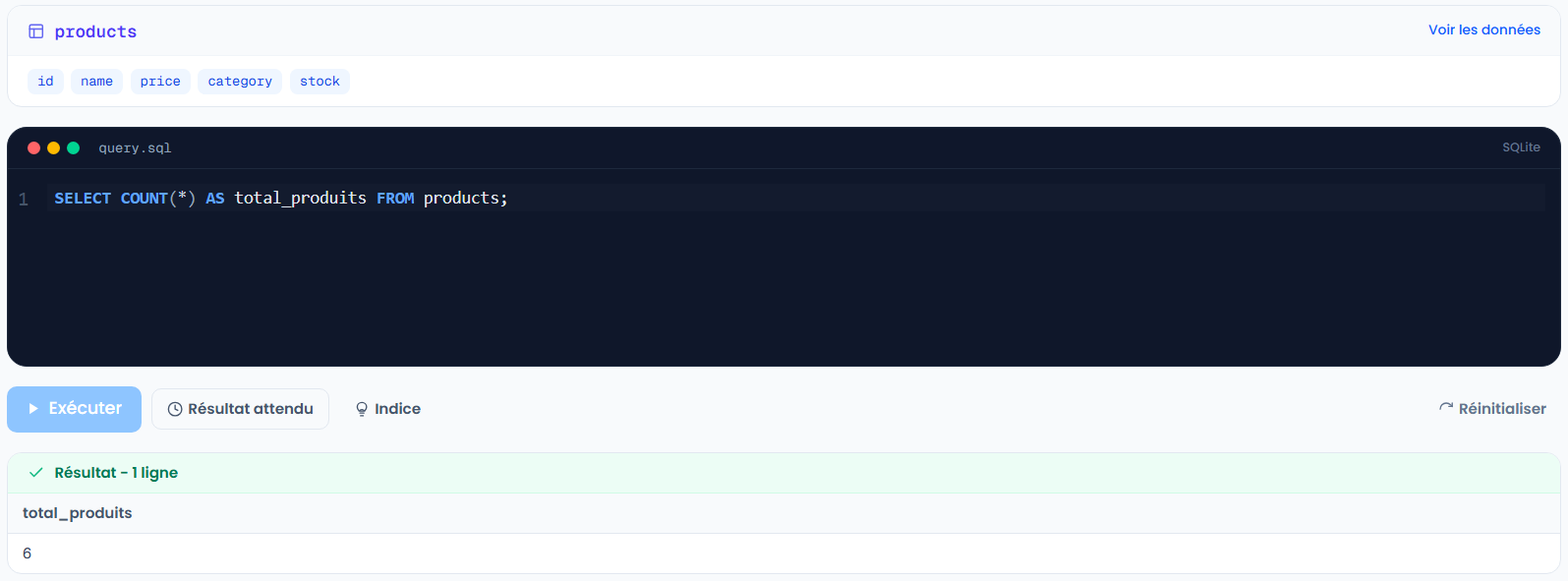
COUNT(*) compte toutes les lignes, COUNT(colonne) ignore les NULL de cette colonne. Deux résultats différents sur la même table.Le vrai pouvoir arrive avec GROUP BY. Au lieu d'un seul total, tu obtiens un total par catégorie :
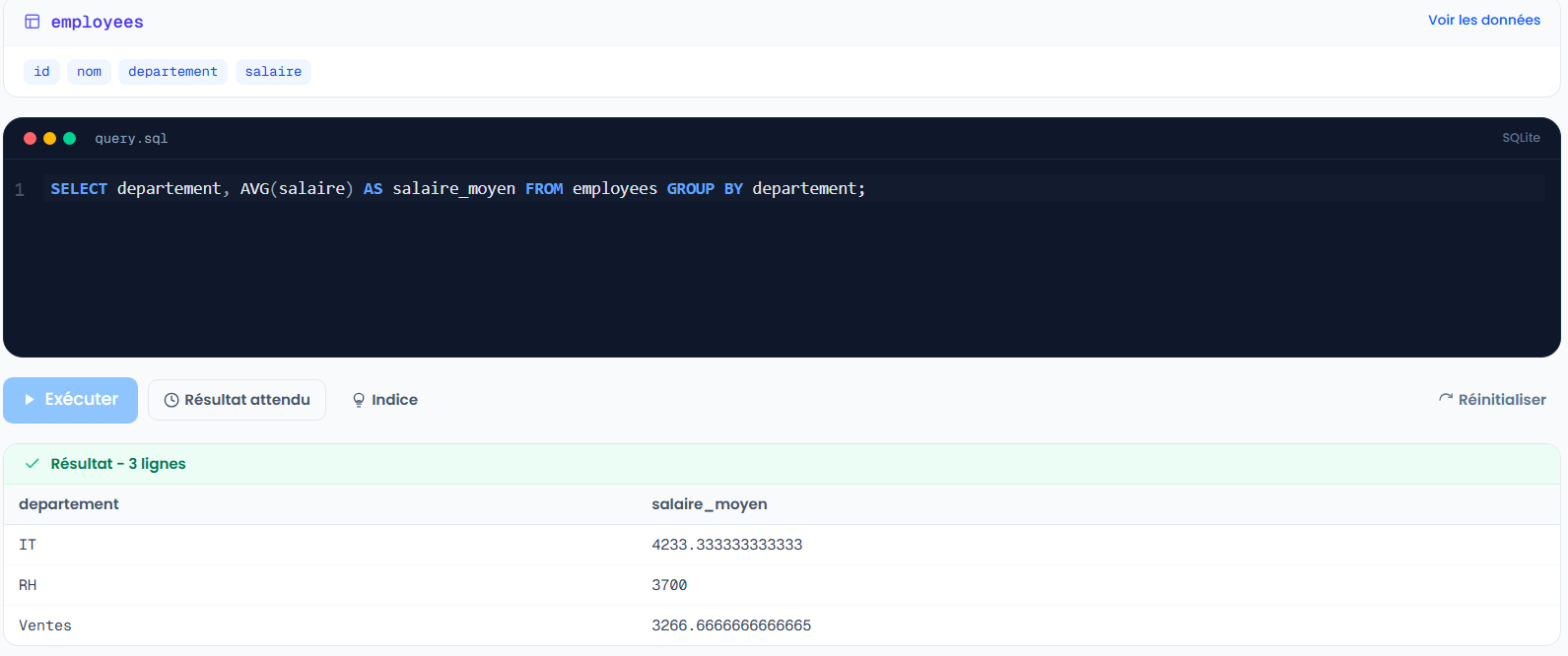
SELECT departement, AVG(salaire) AS salaire_moyen
FROM employees
GROUP BY departement;
Tu obtiens une ligne par département, avec son salaire moyen. La règle d'or est que toute colonne du SELECT qui n'est pas dans une fonction d'agrégation doit être dans le GROUP BY.
Et si tu veux filtrer les groupes (par exemple, ne garder que les départements dont le salaire moyen dépasse 50000) ? Pas avec WHERE, car le WHERE filtre avant le regroupement, et donc il ne connaît pas encore la moyenne. C'est le rôle de HAVING :
SELECT departement, AVG(salaire) AS salaire_moyen
FROM employees
GROUP BY departement
HAVING AVG(salaire) > 50000;
WHERE filtre les lignes, HAVING filtre les groupes. Retiens cette phrase, elle résume 80 % des erreurs de débutant sur les agrégats.
💡 À toi de jouer : Compter les produits (fa-01) puis Salaire moyen par département (gb-03).
4. Relier les tables : les JOINs
Dans la vraie vie, tes données sont éclatées sur plusieurs tables. Les employés d'un côté, les départements de l'autre, reliés par une clé (department_id). Le JOIN les recolle.
