

Depuis le début de la formation, on a appris à dbt où trouver les données avec les sources, puis à les nettoyer dans le staging. Ces données arrivent d'un système externe (un ERP, un CRM, un outil d'ingestion) et dbt ne fait que les lire.
Mais il y a une autre catégorie de données. Des petites tables de référence qui n'ont pas de système source comme par exemple une correspondance entre un code statut et son libellé, une liste de pays ou un fichier de mapping.
C'est quoi un seed
Un seed, c'est un fichier CSV qu'on place dans le projet dbt, et que dbt charge dans l'entrepôt avec une commande. Une fois chargé, c'est une table comme une autre, qu'on référence avec ref().
La différence avec une source est simple :
- Une source, c'est une table déjà présente dans Snowflake par exemple. dbt la lit, il ne la crée pas.
- Un seed, c'est un CSV qui vit dans ton dépôt Git, et que c'est dbt qui charge.
Quand utiliser un seed (et quand surtout pas)
C'est le point à bien comprendre, parce que c'est là qu'on fait des bêtises.
Un seed est fait pour de la petite donnée de référence, qui ne bouge pas dans le temps ou trés rarement, et qu'on veut maintenir à la main, par exemple :
- Une table de mapping des libellés des codes pays.
- Une liste fermée (les jours fériés ou une liste de comptes de test à exclure)
Un seed n'est pas fait pour :
- De la vraie donnée métier qui arrive d'un système (ça, c'est une source)
- Des gros volumes. Un CSV de millions de lignes dans Git, c'est non.
- De la donnée qui change souvent. Car dans ce cas, il faut une source et pas un seed.
Notre premier seed
On reprend le projet. Dans stg_orders, on a une colonne statut qui vaut completed ou pending mais on veut leur associer un libellé propre et un indicateur pour dire si la commande est payée ou non.
Cette correspondance n'a aucune source, c'est une décision métier. Donc un seed.
Au niveau du dossier seeds/ à la racine du projet on va créer le fichier statuts_commande.csv :
statut,libelle,est_paye
completed,Terminée,true
pending,En attente,false
cancelled,Annulée,false
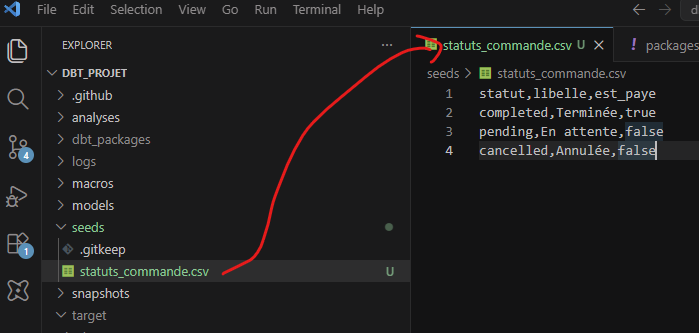
On ajoute même cancelled, qui n'existe pas encore dans nos commandes mais qu'on anticipe. Un seed peut contenir plus de valeurs que la donnée réelle, ce n'est pas un souci.
Maintenant, on charge le fichier :
dbt seed
dbt lit le CSV, crée une table statuts_commande dans le schéma dev, et insère les trois lignes. Va voir dans Snowsight, déplie ANALYTICS > DEV pour la table avec son contenu.
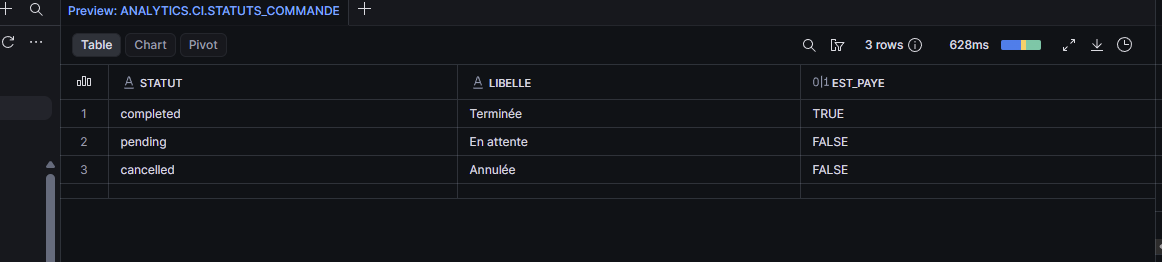
dbt seed est la commande qui charge les CSV.Brancher le seed à un modèle avec ref()
Un seed se référence exactement comme un modèle, avec ref(). Pas de source() ici, puisque c'est dbt qui a créé la table.
