
Dans la plupart des projets BI, tu vas toujours avoir besoin à un moment donner d'analyser des données par groupe (par client, par produit, par jour...), tout en gardant le même niveau de granularité. Souvent, on fait un GROUP BY puis on rejoint au détail, ou on passe par des sous-requêtes/CTE. Ça marche, mais ça peut vite devenir lourd à maintenir.
Les window fonctions sont là pour simplifier ça. Elles ne remplacent pas GROUP BY, elles le complètent. Tu gardes tes lignes, et tu ajoutes une colonne calculée autour de la ligne courante comme numéroter (ROW_NUMBER()), classer (RANK(), DENSE_RANK()), faire un cumul ou une moyenne (SUM() OVER, AVG() OVER), trouver un min/max (MIN(), MAX()), comparer avec la ligne d'avant ou d'après (LAG(), LEAD()), ou afficher la première/dernière valeur (FIRST_VALUE(), LAST_VALUE()).
La syntaxe est toujours la même, elle commence avec une fonction suivie d'un OVER(...). Dans OVER, tu peux découper tes données avec PARTITION BY , définir un ordre avec ORDER BY , et parfois préciser une fenêtre de calcul avec ROWS BETWEEN ... AND ... quand tu veux un cumul ou une moyenne ligne par ligne.
<fonction>() OVER (
PARTITION BY ...
ORDER BY ...
ROWS BETWEEN ... AND ...
)
Exemples
Comme dans les articles précédents, il n'y a pas mieux que des exemples concrets pour comprendre le concept et voir comment ça fonctionne.
USE DATABASE Demo_db;
USE SCHEMA demo;
--Créer une table de démo
CREATE OR REPLACE TABLE demo_orders (
order_id INTEGER,
customer_id INTEGER,
order_date DATE,
amount NUMBER(10,2),
channel VARCHAR
);
Insert (20 lignes) :
INSERT INTO demo_orders (order_id, customer_id, order_date, amount, channel) VALUES
