

Dans l'article précédent, on a fiabilisé les modèles avec des tests. Ils sont maintenant matérialisés, testés... mais personne ne sait ce que fait mart_clients_commandes à part toi, et encore, dans six mois tu auras oublié.
Un projet dbt qui grossit sans documentation devient une boîte noire. Quelle est cette colonne ? D'où vient cette table ? Qu'est-ce qui casse si je modifie ce modèle ? dbt répond à ces trois questions quasiment gratuitement, à partir de ce que tu as déjà écrit. On va voir comment.
Pourquoi documenter
Soyons honnêtes, la doc personne n'aime la faire et on la repousse toujours, parce qu'on croit que c'est du travail en plus qui ne sert qu'aux autres mais c'est faux sur les deux points.
D'abord, ce n'est pas du travail en plus : dbt génère la documentation à partir des fichiers YAML que tu remplis déjà, et il déduit le graphe des dépendances tout seul à partir de tes ref().
Ensuite, ça ne sert pas qu'aux autres. Le "autre" qui ne comprend plus le projet, dans six mois, c'est toi. Une bonne doc, c'est d'abord un cadeau que tu te fais.
Ajouter des descriptions
On repart du fichier models/staging/_models.yml qu'on a créé pour les tests. On l'enrichit avec des descriptions, au niveau du modèle et au niveau des colonnes :
version: 2
models:
- name: stg_customers
description: "Clients nettoyés depuis la source brute. Un client par ligne."
columns:
- name: customer_id
description: "Identifiant unique du client."
data_tests:
- unique
- not_null
- name: email
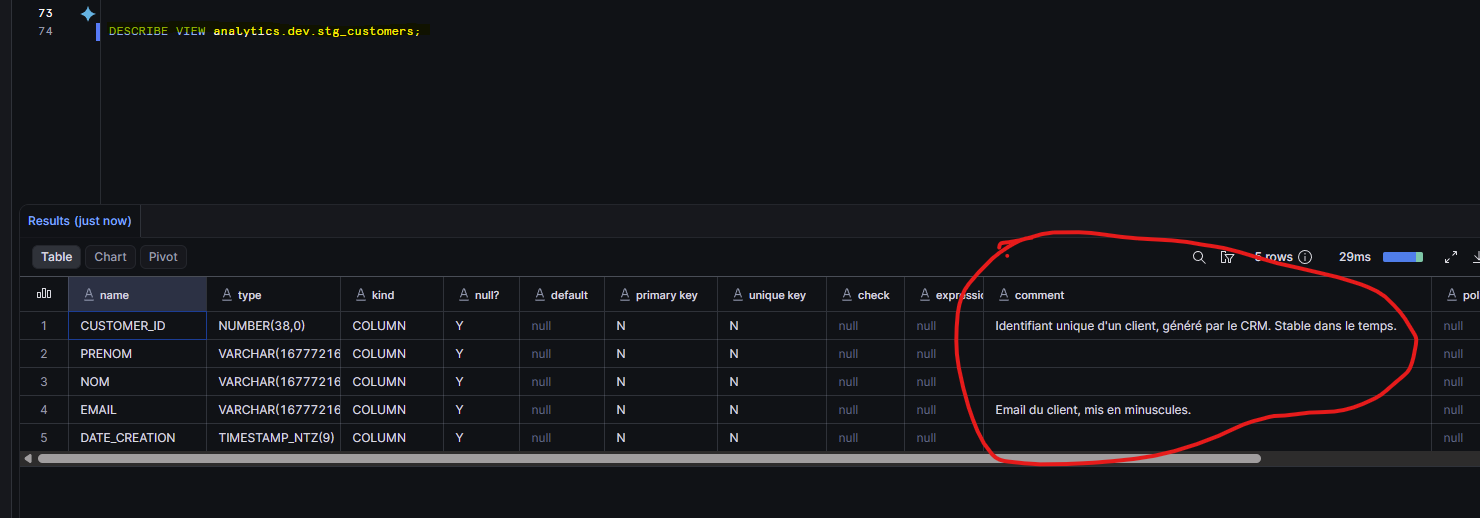
description: "Email du client, mis en minuscules."
data_tests:
- not_null
- name: stg_orders
description: "Commandes nettoyées depuis la source brute. Une commande par ligne."
columns:
- name: order_id
description: "Identifiant unique de la commande."
data_tests:
- unique
- not_null
- name: customer_id
description: "Client qui a passé la commande. Référence stg_customers."
data_tests:
- not_null
- relationships:
arguments:
to: ref('stg_customers')
field: customer_id
- name: statut
description: "Statut de la commande : completed ou pending."
data_tests:
- accepted_values:
arguments:
values: ['completed', 'pending']
Le description cohabite avec les data_tests dans le même fichier. Tests et doc au même endroit et donc ta connaissance du modèle reste à un seul endroit.
