

Dans l'article précédent, on a matérialisé les modèles selon leur rôle. Sauf qu'un modèle matérialisé n'est pas un modèle fiable. Une clé en double, une valeur nulle là où il n'en faut pas, une référence qui pointe dans le vide, et tout un dashboard se met à donner des fausses données sans que personne ne s'en aperçoive.
C'est exactement le problème que les tests dbt règlent. On va voir comment vérifier automatiquement que la donnée n'est pas cassée, à chaque exécution, sans écrire une seule requête de contrôle à la main.
Pourquoi tester
La pire chose dans la data, ce n'est pas le pipeline qui plante. Quand il plante, on le voit, on corrige. La pire erreur, c'est le pipeline qui tourne correctement sur de la donnée fausse pendant trois semaines avant que quelqu'un ne remarque que les chiffres sont faux.
Les tests dbt sont le filet de sécurité contre ça. On déclare des règles ("cette colonne ne doit jamais être nulle", "cet identifiant doit être unique"), et dbt les vérifie à chaque dbt test. Si une règle est violée, on est prévenu avant que la donnée n'arrive jusqu'au dashboard.
Les tests génériques (generic tests)
dbt fournit quatre tests prêts à l'emploi, qu'on appelle des tests génériques :
- unique : aucune valeur en double dans la colonne
- not_null : aucune valeur nulle
- accepted_values : la colonne ne contient que des valeurs d'une liste autorisée
- relationships : chaque valeur existe bien dans une autre table (l'intégrité référentielle)
On ne les écrit pas en SQL, on les déclare en YAML. Crée un fichier models/staging/_models.yml :
version: 2
models:
- name: stg_customers
columns:
- name: customer_id
data_tests:
- unique
- not_null
- name: email
data_tests:
- not_null
- name: stg_orders
columns:
- name: order_id
data_tests:
- unique
- not_null
- name: customer_id
data_tests:
- not_null
- relationships:
arguments:
to: ref('stg_customers')
field: customer_id
- name: statut
data_tests:
- accepted_values:
arguments:
values: ['completed', 'pending']
On vient de poser six règles avec la clé client est unique et non nulle, l'email est renseigné, la clé commande est unique et non nulle, chaque customer_id d'une commande existe bien dans les clients, et le statut ne prend que deux valeurs connues.
data_tests (l'ancien mot-clé tests marche encore mais c'est déprécié).Lance les tests :
dbt test
dbt génère une requête SQL pour chaque règle et l'exécute dans Snowflake. Tu obtiens une ligne par test, avec PASS ou FAIL. Sur nos données propres, tout passe.
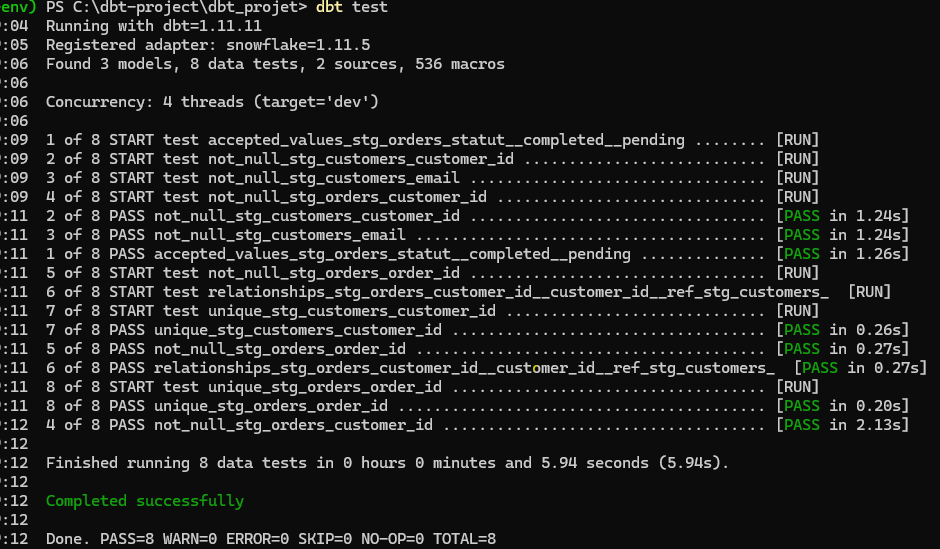
Voir un test échouer
Un test qui passe toujours ne prouve rien. Pour comprendre ce que dbt fait vraiment, on va casser la donnée exprès. Ajoute une commande avec un order_id déjà utilisé :
INSERT INTO raw.orders (order_id, customer_id, amount, status, order_date)
VALUES (101, 2, 29.90, 'completed', '2026-03-15'); -- 101 existe déjà
Relance dbt run puis dbt test. Cette fois, le test unique sur order_id passe en FAIL. dbt t'indique combien de lignes posent problème et te donne le chemin d'une requête compilée que tu peux exécuter pour voir exactement les lignes fautives.