(1001, 101, DATE '2025-01-03', 120.00, 'WEB'),
(1002, 101, DATE '2025-01-07', 80.00, 'STORE'),
(1003, 101, DATE '2025-01-10', 200.00, 'WEB'),
(1004, 101, DATE '2025-01-10', 50.00, 'WEB'),
(1005, 101, DATE '2025-02-02', 90.00, 'STORE'),
(1006, 101, DATE '2025-02-15', 300.00, 'WEB'),
(2001, 102, DATE '2025-01-05', 60.00, 'WEB'),
(2002, 102, DATE '2025-01-20', 400.00, 'STORE'),
(2003, 102, DATE '2025-02-01', 150.00, 'WEB'),
(2004, 102, DATE '2025-02-01', 75.00, 'STORE'),
(2005, 102, DATE '2025-03-12', 220.00, 'WEB'),
(3001, 103, DATE '2025-01-02', 500.00, 'STORE'),
(3002, 103, DATE '2025-01-18', 40.00, 'WEB'),
(3003, 103, DATE '2025-02-10', 120.00, 'WEB'),
(3004, 103, DATE '2025-02-28', 120.00, 'STORE'),
(3005, 103, DATE '2025-03-05', 90.00, 'WEB'),
(4001, 104, DATE '2025-01-11', 30.00, 'WEB'),
(4002, 104, DATE '2025-02-11', 35.00, 'WEB'),
(4003, 104, DATE '2025-03-01', 25.00, 'STORE'),
(4004, 104, DATE '2025-03-15', 60.00, 'STORE');
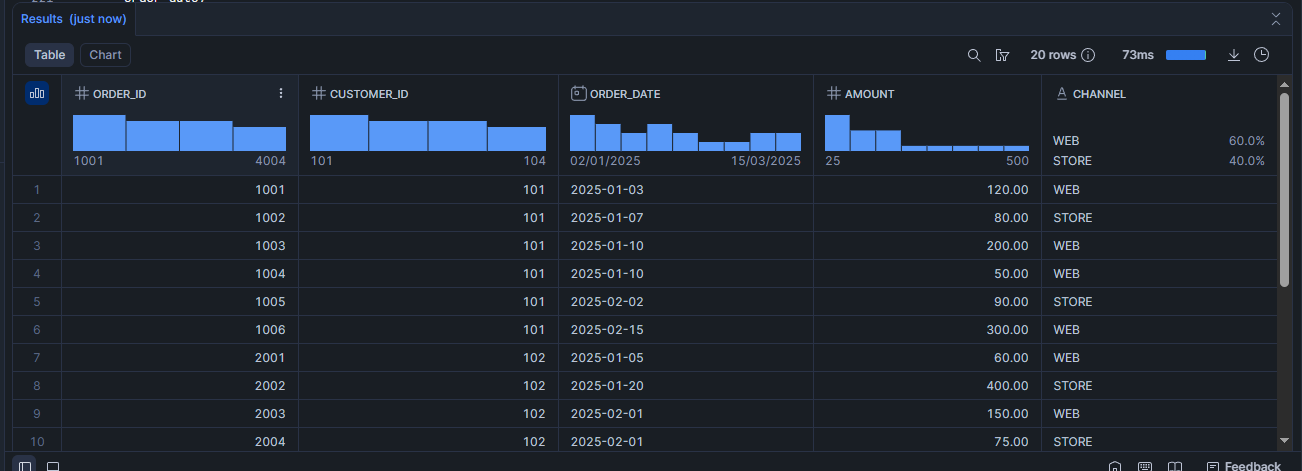
Voir le contenu de la table :
SELECT *
FROM demo_orders;
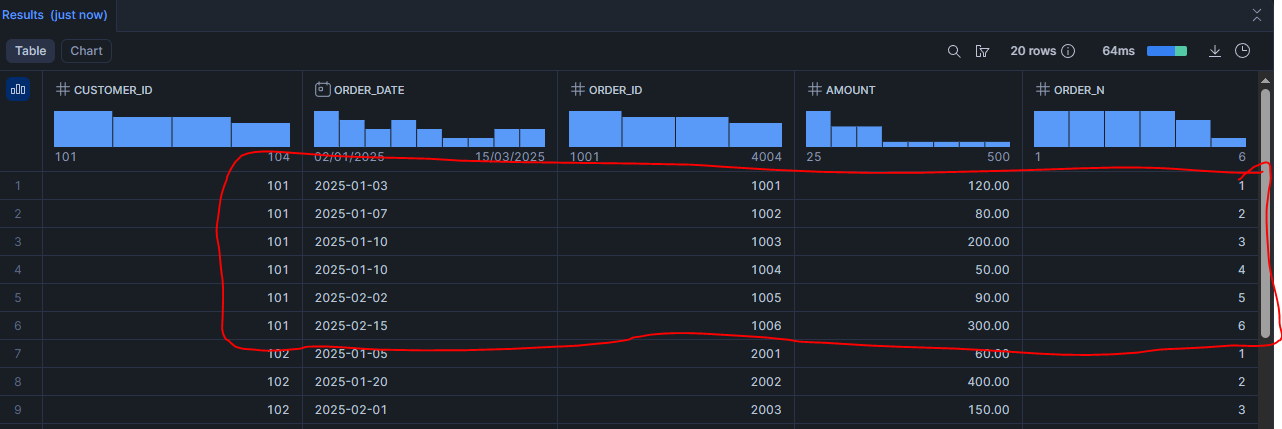
Scénario 1 : Numéroter les commandes d’un client (ROW_NUMBER)
SELECT
customer_id,
order_date,
order_id,
amount,
ROW_NUMBER() OVER (
PARTITION BY customer_id
ORDER BY order_date, order_id
) AS order_n
FROM demo_orders
ORDER BY customer_id, order_date, order_id;
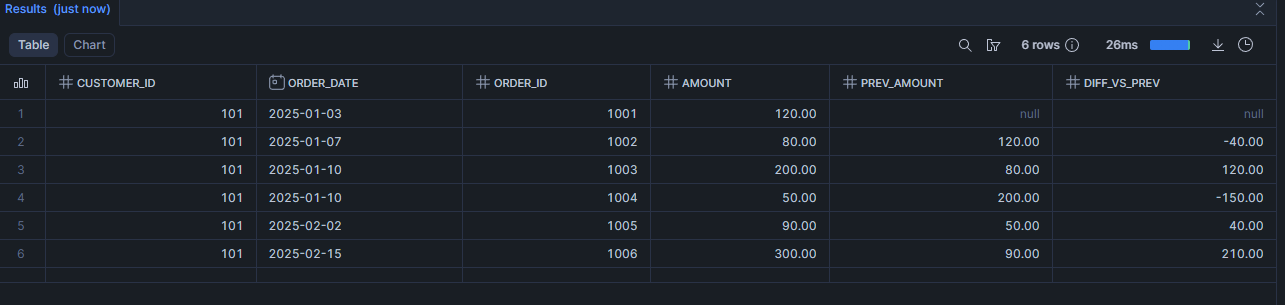
Scénario 2 : Mesurer l’évolution entre deux commandes (calculer la variation (LAG))
Concrètement dans ce use case, la fonction Lag va permettre de récupérer la valeur de la ligne précédente (du même client, dans l’ordre des dates), sans faire de self-join.
