
Dans l'article sur le Time Travel & Fail-safe, on a vu qu'on pouvait remonter dans le temps, restaurer une table supprimée avec UNDROP, et même créer un clone à un instant T. Mais on avait survolé le sujet du clone, sans vraiment creuser.
Ici, on va zoomer sur une fonctionnalité que je trouve personnellement révolutionnaire et qui, une fois qu'on l'a comprise, change complètement la façon dont on gère les environnements de test, les mises en prod et le debug et c'est le Zero-Copy Clone.
Un Rappel : les micro-partitions sont immuables
Pour bien comprendre le zero-copy clone, il faut revenir sur un point qu'on a déjà vu dans l'article sur l'architecture Snowflake et c'est que Snowflake ne modifie jamais une donnée en place.
Quand tu fais un INSERT, UPDATE ou DELETE, Snowflake ne va pas réécrire les micro-partitions existantes. Il va créer de nouvelles versions et marquer les anciennes comme obsolètes et donc
Une table, à un instant T, c'est juste un ensemble de pointeurs vers les micro-partitions valides à ce moment-là.
C'est exactement ce mécanisme qui rend le zero-copy clone possible. Si les données ne bougent pas physiquement, alors on peut les partager entre plusieurs objets sans rien dupliquer.
C'est quoi concrètement un zero-copy clone
L'idée est simple car quand tu clones une table (ou un schéma, ou une base de données), Snowflake ne recopie pas les données. Il crée un nouvel objet qui pointe vers les mêmes micro-partitions que l'original.
CREATE TABLE orders_test CLONE orders;
À ce stade, orders_test et orders partagent exactement les mêmes micro-partitions. Pas de copie physique, pas de temps d'attente, pas de stockage supplémentaire. Le clone est quasi instantané, même sur une table de plusieurs téraoctets.
C'est pour ça qu'on parle de zero-copy car techniquement c'est zéro copie de données.
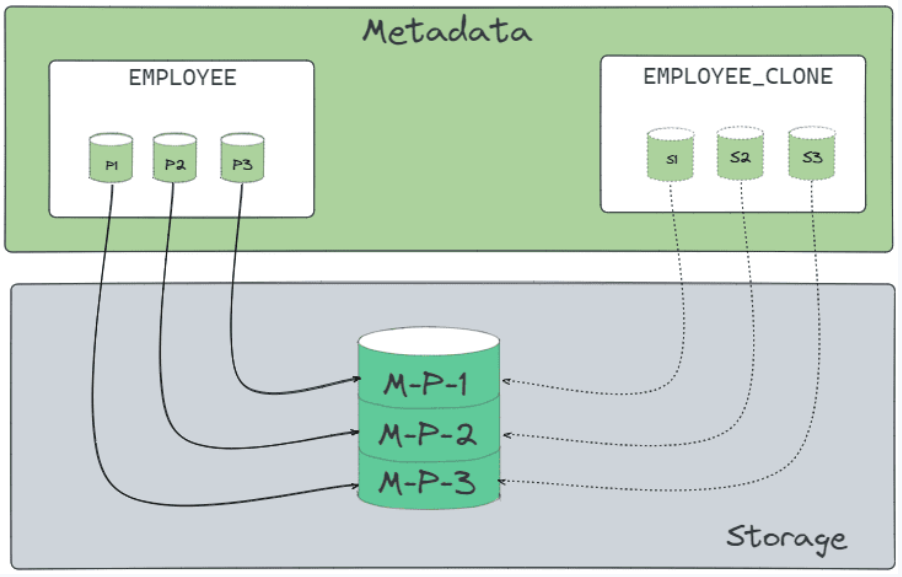
Comment ça marche côté stockage
Tant que tu ne touches à rien sur le clone, il n'y a aucun coût de stockage en plus. Les deux objets (l'original et le clone) pointent vers les mêmes blocs physiques.
Le stockage supplémentaire apparaît uniquement quand tu commences à modifier le clone. Par exemple, si tu fais un UPDATE sur EMPLOYEE_CLONE, Snowflake va créer de nouvelles micro-partitions pour les lignes modifiées. L'original, va continuer de pointer vers les anciennes versions.
