
Dans l'article sur le Query Profile, on a vu comment comprendre où Snowflake passe son temps. Et dans l'article sur le Clustering, on a vu comment réorganiser les micro-partitions pour que Snowflake lit le moins possible.
Mais il y a un cas qu'on n'a pas encore couvert.
Rappelle-toi l'exemple 3 du Query Profile avec la jointure entre ORDERS et LINEITEM. Même avec un bon filtre sur O_ORDERDATE, Snowflake scannait quand même 1078 partitions sur 1313 côté LINEITEM. Le clustering sur ORDERS ne change rien ici, parce que le problème vient de LINEITEM, une table beaucoup plus grosse qui n'a pas la colonne de filtre.
Et dans l'article sur le Clustering, on a vu que le clustering ne sert à rien quand le problème est un gros volume à lire et qui ne peut pas être réduit par du pruning.
C'est exactement là que le Query Acceleration Service (QAS) entre en jeu. Au lieu de réduire le volume lu (comme le fait le clustering), le QAS accélère la lecture elle-même en ajoutant temporairement de la puissance de calcul.
C'est quoi concrètement le QAS ?
Le QAS est un service serverless qui détecte les requêtes lourdes et leur ajoute des ressources de calcul supplémentaires, en parallèle de ta warehouse.
Pour reprendre l'analogie : dans les articles précédents, on a travaillé sur "lire moins de données" (bons filtres, clustering). Le QAS, lui, travaille sur "lire les données plus vite" en mobilisant plus de machines en parallèle.
Concrètement, quand une requête éligible s'exécute sur une warehouse avec QAS activé, Snowflake fait appel à des ressources de calcul partagées pour prendre en charge une partie du scan. Ta warehouse continue de tourner normalement pour les autres requêtes. Et les ressources supplémentaires disparaissent dès que le travail est terminé.
Quels types de requêtes le QAS peut accélérer ?
Le QAS ne fonctionne pas sur toutes les requêtes. Il cible un profil bien précis, et si tu as lu les deux articles précédents, tu vas tout de suite reconnaître le pattern.
Tu te souviens, dans le Query Profile, de la distinction entre Processing % et Remote Disk I/O % ? Le QAS est fait pour les requêtes où le Remote Disk I/O est dominant, c'est-à-dire les requêtes qui passent l'essentiel de leur temps à lire des données :
- Des requêtes qui scannent beaucoup de micro-partitions
- Des requêtes avec des filtres sélectifs (un
WHEREqui ne garde qu'une partie des données) - Des requêtes avec des agrégations (
COUNT,SUM,AVG...) sur de grosses tables - Des
INSERTouCOPYqui traitent beaucoup de lignes
En gros, exactement le type de requêtes qu'on a analysées dans le Query Profile.
Requêtes non éligibles au QAS
Certaines requêtes ne seront jamais accélérées par le QAS :
- La table est trop petite (pas assez de micro-partitions à scanner, le gain serait nul)
- Le filtre n'est pas assez sélectif (le QAS ne peut pas paralléliser efficacement)
- Le
GROUP BYa une cardinalité trop élevée - La requête utilise des fonctions non déterministes comme
RANDOM()
Comment activer le QAS
Le QAS s'active au niveau de la warehouse, pas au niveau de la requête. C'est un paramètre de la warehouse.
sql
-- Activer le QAS sur une nouvelle warehouse
CREATE WAREHOUSE my_wh
WITH ENABLE_QUERY_ACCELERATION = true;
-- Activer le QAS sur une warehouse existante
ALTER WAREHOUSE my_wh
SET ENABLE_QUERY_ACCELERATION = true;Une fois activé, Snowflake décide automatiquement quelles requêtes accélérer. Tu n'as rien d'autre à faire. Si une requête est éligible, Snowflake utilise le QAS. Sinon, la requête s'exécute normalement et il n'y a aucun surcoût.
Le Scale Factor : comment contrôler les coûts du QAS
Le QAS consomme des crédits supplémentaires, facturés séparément de ta warehouse et à la seconde. Et si tu ne fais pas attention, ça peut monter vite. C'est là qu'intervient le Scale Factor.
