
Je vais être honnête car pendant longtemps, je ne connaissais pas grand chose sur Databricks. J'avais vu le nom passer sur LinkedIn, dans des offres d'emploi, dans des videos. Mais je n'avais jamais eu besoin ni le temps d'aller creuser plus loin.
Jusqu'au jour où un ingénieur d'affaire m'a contacté pour une mission très intéressante avec une visibilité de 2 ans mais il m'a expliqué que c'est pour une migration onprem vers une stack data cloud Databricks, et donc il m'a demandé :
"Tu connais déjà Snowflake, mais est-ce que tu serais à l’aise pour expliquer la différence avec Databricks si le client retenait ton profil en entretien ? Et ce type de mission, ça pourrait t'intéresser ?"
Et là, j'ai réalisé que je n'avais pas du tout une réponse claire. Je savais que "ce n'est pas la même chose, mais il y a énormément de points communs", je voyais bien que les deux revenaient partout dans les offres et que ce sont les leaders des data cloud platforms, mais j'étais incapable d'expliquer concrètement en quoi ils diffèrent... Du coup, j'ai fait ce que je fais toujours quand je veux comprendre un sujet, j'ai beaucoup lu la doc, j'ai comparé en détail.
Ça fait plusieurs mois que c'est arrivé, mais vaut mieux tard que jamais. Il est temps que je mette par écrit ce que j'ai appris dans mes recherches, mes tests et les différentes vidéos.
Le point de départ
Pour comprendre la différence entre Snowflake et Databricks, il faut d'abord comprendre d'où ils viennent. Parce que leur origine explique presque tout.
Snowflake : né du data warehouse
Snowflake est né en 2012 avec une mission claire et c'est construire un data warehouse cloud moderne.
Si tu as lu l'article sur l'architecture Snowflake, tu connais déjà le principe de snowflake avec une architecture hybride qui sépare le stockage, le compute et les services. Tu crées des tables, tu charges des données, tu écris du SQL, et Snowflake s'occupe du reste (scaling, optimisation, sécurité, etc....).
Le positionnement historique de Snowflake, c'est :
"Tu as principalement des données structurées, tu veux les analyser avec du SQL, on te fournit le meilleur moteur possible pour ça avec une scalabilité quasi infinie dans le cloud"
Databricks : né du big data et du machine learning
Databricks, c'est une autre histoire. La plateforme a été créée en 2013 par les fondateurs d'Apache Spark, un moteur de traitement distribué open source sorti de l'université de Berkeley.
Le positionnement de départ de Databricks, c'est :
"Tu as des volumes massifs de données (structurées, semi-structurées, non structurées), tu veux les transformer avec du code (Python, Scala, R, SQL), faire du machine learning, du streaming en temps réel. On te fournit la plateforme parfaite pour ça."
Databricks n'est pas parti du data warehouse. Il est parti plutôt du data lake avec un espace de stockage brut (S3, Azure Blob, GCS) où tu poses tous tes fichiers (Parquet, JSON, CSV, images, logs...) sans schéma imposé au départ.
Data Warehouse vs Data Lakehouse : le concept clé
Là, c'est le moment où la plupart des articles deviennent flous. Alors on va poser les choses clairement.
Le Data Warehouse (Snowflake)
Un data warehouse classique, c'est un système pensé avant tout pour la donnée structurée. Tu définis un schéma (colonnes, types), tu charges tes données dedans, et tu les interroges en SQL.
C'est le cœur de ce que Snowflake fait depuis le début. Comme on l'a vu dans l'article sur les types de tables, tu crées tes tables, tu charges tes fichiers via des stages et des file formats , tu transformes les données etc... etc...., et le moteur s'occupe du reste.
Mais attention, Snowflake ne se limite pas au structuré. Comme on l'a vu dans l'article sur les données semi-structurées et non structurées, Snowflake gère aussi le semi-structuré (JSON, Parquet, XML, Avro...) grâce au type VARIANT et à FLATTEN, et le non structuré (PDF, images, audio...) via les stages et les directory tables. Donc c'est un data warehouse, oui, mais un data warehouse ++ qui sait gérer bien plus que des tables relationnelles classiques.