Concrètement, imagine une table EMPLOYEE avec 100 micro-partitions :
-- Étape 1 : clone
CREATE TABLE EMPLOYEE_CLONE CLONE EMPLOYEE;
-- Stockage supplémentaire = 0. Les deux tables partagent les 100 micro-partitions.
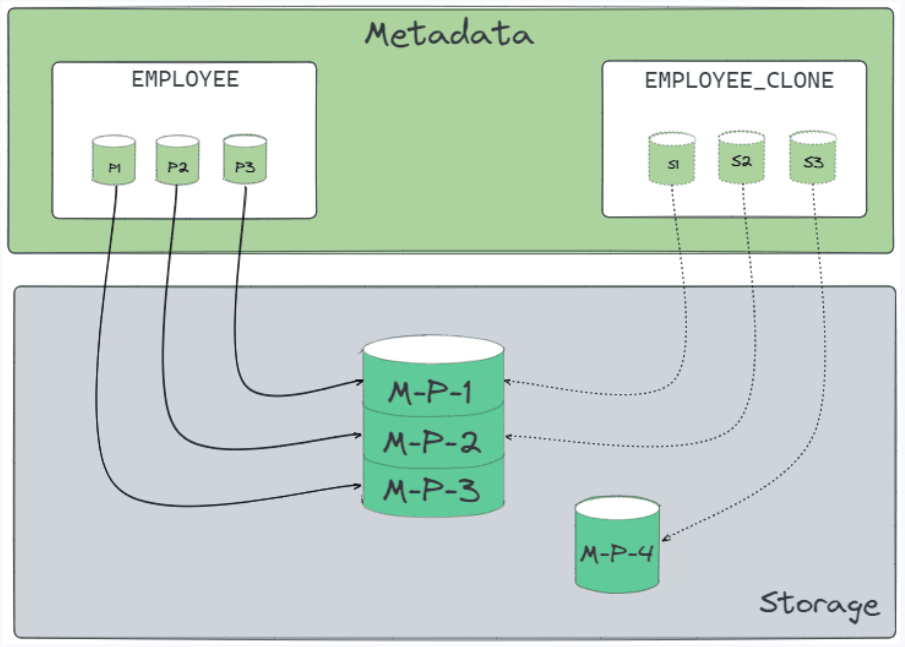
-- Étape 2 : modification sur le clone
UPDATE EMPLOYEE_CLONE SET status = 'new' WHERE employee_id = 24;
-- Snowflake crée 1 nouvelle micro-partition pour le clone.
-- Stockage supplémentaire ===> uniquement cette nouvelle micro-partition.
-- Les 99 autres sont toujours partagées.
Tu ne paies du stockage en plus que pour ce qui change entre l'original et le clone.
C'est exactement le même mécanisme que le Time Travel car Snowflake s'appuie sur l'immuabilité des micro-partitions pour éviter de tout recopier.
Ce qu'on peut cloner
Le zero-copy clone ne se limite pas aux tables. Tu peux cloner :
| Objet | Commande | Ce qui est cloné |
|---|---|---|
| Table | CREATE TABLE t2 CLONE t1; |
Données + structure |
| Schéma | CREATE SCHEMA s2 CLONE s1; |
Toutes les tables, vues, stages, séquences, etc... du schéma |
| Base de données | CREATE DATABASE db2 CLONE db1; |
Tous les schémas et leur contenu |
Quand tu clones un schéma ou une base de données, Snowflake clone récursivement tous les objets enfants. Et donc le même principe s'applique car pas de copie physique des données, uniquement des pointeurs.
Nb : Les objets comme les stages externes ne sont pas clonés de la même façon puisque Snowflake ne contrôle pas le stockage externe. Le clone va créer un nouvel objet qui pointe vers le même bucket, mais les fichiers eux-mêmes ne sont pas dupliqués côté Snowflake.
Clone + Time Travel : le puissant combo
On a vu dans l'article sur le Time Travel qu'on pouvait interroger une table dans le passé avec AT ou BEFORE. Le clone peut utiliser exactement le même mécanisme.
CREATE TABLE orders_backup CLONE orders
AT (TIMESTAMP => '2025-06-15 08:00:00');
Ici, orders_backup est un clone de orders tel qu'il était le 15 juin à 8h du matin. Aucune copie physique, et tu obtiens un snapshot figé de ta table à cet instant précis.
