
Dans les articles précédents, on a vu comment déposer des fichiers sur un stage, définir un file format, puis charger les données en table avec COPY.
Ça marche très bien quand tes fichiers ressemblent à une table.
Sauf que, dans la vraie vie, tu récupères souvent :
- Du semi-structuré (JSON, Parquet, XML etc ....) donc il y a une structure, mais elle varie.
- Du non structuré (PDF, images, audio etc ...).
Snowflake gère les deux, mais pas avec la même logique.
1) Données semi-structurées
Le type VARIANT est la porte d’entrée la plus simple, car tu charges ton JSON (et plus largement du semi-structuré comme Parquet, XML etc...), "tel quel" puis tu utilises SQL pour lire les données.
Ce qui est intéressant, c'est que Snowflake ne stocke pas tout ça comme un gros blob illisible mais quand tu insères du semi-structuré dans une colonne VARIANT, Snowflake applique des règles de subcolumnarization pour extraire un maximum d'éléments afin que ça reste requêtable efficacement. Le reste est conservé dans une structure semi-structurée parsée.
Mais sans s’en douter, il y a des limites car par défaut, Snowflake extrait au maximum 200 éléments par partition (micro-partition), par table. Si tu veux augmenter cette limite, ça passe par le support Snowflake.
Exemple concret : charger du JSON dans une table
Comme d'habitude rien de mieux qu'un exemple pour comprendre le concept.
On part d'un stage, et d’un file format JSON. Puis on charge les données dans une table avec une colonne VARIANT.
CREATE OR REPLACE FILE FORMAT FF_JSON
TYPE = JSON;
CREATE OR REPLACE STAGE STG_EVENTS
FILE_FORMAT = FF_JSON;
(Ensuite on import le fichier events.json dans @STG_EVENTS avec un PUT)
{"event_id":"evt_0001","event_time":"2026-01-12T10:14:22Z","event_type":"order_created","customer":{"id":"c_1029","country":"FR"},"order":{"order_id":123,"channel":"web","currency":"EUR"},"amount":"129.90","items":[{"sku":"A1","qty":2,"unit_price":"39.95"},{"sku":"B7","qty":1,"unit_price":"49.00"}],"metadata":{"source":"app","ip":"192.0.2.10"}}
{"event_id":"evt_0002","event_time":"2026-01-12T10:18:01Z","event_type":"order_paid","customer":{"id":"c_1029","country":"FR"},"order":{"order_id":123,"payment_method":"card","currency":"EUR"},"amount":129.90,"items":[{"sku":"A1","qty":2,"unit_price":39.95},{"sku":"B7","qty":1,"unit_price":49.00}],"metadata":{"source":"web"}}
{"event_id":"evt_0003","event_time":"2026-01-12T11:02:44Z","event_type":"order_shipped","customer":{"id":"c_2044","country":"BE"},"order":{"order_id":124,"carrier":"DHL","tracking":"JD000225566","currency":"EUR"},"items":[{"sku":"C3","qty":1,"unit_price":"19.99"}],"metadata":{"source":"ops","warehouse":"WH-2"}}
{"event_id":"evt_0004","event_time":"2026-01-12T12:30:05Z","event_type":"order_created","customer":{"id":"c_7777","country":"FR"},"order":{"order_id":125,"channel":"mobile","currency":"EUR"},"amount":"59.00","items":[],"metadata":{"source":"app"}}
{"event_id":"evt_0005","event_time":"2026-01-12T13:05:11Z","event_type":"order_created","customer":{"id":"c_8888","country":"ES"},"order":{"order_id":126,"channel":"web","currency":"EUR"},"amount":"not_a_number","items":[{"sku":"Z9","qty":"1","unit_price":"9.99"}],"metadata":{"source":"web","note":"bad amount/qty types"}}
C'est possible de l'importer avec snowsight