Générer et explorer la doc
Deux commandes. La première compile la documentation, la seconde l'expose dans ton navigateur :
dbt docs generate
dbt docs serve
Ton navigateur s'ouvre sur un mini-site. Tu y retrouves la liste de tes modèles, leurs descriptions, leurs colonnes, les tests appliqués, et même le code SQL compilé de chaque modèle. Tout ce que tu as écrit en YAML est là, présenté proprement.
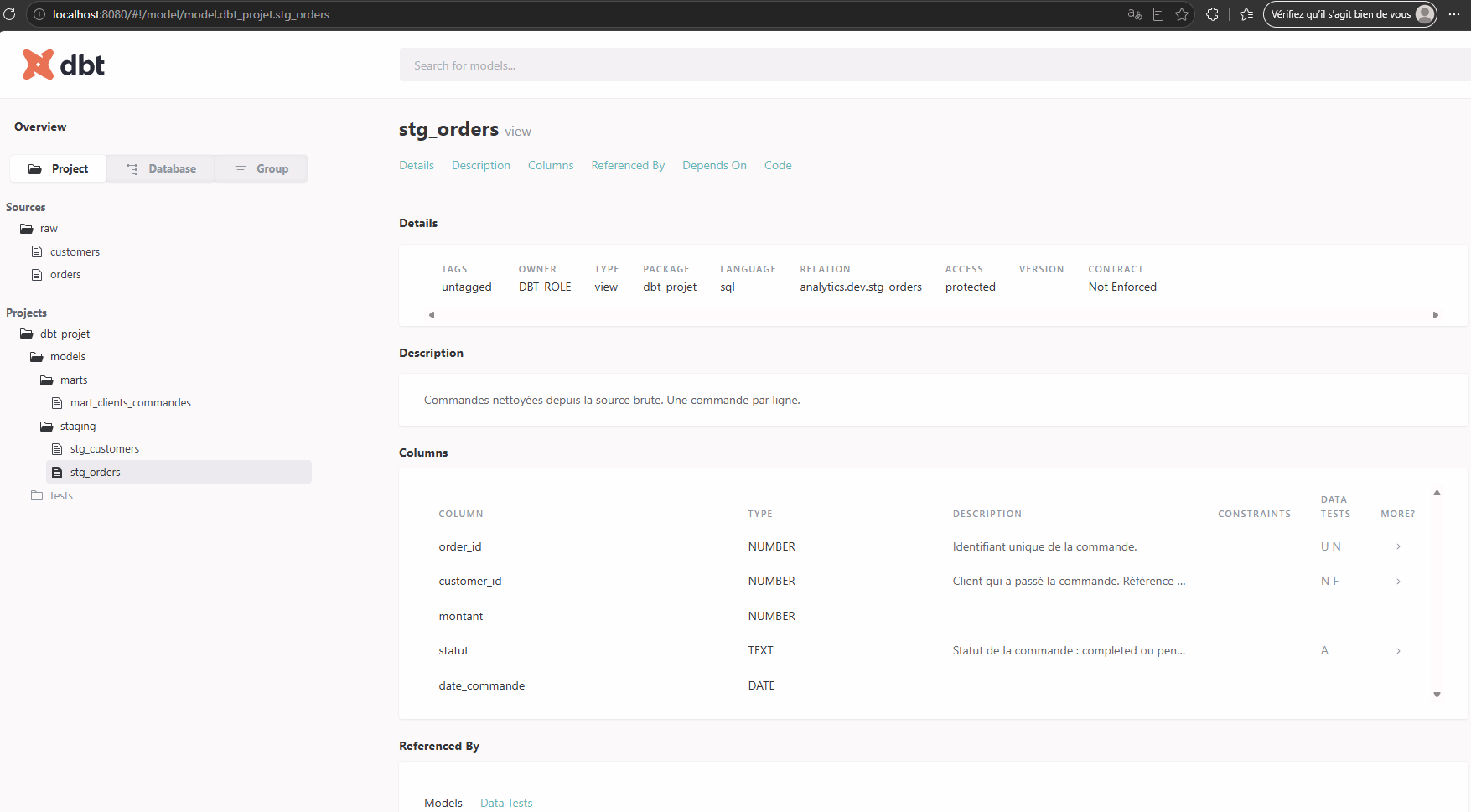
Le data lineage : voir d'où vient la donnée
Le plus important dans la doc, c'est le lineage (le graphe de dépendances, le DAG). En bas à droite du site, une icône ouvre un graphe interactif où tu vois toute la chaîne : tes sources raw, puis les modèles de staging, puis le mart, reliés par des flèches.