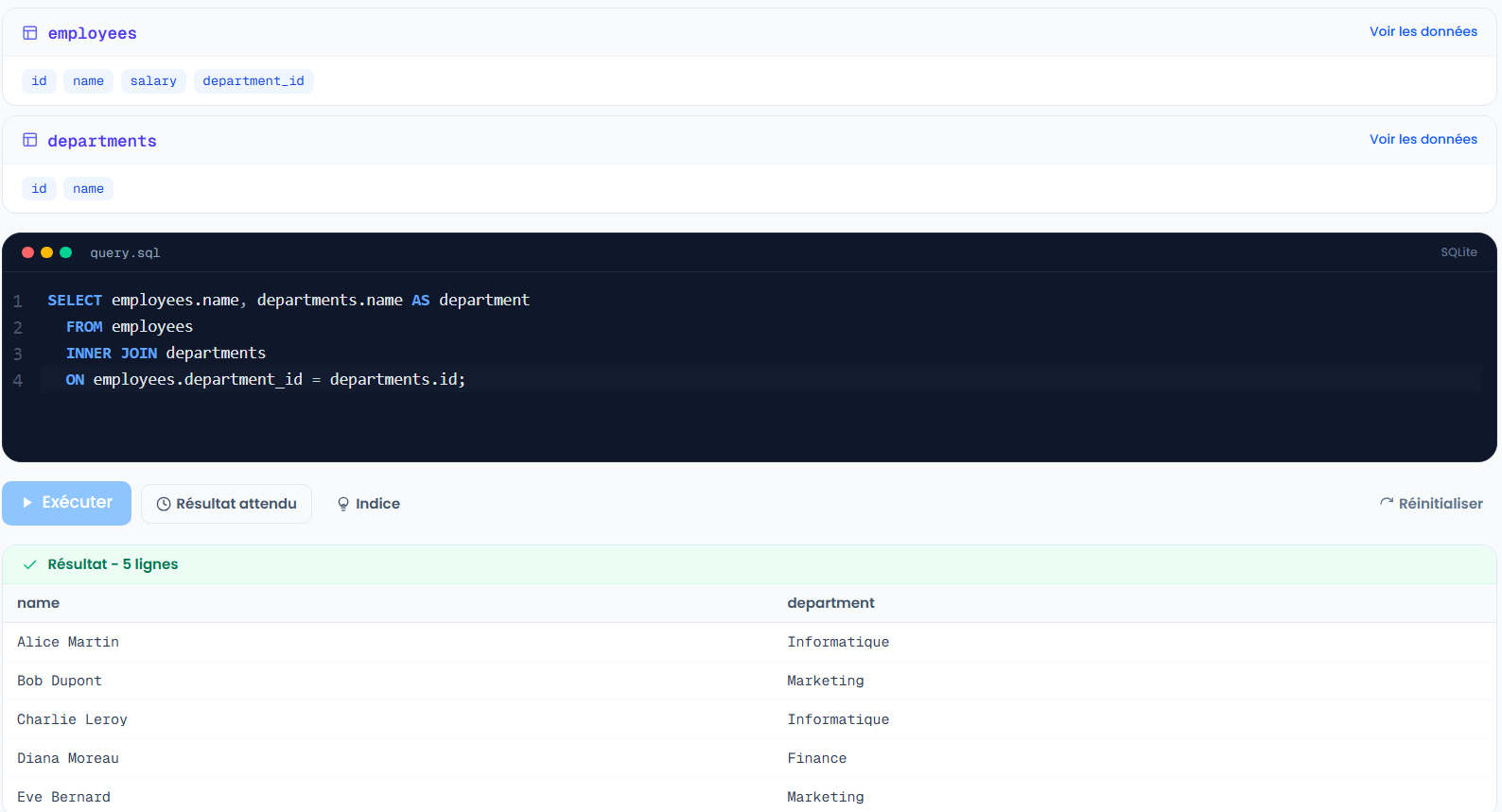
SELECT employees.name, departments.name AS department
FROM employees
INNER JOIN departments
ON employees.department_id = departments.id;
INNER JOIN garde uniquement les lignes qui ont une correspondance des deux côtés. Un employé sans département valide disparaît du résultat.