On garde le payload brut
CREATE OR REPLACE TABLE RAW_EVENTS (
payload VARIANT,
load_ts TIMESTAMP_NTZ DEFAULT CURRENT_TIMESTAMP()
);
On charge le JSON dans VARIANT
COPY INTO RAW_EVENTS(payload)
FROM (SELECT $1 FROM @STG_EVENTS)
FILE_FORMAT = (FORMAT_NAME = 'FF_JSON');
C'est la magique du variant à ce stade on ne va pas s'occuper des types du Schéma.
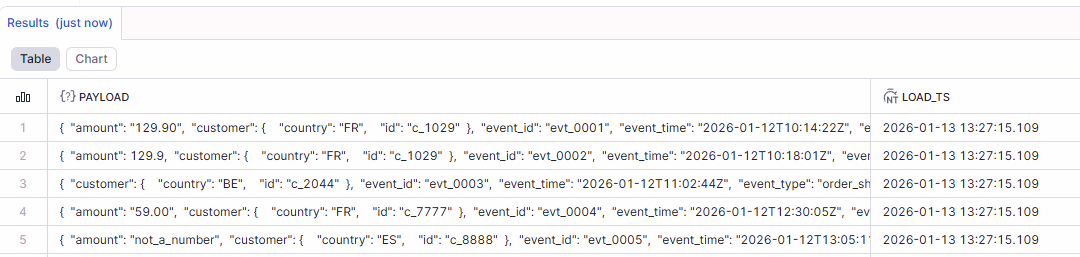
Lire un champ dans un VARIANT
Tu accèdes aux champs avec la notation JSON (souvent :), puis un cast avec le type du champ
SELECT
payload:event_id::STRING AS event_id,
payload:event_time::TIMESTAMP_NTZ AS event_time,
payload:customer:id::STRING AS customer_id,
payload:event_type::STRING AS event_type
FROM RAW_EVENTS;
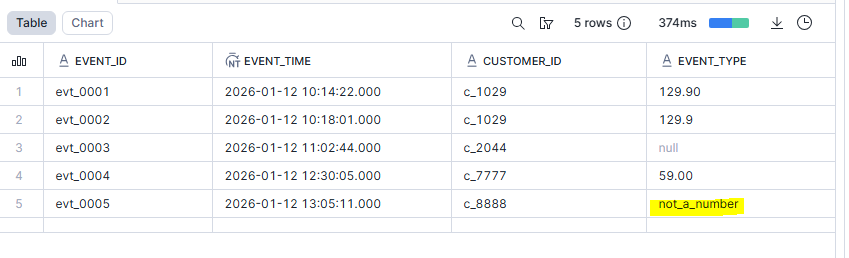
Comme on voit dans la capture ci-dessus on tombe souvent sur des champs manquants ou mal typés et l'utilisation de TRY_ peut être pratique dans certain cas :
SELECT
payload:event_id::STRING AS event_id,
TRY_TO_TIMESTAMP_NTZ(payload:event_time::STRING) AS event_time,
payload:customer:id::STRING AS customer_id,
TRY_TO_NUMBER(payload:amount::STRING) AS amount
FROM RAW_EVENTS;
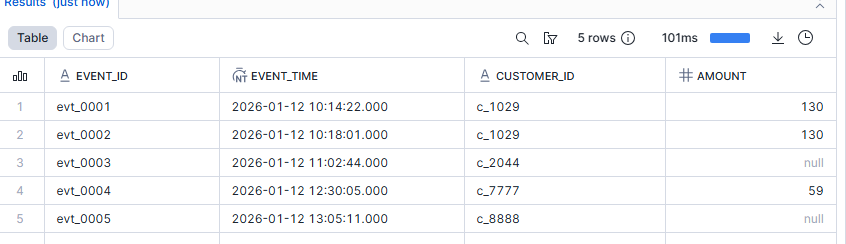
Quand tu as des structures imbriquées, tu continues à descendre pareil. Et si tu as des tableaux (arrays), on peut utiliser la fonction FLATTEN
{
........
"order": {
"order_id": 123,
"channel": "web",
"currency": "EUR"
},
"amount": "129.90",
"items": [
{
"sku": "A1",
"qty": 2,
"unit_price": "39.95"
},
{
"sku": "B7",
"qty": 1,
"unit_price": "49.00"
}
],
.......
}
Pour récupérer les items
SELECT
e.payload:order:order_id::NUMBER AS order_id,
f.value:sku::STRING AS sku,
f.value:qty::NUMBER AS qty
FROM RAW_EVENTS e,
LATERAL FLATTEN(input => e.payload:items) f;
FLATTEN explose tout simplement un ARRAY/OBJECT/VARIANT en plusieurs lignes
2) Données non structurées
Non structuré = PDF, images, audio.. donc ici, l'objectif n'est pas de transformer les fichiers en lignes tout de suite. L'objectif, c'est :
- Stocker les fichiers dans un stage
- Avoir un catalogue de ces fichiers
- Générer des URLs sécurisées pour y accéder (et éventuellement partager ces URLs)
- Utiliser ces fichiers en data science ou en IA (je vais dédier un article à ce sujet prochainement 😉)
C’est exactement le rôle des directory tables sur un stage.
Exemple concret : un stage avec directory table
CREATE OR REPLACE STAGE docs_stage
DIRECTORY = (ENABLE = TRUE);
On ajoute des fichiers dedans avec un put ou via l'interface puis on va scanner le fichier du stage
ALTER STAGE DOCS_STAGE REFRESH;
SELECT *
FROM DIRECTORY(@DOCS_STAGE);

Générer une URL sécurisée vers un fichier
Tu as trois fonctions qui reviennent souvent :
BUILD_SCOPED_FILE_URL: URL scopée (valable pour l’appelant, sur une durée liée au cache des résultats ; doc indique ~24h).GET_PRESIGNED_URL: URL pré-signée avec une expiration en secondes que tu choisis (pratique pour donner un accès très court).BUILD_STAGE_FILE_URL: génère une URL de fichier (usage via API fichier).
Exemple :
CREATE OR REPLACE SECURE VIEW V_DOCS_URLS AS
SELECT
relative_path,
GET_PRESIGNED_URL(@DOCS_STAGE, relative_path, 60) AS url_demo_60s
FROM DIRECTORY(@DOCS_STAGE);
Select relative_path, url_demo_60s from V_DOCS_URLS;

Aller plus loin : Formation Snowflake
J’ai regroupé tous mes articles Snowflake dans un parcours complet.
👉 Accéder à la Formation Snowflake
Vous voulez que je vous accompagne sur votre projet data (Snowflake, ingestion, modélisation, performance, coûts, gouvernance) ?
👉 Réserver un appel de 30 minutes