Crée un modèle models/marts/mart_orders_enrichi.sql qui joint les commandes à leur libellé :
with commandes as (
select * from {{ ref('stg_orders') }}
),
statuts as (
select * from {{ ref('statuts_commande') }}
)
select
c.order_id,
c.customer_id,
c.montant,
c.statut,
s.libelle as statut_libelle,
s.est_paye
from commandes c
left join statuts s
on c.statut = s.statut
Lance le build de ce modèle :
dbt run --select mart_orders_enrichi
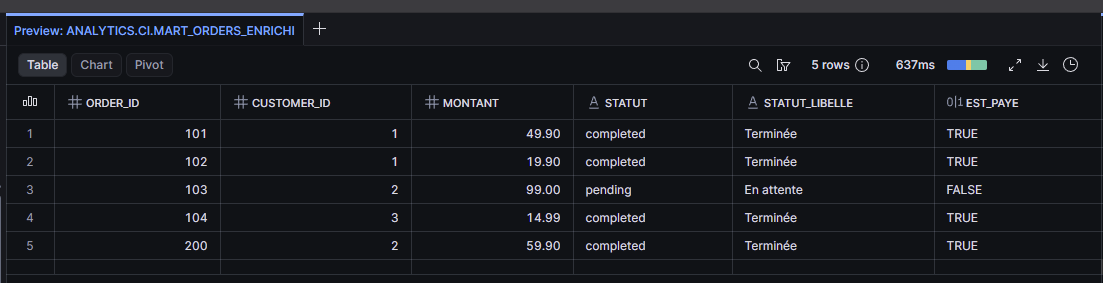
dbt sait que mart_orders_enrichi dépend du seed et du staging, grâce aux deux ref().
Forcer les types avec column_types
Un piège classique des seeds. Par défaut, dbt devine le type de chaque colonne à partir du contenu du CSV. La plupart du temps ça marche, mais parfois il se trompe, par exemple un code postal 01000 qu'il transforme en nombre 1000, ou notre est_paye qu'on veut en booléen et pas en texte.
Pour ne rien laisser au hasard, on déclare les types dans le dbt_project.yml :
seeds:
dbt_projet:
statuts_commande:
+column_types:
statut: varchar
libelle: varchar
est_paye: boolean
Au prochain dbt seed, dbt crée la table avec exactement ces types.
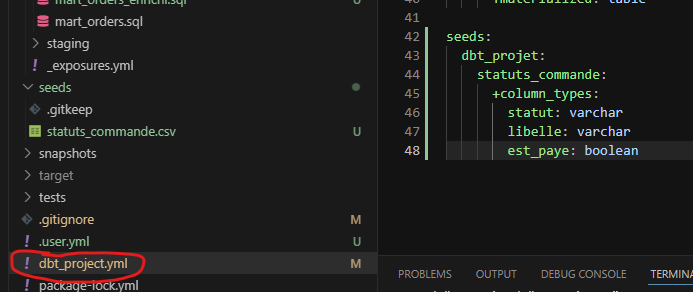
Le bloc seeds: dans dbt_project.yml fonctionne comme le bloc models: qu'on a vu pour les matérialisations. On peut configurer un seed précis (comme ici) ou tout un dossier de seeds d'un coup.
Documenter et tester un seed
Un seed est une table dbt à part entière, donc il a droit à sa description et à ses tests, exactement comme un modèle. On reprend la logique du fichier de propriétés qu'on a vue pour les tests et la doc.
Crée seeds/_seeds.yml :
version: 2
seeds:
- name: statuts_commande
description: "Référentiel des statuts de commande"
columns:
- name: statut
description: "Code du statut."
data_tests:
- unique
- not_null
- name: est_paye
description: "Vrai si le statut correspond à une commande payée."
data_tests:
- not_null
Au prochain dbt test, dbt vérifie que le code statut est unique et non nul dans le référentiel. Un doublon dans le CSV serait identifié rapidement.