SELECT
customer_id,
order_date,
order_id,
amount,
LAG(amount) OVER (
PARTITION BY customer_id
ORDER BY order_date, order_id
) AS prev_amount,
amount - LAG(amount) OVER (
PARTITION BY customer_id
ORDER BY order_date, order_id
) AS diff_vs_prev
FROM demo_orders
WHERE customer_id = 101
ORDER BY order_date, order_id;
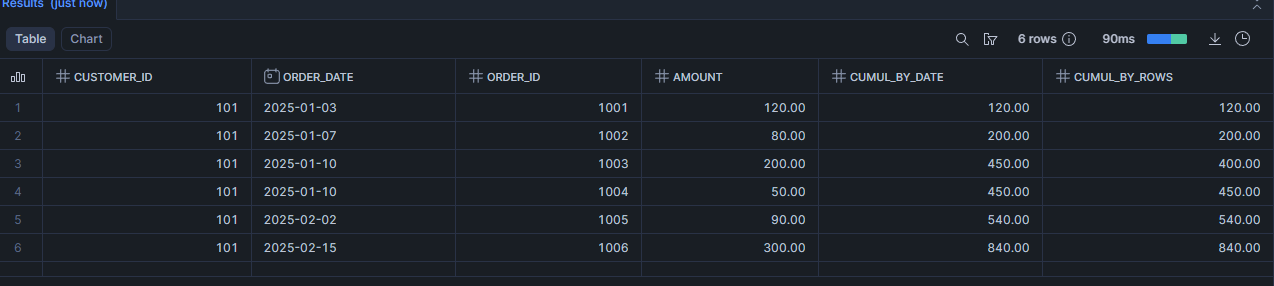
Scénario 3 : Suivre le cumul des dépenses client après chaque commande (calculer un cumul)
Objectif : afficher, pour chaque commande, le total dépensé par le client jusqu’à cette commande.
SELECT
customer_id,
order_date,
order_id,
amount,
-- cumul "par date" (si plusieurs lignes le même jour, ça peut regrouper)
SUM(amount) OVER (
PARTITION BY customer_id
ORDER BY order_date
) AS cumul_by_date,
-- cumul "ligne par ligne"
SUM(amount) OVER (
PARTITION BY customer_id
ORDER BY order_date, order_id
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
) AS cumul_by_rows
FROM demo_orders
WHERE customer_id = 101
ORDER BY order_date, order_id;