Les quatre joins de base à connaître :
| Join | Ce qu'il garde |
|---|---|
INNER JOIN |
Seulement les lignes qui matchent des deux côtés |
LEFT JOIN |
Toutes les lignes de gauche, complétées par la droite (NULL si pas de match) |
RIGHT JOIN |
L'inverse du LEFT |
FULL OUTER JOIN |
Toutes les lignes des deux côtés |
Dans 95 % des cas, tu utilises INNER ou LEFT. Le LEFT JOIN est ton ami quand tu veux garder tous les éléments d'une table même sans correspondance (tous les clients, y compris ceux qui n'ont jamais commandé).
SUM te sort un chiffre trois fois trop grand, c'est presque toujours ça.Une fois les joins de base maîtrisés, il y a tout un monde de joins spécialisés (SEMI, ANTI, ASOF, LATERAL) qui résolvent des cas que les joins classiques galèrent à traiter. Je les détaille ici : JOINs spécialisés en SQL : SEMI, ANTI, ASOF, LATERAL et FULL OUTER.
💡 À toi de jouer : Premier INNER JOIN (jo-01).
5. La logique conditionnelle et les NULL : CASE, COALESCE
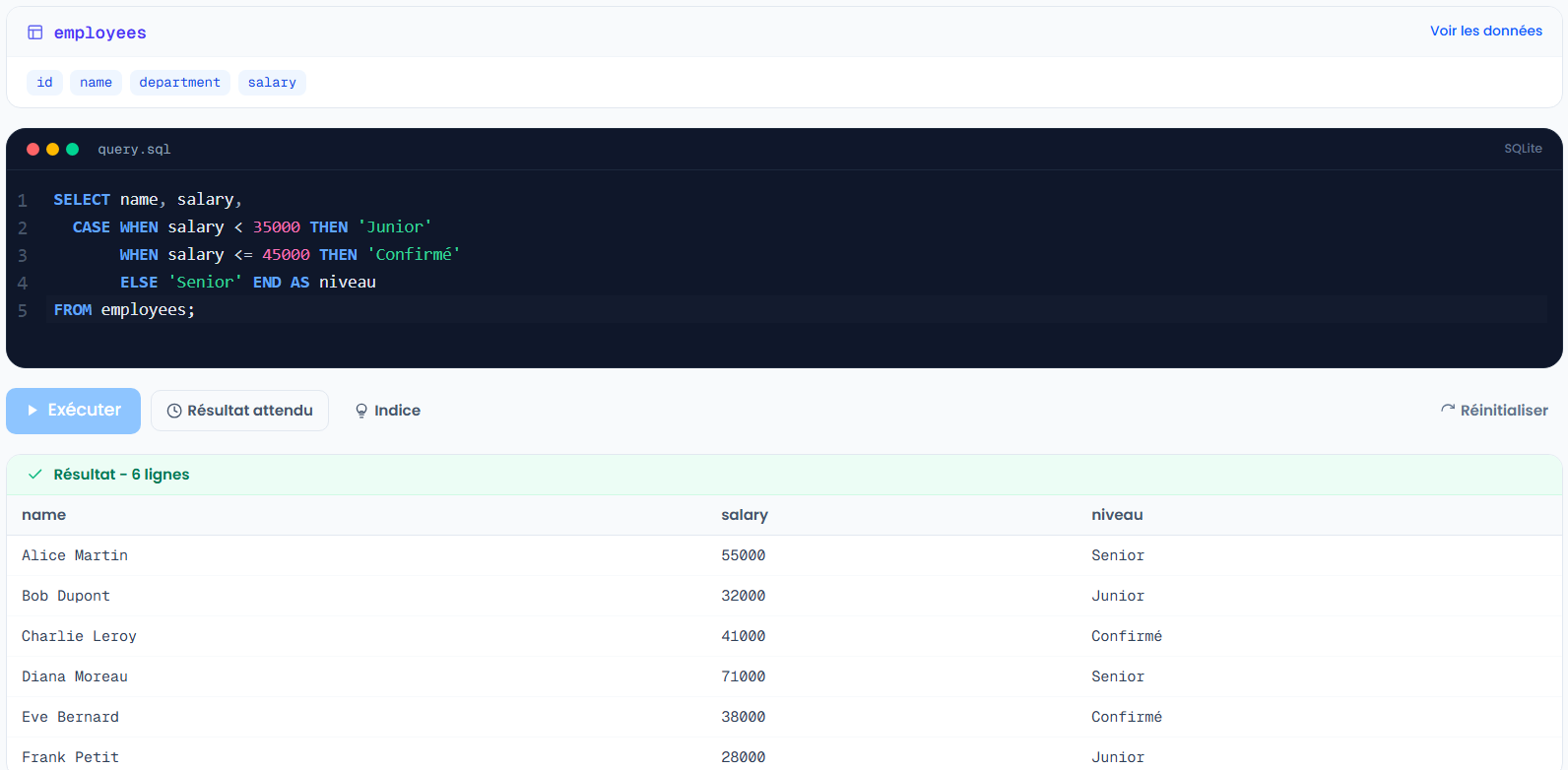
CASE est le if/else du SQL. Il crée une colonne dont la valeur dépend de conditions.
SELECT name, salary,
CASE
WHEN salary < 35000 THEN 'Junior'
WHEN salary <= 45000 THEN 'Confirmé'
ELSE 'Senior'