C'est vraiment trés pratique pour :
- Créer un point de sauvegarde avant une mise en prod car tu clones ta table juste avant de lancer un pipeline, et si ça casse, tu as ta version propre.
- Auditer ou comparer puisque tu veux voir ce qui a changé entre hier et aujourd'hui. Tu clones la version d'hier et tu fais un
MINUSou unEXCEPTentre les deux. - Rejouer un bug quand un utilisateur te signale un problème sur les données de 3 jours ? Tu clones la table à cette date et tu analyses tranquillement.
-- Comparer les commandes d'aujourd'hui vs hier
CREATE TABLE orders_yesterday CLONE orders
AT (TIMESTAMP => DATEADD(day, -1, CURRENT_TIMESTAMP));
SELECT * FROM orders
EXCEPT
SELECT * FROM orders_yesterday;
Les cas d'usage concrets
Environnement de test ou de dev
C'est probablement l'usage le plus courant. Au lieu de copier manuellement des tables de prod vers un schéma de dev (avec un CREATE TABLE AS SELECT qui duplique toutes les données), tu clones.
CREATE SCHEMA dev_sandbox CLONE production;
En une ligne, tu as un environnement de dev complet avec toutes les tables, vues et données de prod. Tu peux casser, tester, expérimenter. Et quand tu as fini, tu droppes le schéma.
Le coût ? Quasiment zéro tant que tu ne modifies pas massivement les données du clone.
Sauvegarde avant un déploiement
Avant de lancer un pipeline de transformation lourd ou une migration de schéma, tu peux créer un snapshot.
-- Avant la mise en prod
CREATE TABLE orders_pre_deploy CLONE orders;
-- Lancement du pipeline.....
....
-- Si tout se passe bien, on drop le backup
DROP TABLE orders_pre_deploy;
-- Si ça casse, on restaure
ALTER TABLE orders RENAME TO orders_broken;
ALTER TABLE orders_pre_deploy RENAME TO orders;
C'est rapide, ça ne coûte rien, et ça t'évite des sueurs froides.
Partage de données entre équipes
Tu as une équipe data science qui veut travailler sur les données de prod sans risquer de les modifier ? Tu clones la base ou le schéma dans un espace dédié.
CREATE DATABASE ds_workspace CLONE production_db;
L'équipe data science a ses données, peut faire ses expérimentations, et la prod reste intacte.
Les pièges à connaître
Le zero-copy clone est puissant, mais il y a quelques points à garder en tête :
1 - Les privilèges ne sont pas clonés car quand tu clones une table ou un schéma, les GRANT ne suivent pas. Le clone hérite des droits du rôle qui l'a créé, mais les droits spécifiques de l'objet source ne sont pas copiés. Il faut les reconfigurer.
2 - Attention aux clones oubliés car quand un clone qui vit longtemps et qu'on modifie beaucoup finit par accumuler ses propres micro-partitions. Et si tu oublies de le dropper, tu paies du stockage pour rien. C'est le genre de chose qui passe inaperçue sur la facture.
3 - Le clone est un objet indépendant. Une fois créé, le clone vit sa propre vie. Si tu modifies la table source après le clone, le clone ne voit pas ces modifications. Et inversement.
4 - Les données de Time Travel du clone repartent de zéro. Le clone ne récupère pas l'historique Time Travel de la table source. L'historique commence au moment où le clone est créé.
| Point | Ce qu'il faut retenir |
|---|---|
| Principe | Le clone pointe vers les mêmes micro-partitions, pas de copie physique |
| Coût initial | Zéro stockage supplémentaire |
| Coût dans le temps | Tu ne paies que les micro-partitions qui changent (les modifications sur le clone) |
| Objets clonables | Tables, schémas, bases de données |
| Combo Time Travel | Tu peux cloner un objet à l’instant T, tant que tu es dans la période de rétention |
| Privilèges | Non clonés, à reconfigurer manuellement |
| Indépendance | Le clone vit sa propre vie après sa création |
Aller plus loin : Formation Snowflake
J'ai regroupé tous mes articles Snowflake dans un parcours complet.
👉 Accéder à la Formation Snowflake
Vous voulez que je vous accompagne sur votre projet data (Snowflake, ingestion, modélisation, performance, coûts, gouvernance) ?