Scénario 4 : Top 3 commandes les plus chères par client
SELECT
customer_id,
order_id,
order_date,
amount
FROM demo_orders
QUALIFY ROW_NUMBER() OVER (
PARTITION BY customer_id
ORDER BY amount DESC, order_date DESC, order_id DESC
) <= 3
ORDER BY customer_id, amount DESC, order_id DESC;
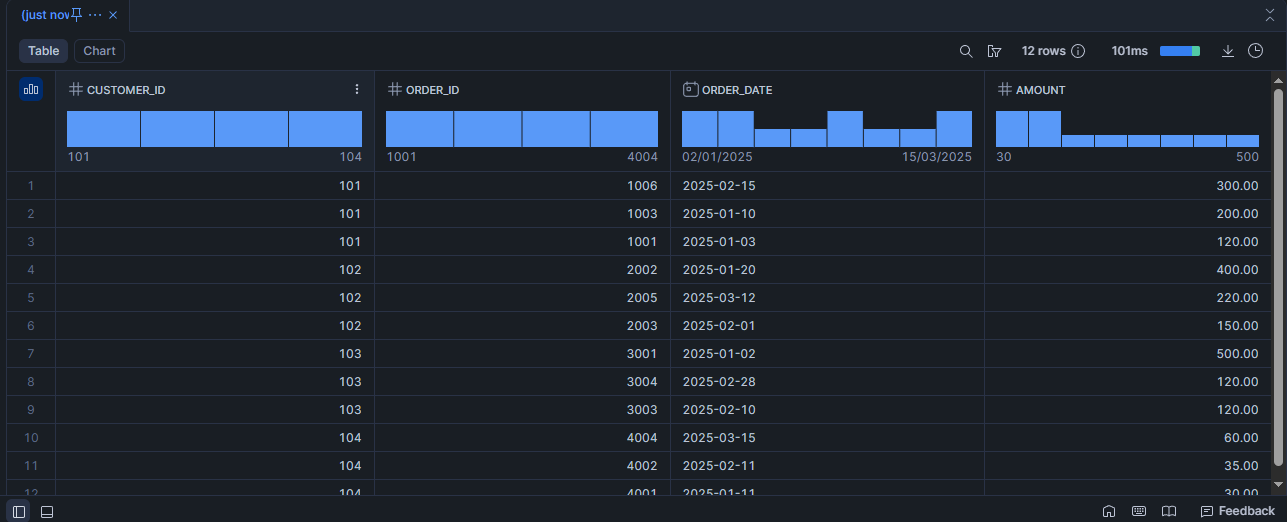
Scénario 5 : Part et poids de chaque commande dans le total du client
SELECT
customer_id,
order_date,
order_id,
amount,
SUM(amount) OVER (PARTITION BY customer_id) AS total_customer,
ROUND(100 * amount / SUM(amount) OVER (PARTITION BY customer_id), 2) AS pct_of_customer
FROM demo_orders
ORDER BY order_date, order_id;
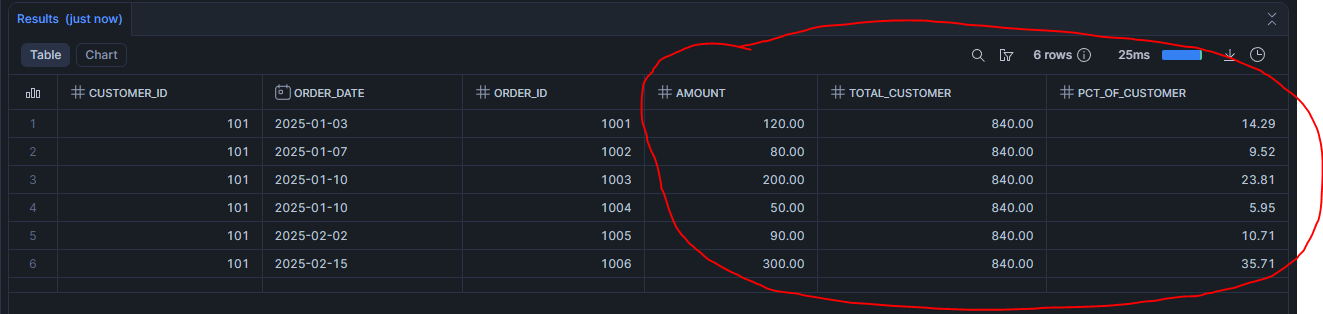
Scénario 6 : Moyenne des 3 dernières commandes
SELECT
customer_id,
order_date,
order_id,
amount,
ROUND(
AVG(amount) OVER (
PARTITION BY customer_id
ORDER BY order_date, order_id
ROWS BETWEEN 2 PRECEDING AND CURRENT ROW
), 2
) AS avg_last_3_orders
FROM demo_orders
ORDER BY order_date, order_id;