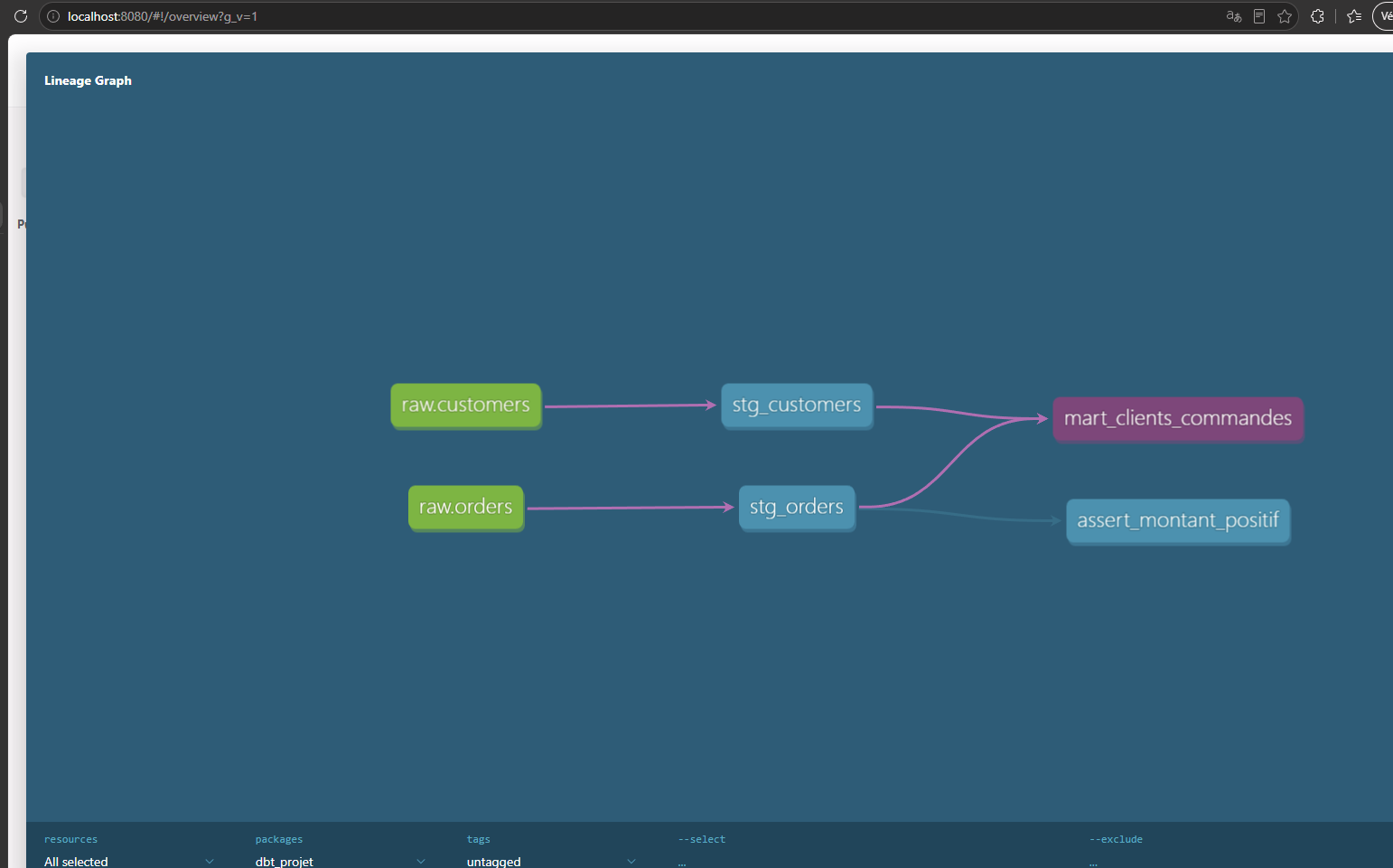
Ce graphe répond à deux questions qu'on se pose tout le temps en vrai :
- "D'où vient cette table ?" Tu remontes les flèches jusqu'à la source.