Le Data Lake
Un data lake, c'est juste un espace de stockage cloud (S3, ADLS, GCS) où tu poses tes fichiers bruts. Pas de schéma imposé, pas de moteur intégré. C'est flexible, c'est pas cher, mais c'est le Far West car pas de transactions ACID, pas de contrôle qualité, pas de gouvernance....
Le Data Lakehouse (Databricks)
Et c'est là que Databricks a eu une idée intéressante en prenant le data lake et lui ajouter les garanties d'un data warehouse. C'est tout simplement le concept de Lakehouse.
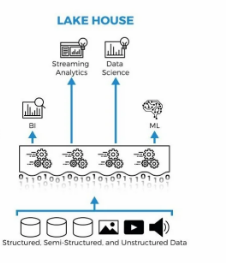
Concrètement, Databricks a créé Delta Lake, une couche open source qui s'installe par dessus le stockage cloud et qui apporte les transactions ACID, le versioning des données (Time Travel), le schema, et bien d'autres fonctionnalités que tu retrouves normalement dans un data warehouse.
L'objectif est de garder la flexibilité et le coût faible du data lake, mais avec la fiabilité d'un warehouse. Et faire tourner le tout avec Apache Spark comme moteur de calcul.

L'architecture
Maintenant qu'on a le contexte, regardons comment les deux plateformes fonctionnent concrètement.
Architecture Snowflake
Si tu as lu l'article sur l'architecture, tu connais les 3 couches :
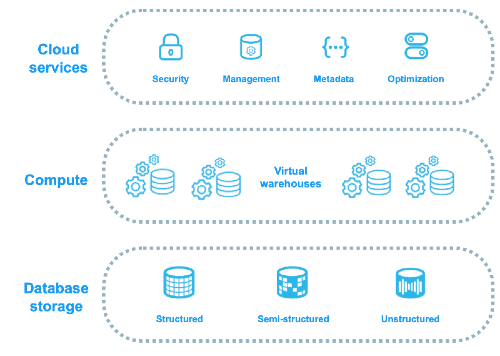
Storage => Snowflake stocke la donnée dans son propre format colonnaire compressé, découpé en micro-partitions. Tu ne gères pas le stockage, c'est Snowflake qui s'en occupe.
Compute => Les virtual warehouses (X-Small à 6X-Large). Tu les allumes, ils consomment des crédits. Tu les éteins, le compteur s'arrête.
Cloud Services => Sécurité, métadonnées, optimisation, gouvernance. Une couche partagée qui orchestre tout.
Le point important et c'est que tout est managé par Snowflake. Le stockage est propriétaire (tu ne vois pas les fichiers sur S3 directement), et c'est Snowflake qui décide comment organiser, compresser et partitionner tes données.
Architecture Databricks
Dans Databricks, l'architecture est différente :
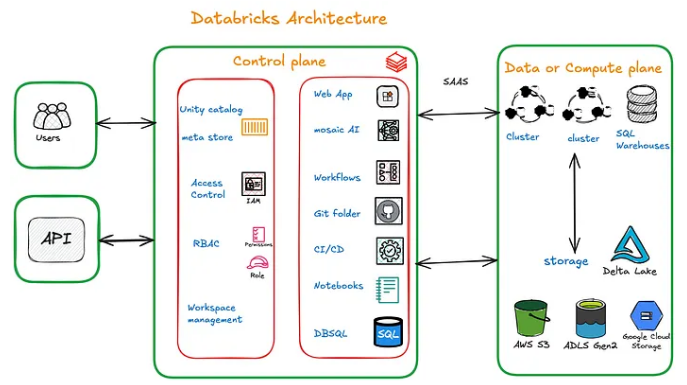
Control Plane → C'est la partie managée par Databricks avec l'interface web, les notebooks, l'orchestration des jobs, la configuration des clusters etc....
Data Plane → Les données restent dans ton stockage cloud (S3, Azure Data Lake Storage, GCS), au format Delta Lake (Parquet + logs de transactions). Les clusters Spark qui font le calcul sont des machines virtuelles provisionnées dans ton compte cloud également. C'est toujours du cloud, mais contrairement à Snowflake où tout est complètement abstrait, ici tu vois les ressources dans ta console AWS/Azure/GCP (les VM, les buckets, etc..).