Le Scale Factor est un multiplicateur qui limite la quantité de ressources que le QAS peut utiliser. Il se base sur le coût de ta warehouse.
Exemple : une warehouse Medium coûte 4 crédits/heure. Avec un Scale Factor de 5, le QAS peut consommer au maximum 20 crédits/heure en plus (4 × 5 = 20).
ALTER WAREHOUSE my_wh
SET ENABLE_QUERY_ACCELERATION = true
QUERY_ACCELERATION_MAX_SCALE_FACTOR = 5;Attention si le Scale Factor de 0 cela veut dire aucune limite et donc Snowflake peut utilise autant de ressources que nécessaire donc il est recommandé de commencer plutôt avec un Scale Factor de 2 ou 4, et observer les coûts et esnuite ajuster si besoin.
Exemple concret
On reprend l'exemple 3 de l'article sur le Query Profile de la jointure entre ORDERS et LINEITEM. C'est l'exemple parfait parce qu'on avait vu que LINEITEM scannait 1078 partitions sur 1313, et que le clustering sur ORDERS ne pouvait rien y faire.
Étape 1 : Créer deux warehouses pour comparer
sql
-- Warehouse SANS QAS
CREATE WAREHOUSE sans_qas_wh
WITH WAREHOUSE_SIZE = 'XSMALL'
ENABLE_QUERY_ACCELERATION = false
AUTO_SUSPEND = 60
AUTO_RESUME = true;
-- Warehouse AVEC QAS
CREATE WAREHOUSE avec_qas_wh
WITH WAREHOUSE_SIZE = 'XSMALL'
ENABLE_QUERY_ACCELERATION = true
QUERY_ACCELERATION_MAX_SCALE_FACTOR = 8
AUTO_SUSPEND = 60
AUTO_RESUME = true;Étape 2 : Lancer la même requête sur les deux warehouses
On reprend une variante de la requête de l'exemple 3 du Query Profile, qui scanne beaucoup de données sur LINEITEM :
-- Sur la warehouse SANS QAS
USE WAREHOUSE sans_qas_wh;