- "Qu'est-ce qui casse si je modifie
stg_customers?" Tu suis les flèches vers l'aval et tu vois tous les modèles impactés.
Les doc blocks : des descriptions réutilisables
Quand une même description revient sur plusieurs modèles (par exemple la définition d'un customer_id partagé partout), on évite de la recopier. On la définit une fois dans un doc block.
Crée un fichier models/staging/_docs.md :
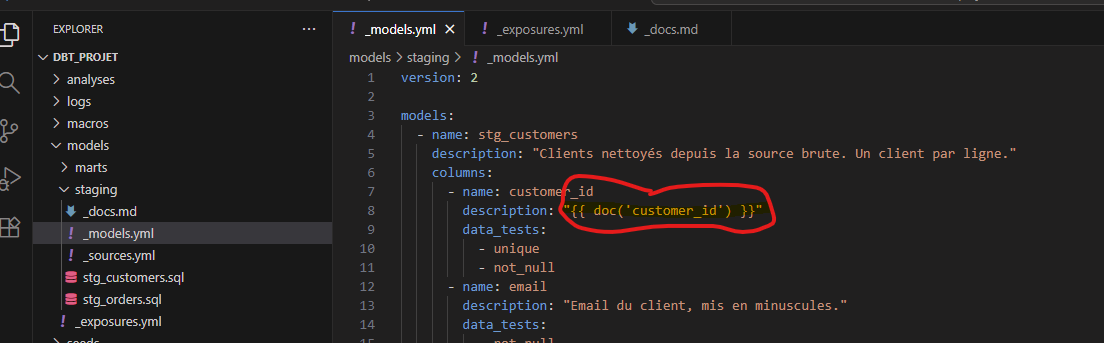
{% docs customer_id %}
Identifiant unique d'un client, généré par le CRM. Stable dans le temps.
{% enddocs %}
Puis dans le YAML, tu appelles ce bloc au lieu d'écrire la description en dur :
- name: customer_id
description: "{{ doc('customer_id') }}"
Une seule source de vérité pour cette définition, réutilisée partout. Le jour où elle change, tu modifies un seul endroit.
Les exposures : relier tes dashboards
Le lineage s'arrête à tes modèles dbt. Mais en réalité, la donnée ne s'arrête pas là car elle finit dans un dashboard, un rapport, une application. Les exposures servent à déclarer ces consommateurs en aval, pour qu'ils apparaissent eux aussi dans le graphe.
Crée models/_exposures.yml :
version: 2
exposures:
- name: dashboard_qlik_commandes
type: dashboard
maturity: high
url: https://url.qlikcloud.com/app/dashboard-clients
description: "Suivi des clients et de leurs commandes, consommé par l'équipe CRM."
depends_on:
- ref('mart_clients_commandes')
owner:
name: "Equipe BI (PO : <nom_du_po>)"
email: support@email.com
Au prochain dbt docs generate, le dashboard apparaît dans le lineage, en bout de chaîne.
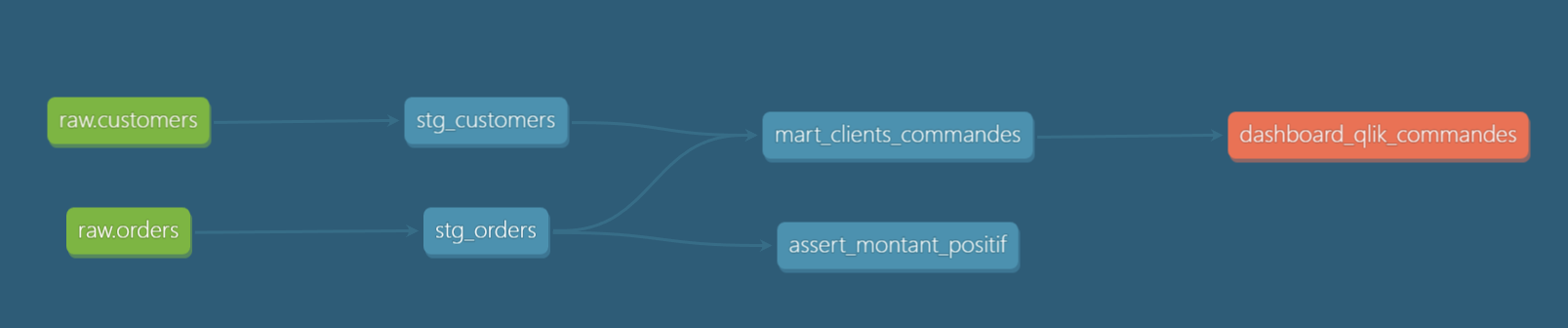
Le jour où tu veux modifier mart_clients_commandes, tu vois immédiatement dans le graphe que ton dashboard qlik des commandes en dépend, et donc qu'il faut prévenir l'équipe avant de toucher quoi que ce soit.