END AS niveau
FROM employees;
Les conditions sont évaluées dans l'ordre, et la première qui est vraie gagne. ELSE ramasse tout le reste. C'est l'outil que tu utilises pour transformer de la donnée brute en catégories métier.
COALESCE, lui, gère les NULL. Il prend une liste de valeurs et renvoie la première qui n'est pas nulle :
SELECT name, COALESCE(phone, 'Non renseigné') AS telephone
FROM employees;
Si phone est NULL, tu affiches "Non renseigné" au lieu d'une case vide. Indispensable dès que tu prépares des données pour un dashboard car des fois un NULL qui traîne dans un rapport, c'est moche et ça fausse les calculs.
💡 À toi de jouer : Premier CASE WHEN (cc-01) puis COALESCE : remplacer les NULL (cc-03).
6. Structurer ses requêtes : sous-requêtes et CTE
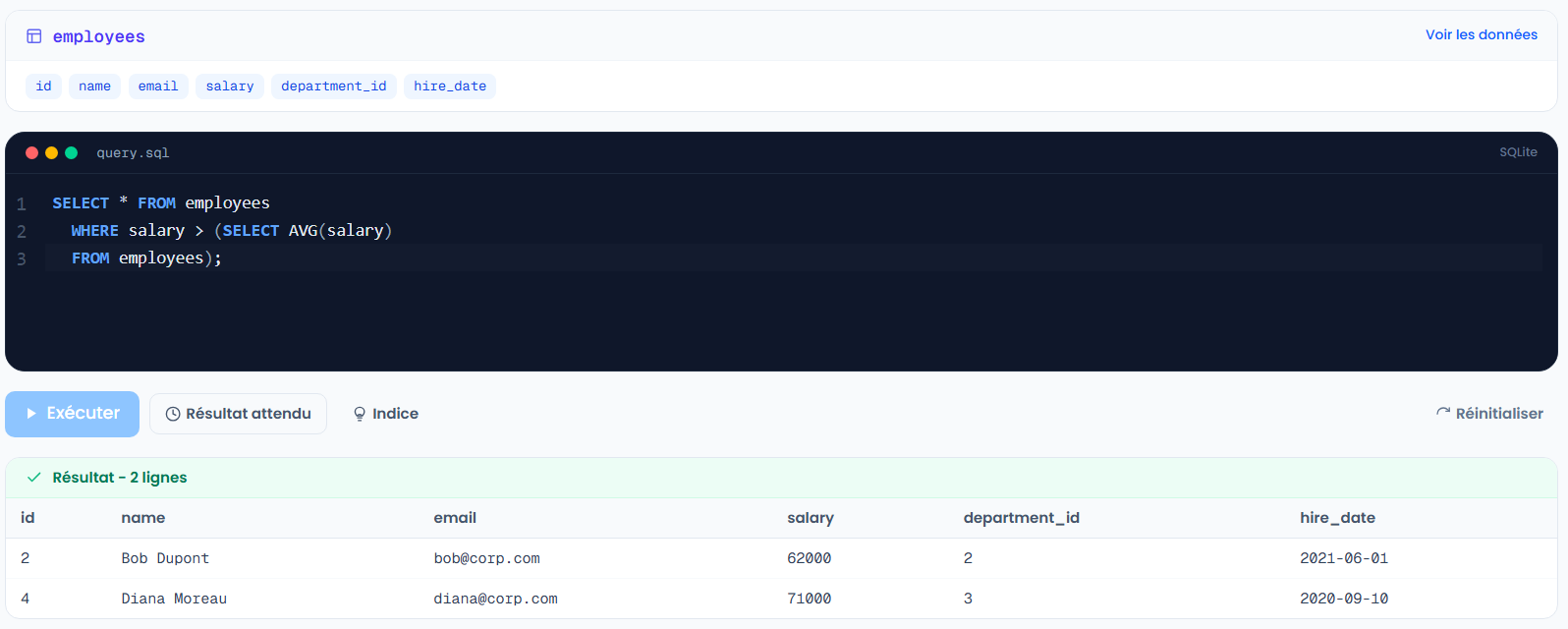
Une sous-requête, c'est une requête à l'intérieur d'une autre. Le cas le plus courant est de comparer chaque ligne à un calcul global.
SELECT *
FROM employees
WHERE salary > (SELECT AVG(salary) FROM employees);
La sous-requête calcule le salaire moyen, et la requête principale garde les employés au-dessus. La base exécute d'abord la parenthèse, puis le reste.