Unity Catalog → La couche de gouvernance. C'est l'équivalent de la couche Cloud Services de Snowflake pour la partie sécurité, droits d'accès, lineage et catalogue de données etc..
La différence fondamentale ici, c'est que tes données restent dans ton stockage cloud, dans un format ouvert. Chez Snowflake, les données sont dans un format propriétaire géré par Snowflake. Chez Databricks, tu peux accéder aux fichiers Parquet par exemple directement depuis ton bucket S3 si tu veux.
Le compute : virtual warehouse vs cluster Spark
Snowflake
Comme on l'a vu, chez Snowflake, tu choisis une taille de warehouse (X-Small, Small, Medium... jusqu'à 6X-Large), et c'est tout. Pas de configuration, pas de choix de type de machine etc...
Tu veux plus de puissance ? Tu montes d'une taille (scale up). Tu as beaucoup d'utilisateurs en parallèle ? Tu actives le multi-cluster (scale out). Et tu payes à la seconde, avec un minimum d'une minute.
La grande force de Snowflake c'est la simplicité. Un analyste qui ne connaît rien à l'infra peut lancer des requêtes sans se poser de questions.
Snowflake propose aussi du Serverless Compute pour certaines fonctionnalités comme Snowpipe, les tasks serverless, le clustering automatique ou le Search Optimization Service. Là, tu ne gères même pas de warehouse car Snowflake alloue et facture le compute tout seul en arrière-plan. C'est encore un cran au-dessus en termes de simplicité.
Databricks : flexible mais plus technique
Chez Databricks, le compute passe par des clusters. Et là, tu as beaucoup plus de leviers :
Tu choisis le type de machine (CPU, mémoire, GPU), tu configures le nombre de workers, tu décides du mode (interactif, job, SQL warehouse), tu peux ajouter des librairies, choisir la version de Spark et activer l'auto-scaling.
Donc c'est beaucoup plus flexible. Un data scientist peut monter un cluster avec des GPU pour entraîner un modèle, pendant qu'un data engineer a un cluster classique pour ses transformations de données et pipelines. Mais ça demande une expertise technique que Snowflake n'a pas besoin.
Databricks a aussi des SQL Warehouses (anciennement SQL Endpoints) qui se rapprochent de l'expérience Snowflake pour les requêtes SQL pures. Mais globalement sans mentir la plateforme reste plus technique que snowflake.
Le langage : SQL-first vs code-first
C'est une des différences les plus visibles au quotidien.
Snowflake = SQL first
Chez Snowflake, 90 % de ce que tu fais passe par du SQL. Créer des tables, charger des données, construire des pipelines (streams, tasks, dynamic tables), gérer les accès, tout se fait en SQL.
Snowflake a ajouté Snowpark pour faire du Python, Java et Scala, mais le cœur de la plateforme reste quand même SQL-first. Et c'est justement ce qui la rend accessible car si tu sais écrire du SQL, tu peux travailler sur Snowflake.
Databricks = code first
Chez Databricks, l'approche est différente. L'outil de travail principal, c'est le notebook. Tu y écris du Python (PySpark), du Scala, du R ou du SQL. Tu manipules des DataFrames Spark, tu appelles des librairies ML, tu chaînes des transformations.
Le SQL est supporté (et de mieux en mieux avec Databricks SQL), mais le socle historique de Databricks reste Python et le code. Si tu maîtrises très bien Python, tu vas te sentir à la maison sur Databricks. Mais si t'es un grand fan de SQL comme moi, Snowflake sera plus naturel.
Le Machine Learning
C'est probablement là où la différence est la plus nette. Et vu que je ne suis pas data scientist, je ne vais pas trop entrer dans les détails, mais voici les grandes lignes à retenir.