Bonus Snowflake : pousser la doc dans Snowsight
Tes descriptions vivent dans la doc dbt. Mais on peut aussi les pousser directement dans Snowflake, comme des commentaires sur les tables et les colonnes.
Dans le dbt_project.yml, ajoute :
models:
dbt_projet:
+persist_docs:
relation: true
columns: true
Au prochain dbt run, dbt écrit tes descriptions comme COMMENT sur les tables et les colonnes Snowflake. La doc suit la donnée, où qu'elle soit regardée.
DESCRIBE VIEW analytics.dev.stg_customers;
La suite ?
Récap. de ce qu'on a fait :
- Ajouter des descriptions sur les modèles et les colonnes dans le YAML
- Générer et explorer le site de documentation avec
dbt docs generateetdbt docs serve - Lire le lineage pour voir d'où vient la donnée et ce qui dépend de quoi
- Factoriser les descriptions répétées avec les doc blocks
- Relier un dashboard au pipeline avec une exposure
- Pousser la doc jusque dans Snowflake avec
persist_docs
Le projet est maintenant structuré, matérialisé, testé et documenté. C'est un vrai projet dbt complet. Dans le prochain article, on passe à la dernière brique des fondamentaux et c'est le déploiement, pour faire tourner tout ça proprement en prod avec un workflow Git et la commande dbt build.
Aller plus loin
Cet article fait partie de la formation dbt complète, du premier modèle au déploiement en production.
👉 Suivre toute la formation dbt
Pour relier tout ça à ce qui se passe côté Snowflake (où sont stockées les tables, comment lire les métadonnées), tout est dans le parcours.
👉 Accéder à la Formation Snowflake
Et pour t'entraîner sur dbt en conditions d'examen, la certification dbt Analytics Engineering teste précisément la documentation, le lineage et les exposures.
👉 Préparer la certification dbt sur DataCertification.fr
Tu veux que je t'accompagne sur ton projet data (Snowflake, dbt, modélisation, industrialisation) ?
👉 Réserver un appel de 30 minutes
Questions fréquentes
Comment générer la documentation dbt ?
Avec deux commandes. dbt docs generate compile la documentation à partir des fichiers YAML et du catalogue de la base. dbt docs serve ouvre ensuite le site de documentation dans le navigateur. On y retrouve les modèles, leurs colonnes, les descriptions, les tests et le code compilé.
C'est quoi le lineage (DAG) en dbt ?
Le lineage est le graphe des dépendances de ton projet : il montre comment la donnée circule des sources brutes jusqu'aux modèles finaux, en suivant les ref() et les source(). C'est le même graphe que dbt utilise pour ordonner les exécutions. Il sert à voir d'où vient une table et ce qui serait impacté si on la modifie.
À quoi servent les exposures en dbt ?
Une exposure déclare un consommateur des données en aval de tes modèles, comme un dashboard qlik, un rapport ou une application etc... Une fois déclarée, elle apparaît dans le lineage, en bout de chaîne. Ça permet de savoir immédiatement quels outils métier dépendent d'un modèle avant de le modifier, et donc d'éviter de casser un dashboard sans le savoir.
Comment afficher les descriptions dbt directement dans Snowflake ?
Avec la config persist_docs dans le dbt_project.yml. En activant relation et columns, dbt écrit les descriptions comme des commentaires sur les tables et les colonnes lors du dbt run. Les descriptions deviennent alors visibles directement dans Snowsight, sans ouvrir la documentation dbt.
Faut-il documenter tous les modèles dbt ?
Oui. Au minimum, il faut documenter chaque modèle sur ce qu'il représente, et les colonnes qui ne sont pas évidentes. Les clés et les colonnes au nom explicite peuvent rester sans description. L'objectif n'est pas de tout commenter si c'est évident, mais que quelqu'un qui découvre le projet comprenne le rôle de chaque modèle sans lire le SQL.