Le problème des sous-requêtes, c'est qu'empilées, elles deviennent illisibles. C'est là qu'arrivent les CTE (Common Table Expressions). Tu déclares une sous-requête nommée avec WITH, puis tu l'utilises comme si c'était une table :
WITH hauts_salaires AS (
SELECT * FROM employees WHERE salary > 50000
)
SELECT * FROM hauts_salaires;
Même résultat qu'une sous-requête, mais ta logique est découpée en blocs nommés que tu lis de haut en bas. Sur une requête complexe, c'est le jour et la nuit. Je compare les deux approches en détail dans CTE vs table dérivée en SQL.
💡 À toi de jouer : Salaire supérieur à la moyenne (sq-01) puis Premier CTE simple (ct-01).
7. Le palier au-dessus : les window functions
Dernier fondamental avant le niveau avancé, et le plus puissant. Une window function calcule sur un groupe de lignes sans les fusionner. Contrairement à GROUP BY qui réduit dix lignes en une, elle garde tes dix lignes et ajoute une colonne calculée.
SELECT name, salary,
ROW_NUMBER() OVER (ORDER BY salary DESC) AS rang
FROM employees;
Chaque employé garde sa ligne, et reçoit en plus son rang de salaire. C'est ce qui débloque les classements, les totaux cumulés, les comparaisons d'une ligne à la précédente, la déduplication propre etc..