Et on peut aller un cran plus loin. Souviens-toi du test relationships de l'article sur les tests. On peut vérifier que chaque statut présent dans les commandes existe bien dans le référentiel. Sur stg_orders, dans son fichier de propriétés :
- name: statut
data_tests:
- relationships:
arguments:
to: ref('statuts_commande')
field: statut
Le jour où une commande arrive avec un statut inconnu du référentiel (refunded par exemple), le test échoue, et on sait qu'il faut ajouter une ligne au CSV. Le seed devient la liste de référence officielle.
dbt seed, dbt run, dbt build
Est-ce que les seeds se rechargent tout seuls ?
Non, et c'est important. dbt run ne touche pas aux seeds, il ne construit que les modèles. Si on modifie le CSV, il faut relancer dbt seed pour que la table soit mise à jour.
La bonne nouvelle, c'est que dbt build lui s'occupe de tout dans le bon ordre donc il charge les seeds, construit les modèles, lance les tests et les snapshots. Voir l'article sur le déploiement.
dbt seed recharge toute la table à chaque fois (il la remplace) donc c'est parfait pour les petites tables de référence. Mais ne tente jamais d'utiliser un seed pour de la donnée qui grossit, on rechargerait tout à chaque exécution.Ce qu'on a fait
Récap. de cet article :
- Comprendre la différence entre une source (donnée externe que dbt lit) et un seed (CSV que dbt charge)
- Créer un seed dans
seeds/et le charger avecdbt seed - Brancher le seed à un modèle avec
ref(), sans écrire le mapping en dur - Forcer les types avec
column_typespour éviter les mauvaises surprises - Documenter et tester le seed, et vérifier l'intégrité avec un test
relationships - Retenir que
dbt runignore les seeds, mais quedbt buildles enchaîne
Aller plus loin
Cet article fait partie de la formation dbt complète, du premier modèle au déploiement en production.
👉 Suivre toute la formation dbt
dbt tourne sur Snowflake dans ce parcours. Pour maîtriser le socle (warehouses, rôles, ingestion) :
👉 Accéder à la Formation Snowflake
Et pour t'entraîner en conditions d'examen, la certification dbt Analytics Engineering teste précisément les seeds et la gestion des données de référence.
👉 Préparer la certification dbt sur DataCertification.fr
Tu veux que je t'accompagne sur ton projet data (Snowflake, dbt, modélisation, industrialisation) ?
👉 Réserver un appel de 30 minutes
Questions fréquentes
Quelle différence entre un seed et une source en dbt ?
Une source est une table déjà présente dans l'entrepôt, alimentée par un système externe, que dbt se contente de lire. Un seed est un fichier CSV qui vit dans le projet dbt et que c'est dbt qui charge dans l'entrepôt avec dbt seed.
Où placer le fichier CSV d'un seed ?
Dans le dossier seeds/ à la racine du projet, au même niveau que models/. dbt prend le nom du fichier (sans l'extension) comme nom de table. Un fichier statuts_commande.csv devient une table statuts_commande, qu'on référence ensuite avec ref('statuts_commande').
Comment charger un seed dans Snowflake ?
Avec la commande dbt seed. dbt lit le CSV, crée la table dans le schéma cible et insère les lignes. Si on modifie le CSV, il faut relancer dbt seed pour mettre à jour la table. dbt run ne recharge pas les seeds, mais dbt build les enchaîne automatiquement avant les modèles.
Comment éviter que dbt se trompe sur le type d'une colonne de seed ?
Par défaut, dbt devine les types à partir du contenu du CSV, mais dans certain cas le type peut être faux. Pour fixer ça, on déclare les types dans le dbt_project.yml sous le seed concerné, avec la clé +column_types. dbt crée alors la table avec exactement les types demandés.
Peut-on tester et documenter un seed ?
Oui, un seed est une table dbt à part entière. On lui ajoute une description et des tests dans un fichier de propriétés (unique, not_null sur la clé, par exemple). On peut même tester avec relationships que chaque valeur utilisée dans les modèles existe bien dans le seed, ce qui en fait une vraie liste de référence contrôlée.
Un seed, c'est pour quel volume de données ?
Pour de la petite donnée, quelques lignes à quelques centaines au maximum. Un seed se recharge entièrement à chaque dbt seed et vit dans Git, donc il n'est pas fait pour de gros volumes ni pour de la donnée qui change souvent. Au-delà, c'est le signe qu'il faut une vraie source alimentée par un outil d'ingestion.