Databricks : le ML est dans l'ADN
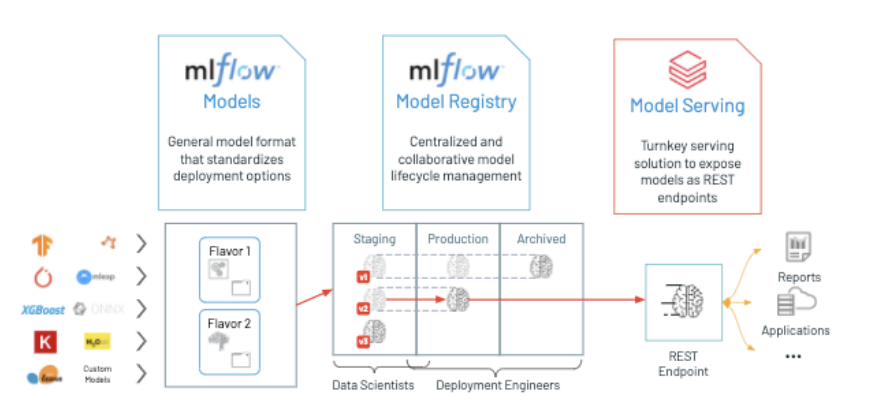
Databricks a été construit pour ça. La plateforme intègre nativement tout l'écosystème ML avec Apache Spark pour le traitement distribué, MLflow pour le suivi des expérimentations et le déploiement des modèles, des notebooks collaboratifs, le Feature Store pour centraliser les features, le Model Serving pour exposer des modèles en production, et un support natif pour le deep learning et les LLM.
Un data scientist sur Databricks peut lire les données, préparer ses features, entraîner un modèle, le versionner et le déployer, tout dans la même plateforme, sans sortir les données ni monter d'infra séparée.
Snowflake : ML possible, mais ...
Snowflake a rattrapé un peu son retard avec Snowpark ML et Cortex AI, car aujourd'hui, tu peux entraîner des modèles simples directement dans Snowflake, et avec Cortex AI tu as accès à des fonctions d'IA intégrées (classification, sentiment, embeddings, etc...) directement. C'est utile et de plus en plus puissant, mais d'après ce que j'ai pu voir, Databricks reste devant pour les cas d'usage ML avancés et surtout beaucoup plus intégré nativement sur toute la chaîne ML.
La gouvernance et la sécurité
Snowflake
C'est un des points forts historiques de Snowflake. Comme on l'a vu dans les articles sur les rôles système, les accès et le masquage dynamique, Snowflake a une gouvernance très mature dès le départ avec des rôles hiérarchiques, chiffrement always-on, masking policies, row access policies, Time Travel, data sharing sécurisé.
Tout est intégré nativement et ne nécessite pas de configuration complexe.
Databricks
D'après ce que j'ai pu analyser Databricks a longtemps eu un point faible sur la gouvernance. Mais avec Unity Catalog, la donne a changé. Unity Catalog apporte un catalogue centralisé, des droits d'accès fins (table, colonne, ligne), du lineage automatique, de l'audit logging et la gestion des objets (données, modèles ML, notebooks).
C'est devenu très solide, mais c'est plus récent que ce que Snowflake propose depuis des années.
Les formats de données : ouvert vs propriétaire
C'est un sujet qui revient souvent dans les discussions et que je trouve important à comprendre.
Databricks : formats ouverts
Databricks stocke les données en Delta Lake (basé sur Parquet), un format open source. Ça veut dire que tes données sont dans des fichiers standards sur ton propre stockage cloud. Tu peux les lire avec d'autres outils (Spark, Trino, Flink etc...) sans dépendre de Databricks. Il y a aussi le support d'Apache Iceberg.
L'argument de Databricks, c'est le zéro vendor lock-in car tes données t'appartiennent, dans un format ouvert, et tu peux changer de plateforme si tu veux sans rien perdre.
Snowflake : format propriétaire, mais ouverture en cours
Chez Snowflake, les données sont stockées dans un format propriétaire compressé et colonnaire. Tu ne vois pas les fichiers directement, c'est Snowflake qui gère le stockage. C'est très optimisé en termes de performances, mais tu es lié à Snowflake pour accéder à tes données.
Cependant, Snowflake a évolué sur ce sujet. Avec le support des Iceberg Tables et le Open Catalog, tu peux désormais stocker des données dans un format ouvert tout en les interrogeant depuis Snowflake. C'est un pas important vers plus d'ouverture, même si le cœur de la plateforme reste propriétaire.