SELECT
L_RETURNFLAG,
L_LINESTATUS,
SUM(L_QUANTITY) AS sum_qty,
SUM(L_EXTENDEDPRICE) AS sum_base_price,
AVG(L_DISCOUNT) AS avg_disc
FROM SNOWFLAKE_SAMPLE_DATA.TPCH_SF1000.LINEITEM
WHERE L_SHIPDATE <= DATEADD('day', -90, '1998-12-01')
GROUP BY L_RETURNFLAG, L_LINESTATUS
ORDER BY L_RETURNFLAG, L_LINESTATUS;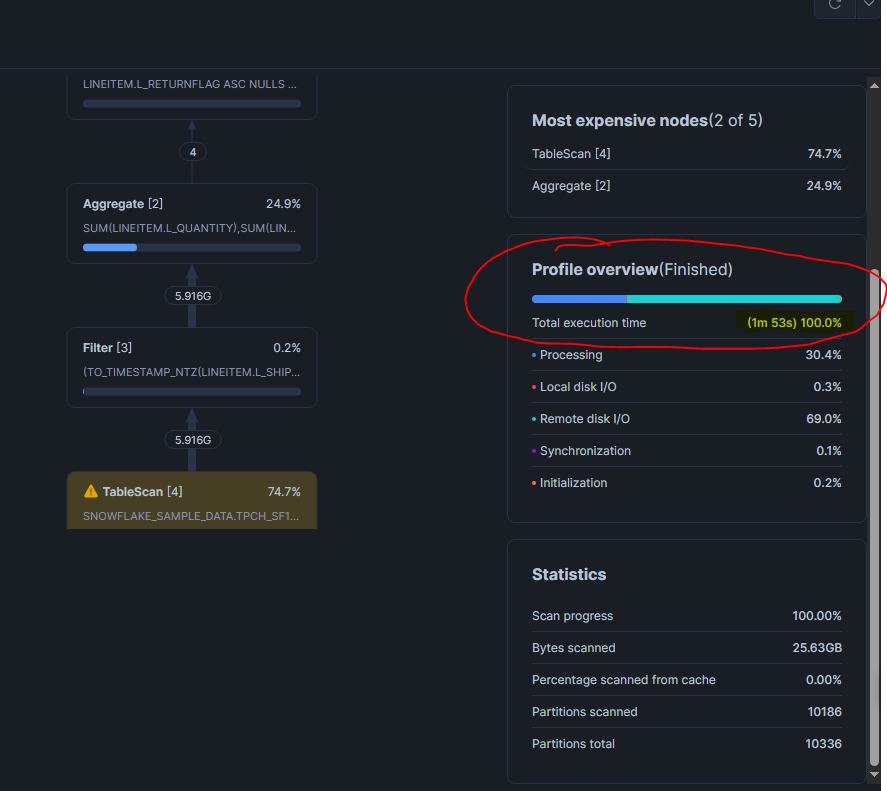
-- Vider le cache
ALTER SESSION SET USE_CACHED_RESULT=FALSE;
-- Même requête sur la warehouse AVEC QAS
USE WAREHOUSE avec_qas_wh;
SELECT
L_RETURNFLAG,
L_LINESTATUS,
SUM(L_QUANTITY) AS sum_qty,
SUM(L_EXTENDEDPRICE) AS sum_base_price,
AVG(L_DISCOUNT) AS avg_disc
FROM SNOWFLAKE_SAMPLE_DATA.TPCH_SF1000.LINEITEM
WHERE L_SHIPDATE <= DATEADD('day', -90, '1998-12-01')
GROUP BY L_RETURNFLAG, L_LINESTATUS
ORDER BY L_RETURNFLAG, L_LINESTATUS;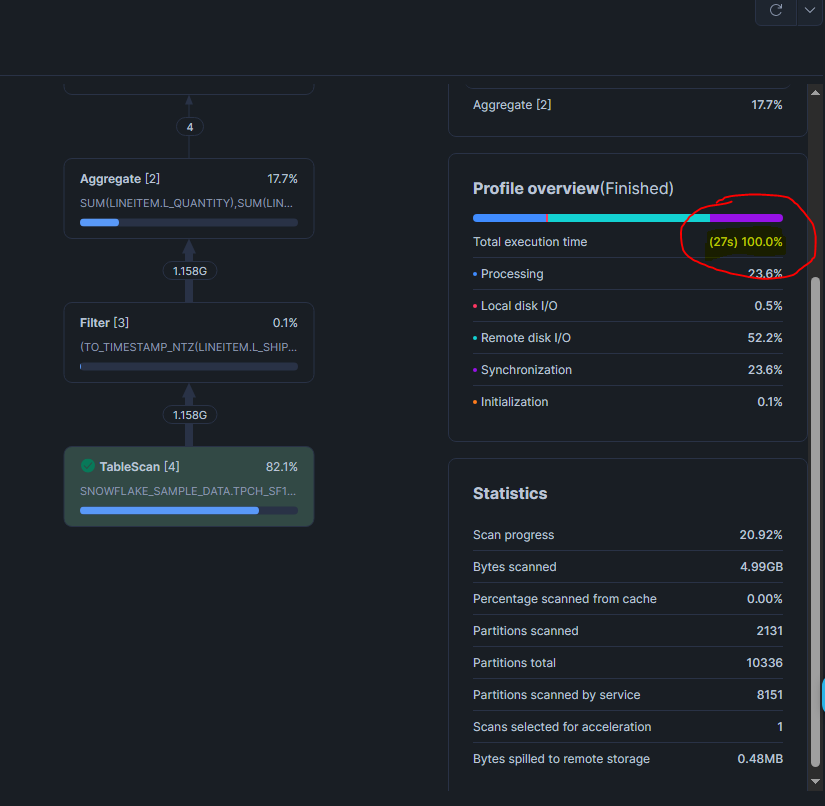
Comparer les résultat du Query Profile
On peut voir clairement que
- Le temps total d'exécution est plus court avec le QAS
- Le Remote Disk I/O % a baissé côté warehouse avec le QAS
SELECT
query_id,
warehouse_name,
total_elapsed_time / 1000 AS elapsed_seconds,
query_acceleration_bytes_scanned,
query_acceleration_partitions_scanned,
query_acceleration_upper_limit_scale_factor
FROM TABLE(INFORMATION_SCHEMA.QUERY_HISTORY())
WHERE query_text LIKE '%LINEITEM%L_SHIPDATE%'
AND warehouse_name IN ('SANS_QAS_WH', 'AVEC_QAS_WH')
ORDER BY start_time DESC
LIMIT 2;Si la requête a été accélérée, tu verras que query_acceleration_bytes_scanned et query_acceleration_partitions_scanned sont supérieurs à 0 pour la warehouse avec QAS.