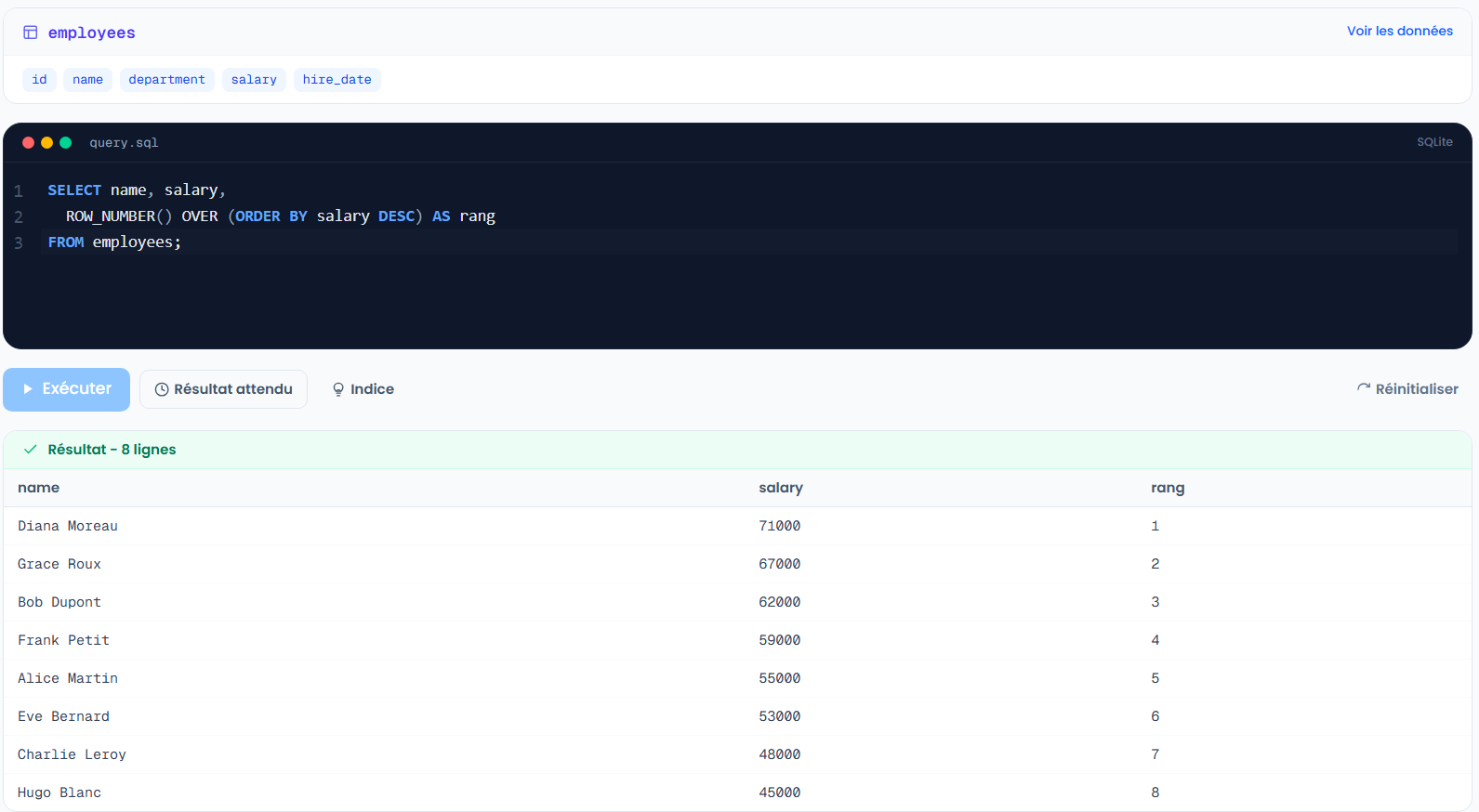
Les window functions méritent un article à elles seules : Window Functions SQL : OVER, PARTITION BY, ROW_NUMBER, LAG (8 exemples).
Commence par l'exercice ci-dessous, puis enchaîne avec l'article quand tu veux aller plus loin.
💡 À toi de jouer : Numéroter les employés (wf-01).
