
Tu lances une requête, elle met 50 secondes.
Tu la relances, et la.... c'est quasi instantané.
Deux options :
- La requête s'est auto-optimisée par magie 😅
- Tu viens juste de tomber sur le cache.
Il y a plusieurs mécanismes de cache qui se ressemblent côté utilisateur, mais qui n'ont pas du tout la même logique.
Le cache de résultats (persisted query results)
L'idée est simple car si tu refais la même requête et que rien n'a changé, on te renvoie le même résultat directement, sans refaire le calcul. Les résultats sont conservés un certain temps, puis purgés (par défaut la durée du cache est de 24 heures).
Le point à retenir, c'est que "exactement la même requête" veut dire... exactement la même. Une petite différence de syntaxe peut suffire à casser le cache, y compris la casse (minuscules/majuscules) ou un simple alias de table.
Exemple
-- 1) première exécution
SELECT SUM(amount) FROM sales;
-- 2) identique => peut réutiliser le résultat
SELECT SUM(amount) FROM sales;
-- 3) alias => cache cassé
SELECT SUM(amount) FROM sales s;
-- 4) minuscules => cache cassé
select sum(amount) from sales;
Si tu fais des tests de perf manuellement, il faut faire attention au cache pour éviter de comparer l'incomparable.
Désactiver le cache : USE_CACHED_RESULT
Par défaut, la réutilisation du cache est activée, mais tu peux la désactiver au niveau compte, user ou session via USE_CACHED_RESULT.
ALTER SESSION SET USE_CACHED_RESULT = FALSE;
-- User
ALTER USER <username> SET USE_CACHED_RESULT = FALSE;
(Comme ça, tu mesures vraiment l'exécution, pas la relecture d'un résultat déjà calculé.)
Les fonctions qui bloquent le cache
Si ta requête contient des fonctions qui changent à chaque exécution (typiquement un élément aléatoire ou identifiant), le cache de résultats ne sert à rien. Exemples : UUID_STRING, RANDOM, RANDSTR, CURRENT_TIMESTAMP etc....
-- Même si la table n'a pas bougé, le résultat change
SELECT CURRENT_TIMESTAMP(), COUNT(*) FROM sales;
La rétention du cache
À chaque réutilisation, la fenêtre de 24h est réinitialisée, jusqu'à un maximum de 31 jours depuis la toute première exécution, puis le résultat est purgé.
Le warehouse cache
Le cache de warehouse est plus physique, car lorsque un warehouse est en cours d'exécution il garde en local une partie des données de table déjà lues, et les requêtes suivantes exécutées sur ce même warehouse peuvent le réutiliser.
Sauf que (et c'est la clé) : si tu autosuspend trop agressivement les warehouses, tu jettes le cache à la poubelle.
Pour le rechargement des données BI, la reco générale est plutôt de garder un autosuspend au moins 10 minutes pour maintenir le cache côté utilisateurs.
Et comme vu dans l'article de FinOps, il faut trouver un compromis car un warehouse qui tourne consomme des crédits même quand il ne fait rien, donc il faut aligner l'autosuspend sur le rythme réel des requêtes et rechargement des données.
Mesurer l'utilisation du cache
Pour mesurer le cache pour une requête, le premier réflexe devrait être le query profile, et je t'invite à voir mon article sur le sujet. Mais pour mesurer globalement le pourcentage de données scannées depuis le cache, agrégé par warehouse, voici une requête de diagnostic :
SELECT warehouse_name
,COUNT(*) AS query_count
,SUM(bytes_scanned) AS bytes_scanned
,SUM(bytes_scanned*percentage_scanned_from_cache) AS bytes_scanned_from_cache
,SUM(bytes_scanned*percentage_scanned_from_cache) / SUM(bytes_scanned) AS percent_scanned_from_cache
FROM snowflake.account_usage.query_history
WHERE start_time >= dateadd(month,-1,current_timestamp())
AND bytes_scanned > 0
GROUP BY 1
ORDER BY 5;

- Si tu as des requêtes fréquentes similaires et un
percent_scanned_from_cachefaible, tu as peut-être un warehouse toujours froid (autosuspend trop court, warehouse pas dédié) - Si c'est élevé, ton warehouse cache fait déjà le boulot.
Le cache des métadonnées (Metadata-based Result)
Dans Snowflake, certaines requêtes peuvent être calculées uniquement à partir des métadonnées, sans accéder aux données et sans être traitées par un virtual warehouse.
Exemple
SELECT COUNT(*) FROM RAW_EVENTS;
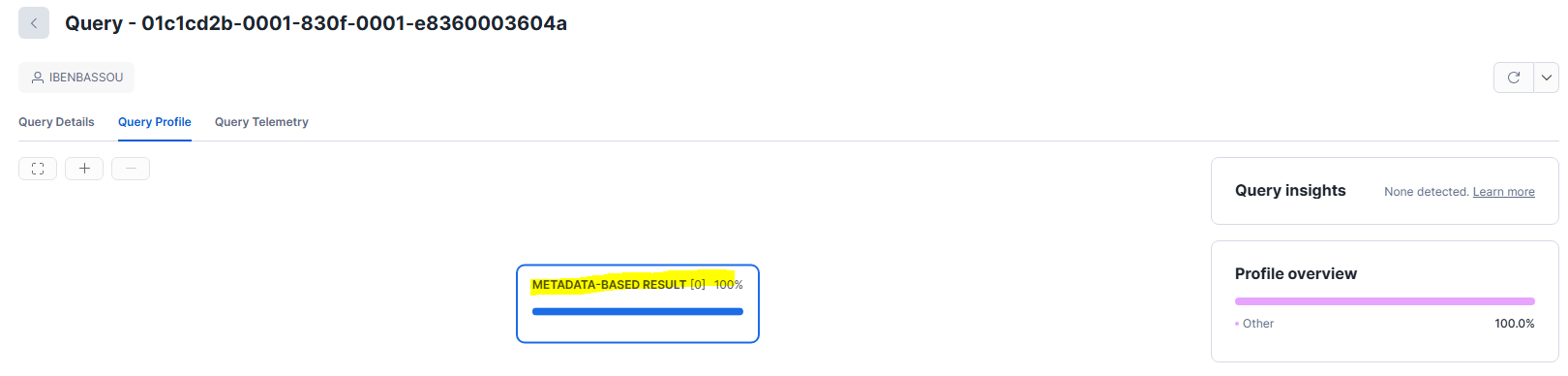
Ce qui est intéressant, c'est que tu peux le voir dans le Query Profile, ce type de requête apparaît comme "Metadata-based Result"
Les micro partitions
Même quand la requête s'exécute vraiment, Snowflake ne scanne pas forcément toute la table. Il s'appuie sur les métadonnées des micro-partitions pour écarter tout ce qui est hors sujet et ne lire que ce qui peut matcher ton filtre. Si la notion de micro-partitions n'est pas encore claire, je te renvoie à mon article sur l'architecture Snowflake
Exemple
SELECT *
FROM events
WHERE event_date = '2026-01-17';
Si la table est plus ou moins organisée autour de event_date, et que ton filtre ne vise qu'une petite partie de la période, l'idée est de ne scanner que les micro-partitions qui peuvent contenir cette date et pas la table entière donc au final, ce n'est pas un cache mais c'est juste que tu n'as pas lu ce qui ne servait à rien.
Aller plus loin : Formation Snowflake
J'ai regroupé tous mes articles Snowflake dans un parcours complet.
Vous voulez que je vous accompagne sur votre projet data (Snowflake, ingestion, modélisation, performance, coûts, gouvernance) ?
👉 Réserver un appel de 30 minutes