Surveiller les coûts du QAS
Une fois le QAS activé, surveille ce qu'il te coûte. C'est le même réflexe que dans l'article sur le clustering quand on vérifiait les coûts de l'automatic clustering.
Voir les crédits QAS par warehouse (mois en cours)
SELECT
warehouse_name,
SUM(credits_used) AS total_credits_qas
FROM SNOWFLAKE.ACCOUNT_USAGE.QUERY_ACCELERATION_HISTORY
WHERE start_time >= DATE_TRUNC('month', CURRENT_DATE())
GROUP BY warehouse_name
ORDER BY total_credits_qas DESC;
Voir quelles requêtes ont utilisé le QAS
SELECT
query_id,
warehouse_name,
total_elapsed_time / 1000 AS elapsed_seconds,
query_acceleration_bytes_scanned,
query_acceleration_partitions_scanned
FROM SNOWFLAKE.ACCOUNT_USAGE.QUERY_HISTORY
WHERE warehouse_name = 'AVEC_QAS_WH'
AND query_acceleration_bytes_scanned > 0
ORDER BY start_time DESC;
Si query_acceleration_bytes_scanned est à 0, le QAS était activé mais n'a pas été utilisé pour cette requête. Et dans ce cas, aucun crédit supplémentaire n'a été consommé. Tu ne payes que quand le QAS travaille réellement.
Comment savoir si tes requêtes bénéficieraient du QAS
Avant d'activer le QAS, tu peux vérifier si tes requêtes actuelles sont éligibles. Pas besoin de deviner car Snowflake a tout ce qu'il faut avec SYSTEM$ESTIMATE_QUERY_ACCELERATION .
SELECT PARSE_JSON(
SYSTEM$ESTIMATE_QUERY_ACCELERATION('01c264ef-0001-928f-0001-e83600122946')
);
Le résultat te dit si la requête est eligible ou ineligible. Si elle est éligible, Snowflake te donne une estimation du temps d'exécution pour différents Scale Factors. Dans notre exemple, la requête d'origine a pris 112 secondes. Avec un Scale Factor de 1, elle passerait à 63 secondes donc cela va te permettre de juger si le QAS vaut le coup avant de l'activer ou non.
Où se situe le QAS dans notre formation
Avec les trois articles, on a maintenant trois leviers d'optimisation et l'ordre dans lequel tu les utilises est trés important :
1. Query Profile → Diagnostiquer. Comprendre où Snowflake passe son temps. Est-ce du Remote Disk I/O ? Du Processing ? Combien de partitions sont scannées ?
2. Clustering → Réduire. Si le Query Profile montre que trop de partitions sont scannées et que tu filtres souvent sur les mêmes colonnes, le clustering réorganise les données pour que Snowflake en lise moins.
3. QAS → Accélérer. Si après le clustering (ou si le clustering n'est pas applicable), il reste des requêtes qui scannent beaucoup de données, le QAS accélère le scan en parallélisant le travail.
Donc pour faire simple d'abord tu diagnostiques, ensuite tu réduis le volume, et enfin tu accélères ce qui reste.
Aller plus loin : Formation Snowflake
J'ai regroupé tous mes articles Snowflake dans un parcours complet.
👉 Formation Snowflake : tous les modules pas à pas
Vous voulez que je vous accompagne sur votre projet data (Snowflake, ingestion, modélisation, performance, coûts, gouvernance) ?