Quelques bonnes pratiques à adopter
Du SQL qui marche, c'est bien. Du SQL que ton toi du futur (ou ton collègue) relit sans souffrir, c'est mieux. Quelques habitudes qui font la différence :
SELECT *en production. Pratique pour explorer, mais en prod tu récupères des colonnes inutiles. Nomme tes colonnes.- Empiler les sous-requêtes. Pour une requête lisible et maintenable, privilégie les CTE.
- L'ancienne syntaxe de jointure
FROM a, b WHERE a.id = b.id. Ça marche, mais c'est illisible, et un oubli de condition te fait un produit cartésien. Écris desJOIN ... ONexplicites. - Le
GROUP BY 1, 2par numéro de colonne. Rapide à taper, fragile à maintenir car dès que tu changes l'ordre duSELECT, le regroupement change en silence. Nomme les colonnes. - Les alias cryptiques comme
AS ca,AS t1,AS xte font gagner trois secondes et en perdre dix au relecteur. Donne des noms parlants. - La logique dupliquée. Si tu copies-colles le même bloc de calcul deux fois, factorise-le dans une CTE. Une seule source de vérité, une seule chose à corriger.
Comment vraiment progresser
Lire ce guide te donne la carte. Mais le SQL ne s'apprend pas en lisant, il s'apprend en écrivant des requêtes en se trompant, et le plus important en comprenant pourquoi. C'est exactement pour ça que j'ai construit le SQL Lab, un éditeur intégré au navigateur, des exercices progressifs, et une validation automatique qui te dit tout de suite si ta requête est juste. Rien à installer.
Quand tu seras à l'aise avec ces fondamentaux, deux directions :
- Le Lab Analytics Engineering pour appliquer le SQL à des workflows complets : modélisation, qualité de données, déduplication, SCD, incrémental, cohortes.
- Mes articles avancés sur les window functions, les joins spécialisés, le MERGE et les SCD.
Tu veux que je t'accompagne sur un projet data (modélisation, performance SQL, Snowflake, dbt, gouvernance) ?
👉 Réserver un appel de 30 minutes
Questions fréquentes
Combien de temps faut-il pour apprendre le SQL ?
Les bases (SELECT, WHERE, ORDER BY, agrégations, JOINs) s'acquièrent en quelques jours de pratique régulière. Tu es opérationnel sur des requêtes utiles en une à deux semaines. La maîtrise des sujets avancés (window functions, optimisation, CTE récursives) demande plus de temps, mais tu peux déjà travailler sérieusement avec les fondamentaux.
Par où commencer pour apprendre SQL quand on débute ?
Commence par comprendre l'ordre d'exécution d'une requête, puis SELECT, WHERE et ORDER BY. Ajoute ensuite les agrégations (COUNT, SUM, AVG, GROUP BY), puis les JOINs. C'est l'ordre suivi dans ce guide et dans le SQL Lab. Le plus important est de pratiquer en écrivant des requêtes, pas seulement en lisant.
Faut-il installer une base de données pour apprendre SQL ?
Non. Tu peux écrire et exécuter des requêtes directement dans le navigateur avec le SQL Lab de DataCertification, sans installer PostgreSQL, MySQL ou SQLite. C'est la façon la plus rapide de commencer à pratiquer.
Quelle est la différence entre WHERE et HAVING ?
WHERE filtre les lignes avant le regroupement. HAVING filtre les groupes après le GROUP BY. On utilise HAVING quand la condition porte sur un résultat d'agrégation, comme garder uniquement les départements dont le salaire moyen dépasse un seuil.
Le SQL est-il utile pour un data analyst ou un data engineer ?
Oui, c'est la compétence de base des deux métiers. Un data analyst écrit des requêtes pour explorer et restituer la donnée, un data engineer construit des pipelines de transformation en SQL. Quel que soit l'outil (Snowflake, BigQuery, dbt, Power BI), tout repose sur SQL.
Quelle différence entre SELECT * et nommer les colonnes ?
SELECT * retourne toutes les colonnes, pratique pour explorer une table. En production, on nomme les colonnes pour ne avoir que ce dont on a besoin.