Le pricing : deux modèles différents
Snowflake
Le modèle est simple et prédictible car tu payes le stockage (au To/mois) et le compute (en crédits, facturés à la seconde). Plus le warehouse est gros, plus il consomme de crédits par heure. Comme on l'a vu dans l'article sur l'architecture, un X-Small coûte 1 crédit/heure, un Small 2 crédits/heure, un Medium 4, etc....
C'est lisible et souvent prédictible. Tu sais ce que tu consommes et tu peux anticiper la facture.
Databricks
Chez Databricks, le pricing est un peu plus complexe. Tu payes les DBU (Databricks Units) pour le compute Databricks, le stockage cloud directement auprès de ton cloud provider (AWS, Azure, GCP) puisque les données sont sur ton cloud, et les VM du cluster qui tournent dans ton compte cloud.
Le coût total est moins lisible parce qu'il combine la facture Databricks et la facture cloud. Tu peux potentiellement payer moins cher (surtout pour le stockage, car le cloud storage est vraiment peu cher aujourd'hui), mais ça demande plus de suivi et d'optimisation.
| Critère | Snowflake | Databricks |
|---|---|---|
| Origine | Data warehouse cloud | Big data / Apache Spark |
| Architecture | Stockage propriétaire + virtual warehouses | Lakehouse (Delta Lake sur cloud storage + clusters Spark) |
| Types de données | Structuré + semi-structuré (VARIANT) + non structuré (stages) | Structuré + semi-structuré + non structuré (nativement dans le lake) |
| Langage principal | SQL-first | Code-first (Python, Scala, R, SQL) |
| Compute | Virtual warehouses (tailles fixes, simple) + serverless | Clusters Spark (flexibles, plus techniques) + serverless |
| Machine Learning | Snowpark ML + Cortex AI (en progression) | Natif (MLflow, GPU, Feature Store, Model Serving) |
| Format des données | Propriétaire (+ support Iceberg) | Ouvert (Delta Lake, Iceberg, Parquet) |
| Gouvernance | Mature, native, intégrée | Unity Catalog (solide, mais plus récent) |
| Facilité d'utilisation | Très accessible | Plus technique (clusters, notebooks, configuration) |
| Pricing | Crédits Snowflake (simple) | DBU + cloud infra (plus complexe) |
| Idéal pour | BI, analytics SQL, data warehouse, semi-structuré, Data engineering, équipes SQL | ML/AI, Data engineering, big data, streaming, équipes Python/Scala |
Ce ne sont pas des concurrents directs sur tout.. Mais ils le deviennent de plus en plus, car aujourd'hui la grande majorité des fonctionnalités peuvent se faire dans les deux plateformes, avec un degré de facilité qui diffère mais ça reste possible des deux côtés. Et dès qu'un éditeur sort une nouvelle fonctionnalité, l'autre ne tarde pas à faire pareil.
Snowflake a ajouté Snowpark (Python, Java, Scala), Snowpark ML, Cortex AI, le support Iceberg, les Notebooks, DBT et même Snowpark Container Services pour exécuter des containers Docker. Databricks a ajouté Databricks SQL (un moteur SQL pur), Unity Catalog, le support Iceberg, et même Lakebase (un moteur OLTP basé sur Postgres) et bien d'autres choses.
Les deux plateformes essaient de devenir la plateforme unifiée pour la data et l'IA, où tu peux tout faire dedans sans avoir à sortir de leur écosystème. Et c'est pour ça que la question "Snowflake ou Databricks ?" revient si souvent car la frontière entre les deux se rapproche chaque année.
Mais pour moi, les forces historiques restent toujours vraies car Snowflake excelle en SQL et en simplicité, Databricks excelle en ML et en flexibilité.
Aller plus loin : Formation Snowflake
J'ai regroupé tous mes articles Snowflake dans un parcours complet.
👉 Découvrir tous les articles de la Formation Snowflake
Vous voulez que je vous accompagne sur votre projet data (Snowflake, ingestion, modélisation, performance, coûts, gouvernance) ?