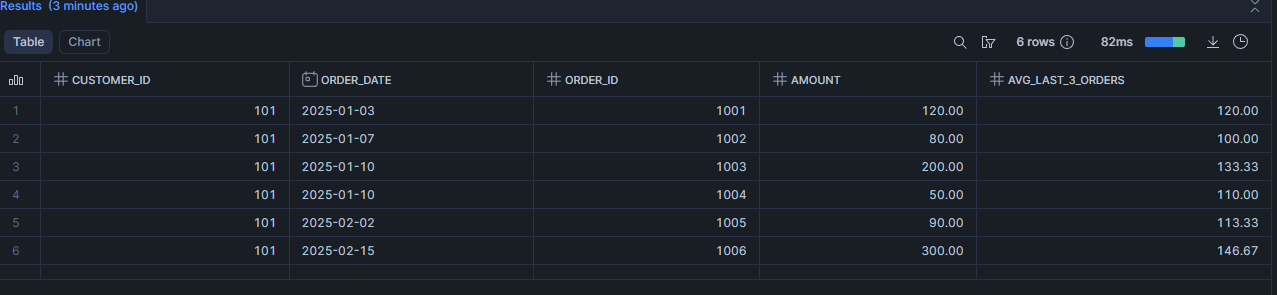
Scénario 7 : Top 3 commandes par canal
SELECT
channel,
order_id,
customer_id,
order_date,
amount
FROM demo_orders
QUALIFY ROW_NUMBER() OVER (
PARTITION BY channel
ORDER BY amount DESC, order_date DESC, order_id DESC
) <= 3
ORDER BY channel;
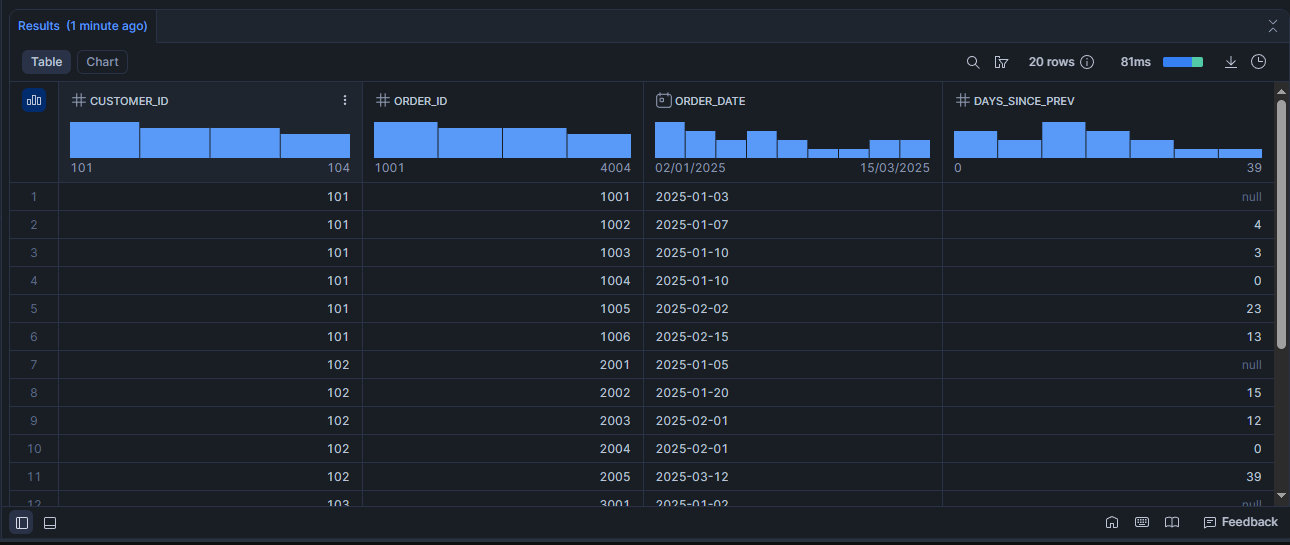
Scénario 8 : Premier achat et dernier achat du client sur chaque ligne (MIN & MAX)
SELECT
customer_id,
order_id,
order_date,
DATEDIFF(
'day',
LAG(order_date) OVER (PARTITION BY customer_id ORDER BY order_date, order_id),
order_date
) AS days_since_prev
FROM demo_orders
//QUALIFY days_since_prev IS NOT NULL
ORDER BY customer_id, order_date, order_id;
Aller plus loin : Formation Snowflake
J'ai regroupé tous mes articles Snowflake dans un parcours complet.
👉 Cours Snowflake (parcours complet)
Vous voulez que je vous accompagne sur votre projet data (Snowflake, ingestion, modélisation, performance, coûts, gouvernance) ?
👉 Réserver un appel de 30 minutes