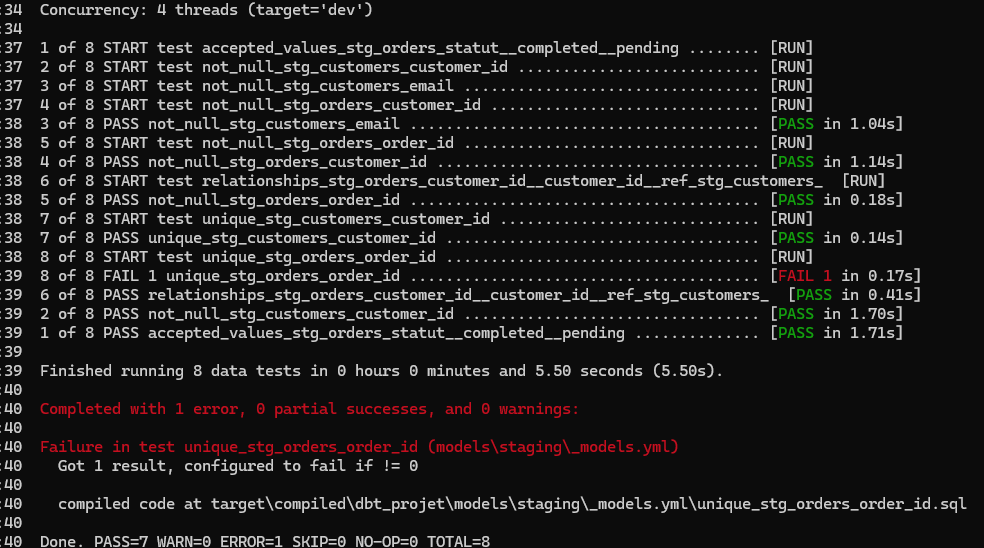
La requête du test :
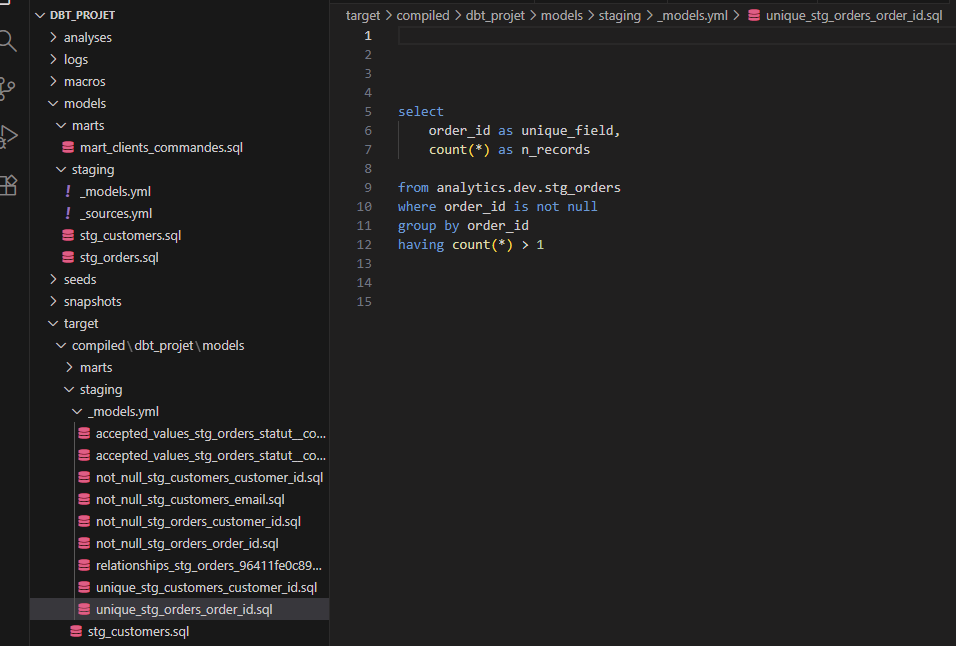
C'est ça la vraie valeur de dbt, pas juste un message d'erreur, mais le moyen d'aller inspecter le problème en deux clics. Une fois que tu as vu le mécanisme, supprime la ligne en double pour repartir propre.
Les tests singuliers (singular tests)
Les tests génériques couvrent les cas courants. Mais parfois on veut tester une règle métier précise, du style "le montant d'une commande ne doit jamais être négatif". Là, on écrit un test singulier.
Le principe est simple. Un test singulier est une requête qui sélectionne les lignes qui ne devraient pas exister. Si la requête ne renvoie rien, le test passe. Si elle renvoie des lignes, c'est qu'il y a un problème, et le test échoue.
Crée tests/assert_montant_positif.sql :
select
order_id,
montant
from {{ ref('stg_orders') }}
where montant <= 0
Au prochain dbt test, dbt exécute cette requête. Tant qu'aucune commande n'a un montant négatif ou nul, elle renvoie zéro ligne et le test passe. Le jour où une commande à 0 € se glisse dans les données, on le sait immédiatement.
Régler la sévérité et garder les échecs
Par défaut, un test qui échoue est une erreur (error) qui fait planter le dbt test. Parfois on veut juste un avertissement sans bloquer. Ça se règle avec un bloc config :
- name: email
data_tests:
- not_null:
config:
severity: warn
Ici, un email manquant lèvera un warn au lieu d'un error. Pratique pour les règles "souhaitables mais pas critiques".
Autre option utile, store_failures donc au lieu de juste compter les lignes en échec, dbt les stocke dans une table que tu peux aller consulter tranquillement.
- unique:
config:
store_failures: true
Quelle stratégie de test adopter
L'erreur classique du débutant, c'est de vouloir tout tester partout. Ça alourdit le projet sans rien apporter. La bonne approche, c'est de tester ce qui casse vraiment, à l'endroit où ça compte :
| Couche | Ce qu'on teste en priorité |
|---|---|
| Staging | unique et not_null sur les clés, accepted_values sur les colonnes à valeurs fermées (statuts, types) |
| Intermédiaire / Marts | relationships entre les tables, et les règles métier en tests singuliers |
Sur chaque modèle, teste au minimum sa clé primaire (unique + not_null). C'est le contrôle qui regroupe le plus de bugs pour le moins d'effort. Le reste, tu l'ajoutes quand une règle métier mérite d'être garantie.
dbt_utils https://hub.getdbt.com/dbt-labs/dbt_utils/latest/ (On verra comment installer et utiliser les packages de la community dans un prochain article)Les modèles sont maintenant matérialisés et testés. Dans le prochain article, on s’occupera de les rendre compréhensibles et on attaquera la documentation et le lineage, pour que ton projet se lise facilement et devienne maintenable.
Aller plus loin
Cet article fait partie de la formation dbt complète, du premier modèle au déploiement en production.
👉 Suivre toute la formation dbt
Pour comprendre comment Snowflake exécute concrètement ces requêtes de test et ce qu'elles consomment, tout est dans le parcours.
👉 Accéder à la formation Snowflake
Et pour t'entraîner sur dbt en conditions d'examen, la certification dbt Analytics Engineering teste précisément les concepts de tests génériques et singuliers.
👉 Préparer la certification dbt sur DataCertification.fr
Tu veux que je t'accompagne sur ton projet data (Snowflake, dbt, modélisation, industrialisation) ?
👉 Réserver un appel de 30 minutes
Questions fréquentes
Tests singuliers et tests unitaires, c'est pareil ?
Non, ce sont deux choses différentes malgré les noms proches. Un test singulier vérifie la donnée réelle avec une requête SQL qui cherche des lignes qui ne devraient pas exister. Un test unitaire vérifie la logique d'un modèle sur des données fictives que tu définis toi-même, en comparant une sortie attendue à la sortie réelle. Le singulier teste tes données, l'unitaire teste ton code. Cet article couvre les tests génériques et singuliers ; les tests unitaires feront l'objet d'un article dédié plus loin dans la série.
Quelle différence entre un test générique et un test singulier en dbt ?
Un test générique est une règle réutilisable déclarée en YAML, comme unique ou not_null, qu'on applique à n'importe quelle colonne. Un test singulier est une requête SQL spécifique, écrite dans le dossier tests, qui cible une règle métier précise. Le générique pour les contrôles standards, le singulier pour les cas particuliers.
Quels sont les tests génériques par défaut de dbt ?
dbt fournit quatre tests prêts à l'emploi : unique (aucun doublon), not_null (aucune valeur nulle), accepted_values (uniquement des valeurs d'une liste autorisée) et relationships (chaque valeur existe bien dans une autre table). Ils se déclarent en YAML sur les colonnes des modèles.
Comment lancer les tests dbt ?
Avec la commande dbt test. dbt transforme chaque règle en requête SQL, l'exécute dans l'entrepôt et renvoie PASS ou FAIL pour chacune. On peut aussi lancer les tests d'un seul modèle avec dbt test --select nom_du_modele.
Que se passe-t-il quand un test dbt échoue ?
dbt indique le nombre de lignes qui violent la règle et fournit le chemin d'une requête compilée pour aller inspecter les lignes fautives. Par défaut un échec est une erreur qui interrompt la commande, mais on peut le passer en simple avertissement avec la config severity, ou stocker les lignes en échec avec store_failures.
Faut-il tester tous les modèles dbt ?
Non, tout tester alourdit le projet sans réel bénéfice. La bonne pratique consiste à tester au minimum la clé primaire de chaque modèle avec unique et not_null, puis à ajouter des tests singuliers métier au cas par cas. On teste ce qui risque vraiment de casser et ce qui est important, pas tout par principe.