
Jusqu'ici dans la formation, on a manipulé Snowflake exclusivement en SQL. On a créé des tables, des vues, des streams, des tasks, on a chargé des fichiers via les stages et Snowpipe, on a interrogé du semi-structuré avec VARIANT et FLATTEN… tout en SQL.
Sauf que dans la vraie vie, il y a des moments où le SQL ne suffit pas. Tu dois appeler une API externe, appliquer un modèle de machine learning, faire du nettoyage complexe avec pandas, ou tout simplement écrire de la logique métier qu'un CASE WHEN ne peut pas couvrir proprement.
C'est exactement là qu'intervient Snowpark.
Snowpark, c'est un ensemble de librairies qui te permet d'écrire du Python, du Java ou du Scala pour manipuler tes données directement dans Snowflake, sans les sortir de la plateforme.
Concrètement, au lieu d'extraire tes données vers un serveur externe pour les transformer en Python, tu écris ton code Python et Snowflake l'exécute directement sur ses propres virtual warehouses. Tes données ne bougent pas et le compute reste dans Snowflake.
Dans cet article, je vais me concentrer uniquement sur Snowpark en utilisant Python, parce que c'est de loin le langage le plus utilisé dans l'écosystème data mais la logique reste la même avec du java ou scala.
Pourquoi Snowpark existe
Avant Snowpark, si tu voulais faire du Python avec des données Snowflake, tu avais deux options :
Option 1 : le connecteur Python classique — Tu te connectes à Snowflake avec le snowflake-connector-python, tu envoies des requêtes SQL sous forme de chaînes de caractères, et tu récupères les résultats en local. Le souci ? Tu déplaces les données vers ta machine. Sur 10 000 lignes, ça passe. Sur 10 millions, ça rame. Et tu n'as aucun des avantages de l'autocomplétion ou du typage sur tes requêtes SQL.
Option 2 : Spark + connecteur Snowflake — Tu montes un cluster Spark, tu lis les données depuis Snowflake, tu transformes, et tu réécris. Ça fonctionne, mais tu gères un cluster séparé, tu paies du compute en dehors de Snowflake, et tu as du transfert de données entre les deux.
Snowpark résout ces deux problèmes. Tu écris du Python avec une API DataFrame (qui ressemble beaucoup à pandas ou PySpark), et Snowflake traduit tout ça en SQL optimisé qui s'exécute côté serveur. Tes données restent dans Snowflake, et c'est ton virtual warehouse qui fait le travail.
Avec Snowpark, le code Python que tu écris est traduit en SQL et exécuté sur les virtual warehouses de Snowflake. Tu codes en Python, mais c'est Snowflake qui calcule.
Installer Snowpark et se connecter
L'installation est simple :
pip install snowflake-snowpark-python
Ensuite, tu crées une session (une connexion) :
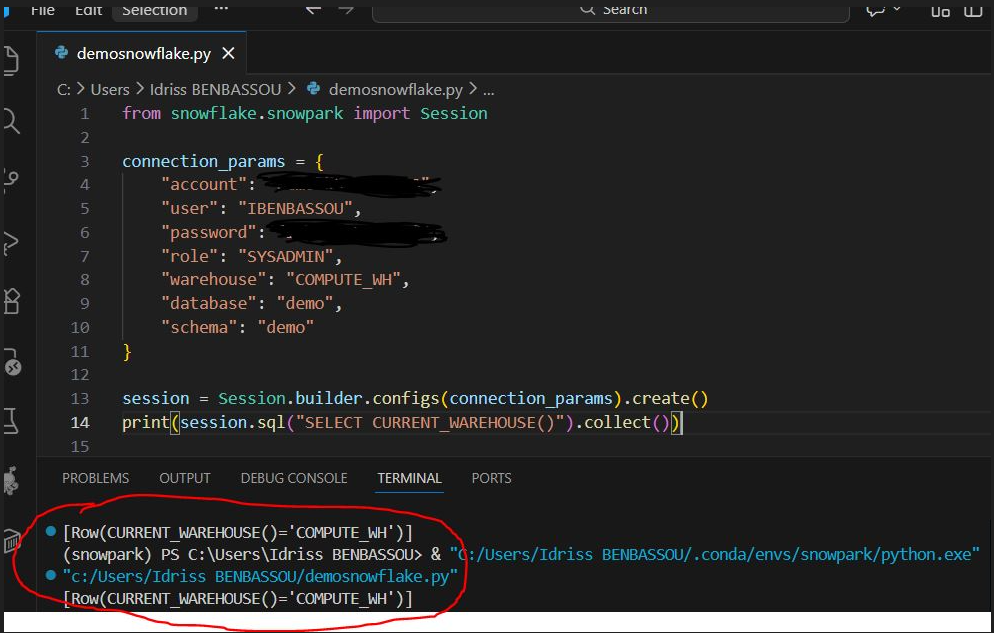
from snowflake.snowpark import Session
connection_params = {
"account": "mon_compte",
"user": "mon_user",
"password": "mon_mot_de_passe",
"role": "SYSADMIN",
"warehouse": "<Nom Compute>",
"database": "<Nom Base>",
"schema": "<Nom Schema>"
}
session = Session.builder.configs(connection_params).create()
print(session.sql("SELECT CURRENT_WAREHOUSE()").collect())
Si tu utilises Snowsight (l'interface web de Snowflake), tu peux aussi écrire du Snowpark directement dans un Python Worksheet sans rien installer. La session est déjà pré-configurée.
Le DataFrame Snowpark : la base
Le concept central de Snowpark, c'est le DataFrame. Si tu connais pandas ou PySpark, tu vas te sentir à la maison. La différence clé, c'est que le DataFrame Snowpark ne charge pas les données en mémoire. Il construit un plan d'exécution SQL et l'envoie à Snowflake uniquement quand tu le demandes.
C'est ce qu'on appelle l'évaluation lazy car rien ne s'exécute tant que tu n'appelles pas une action comme .collect(), .show() ou .count().
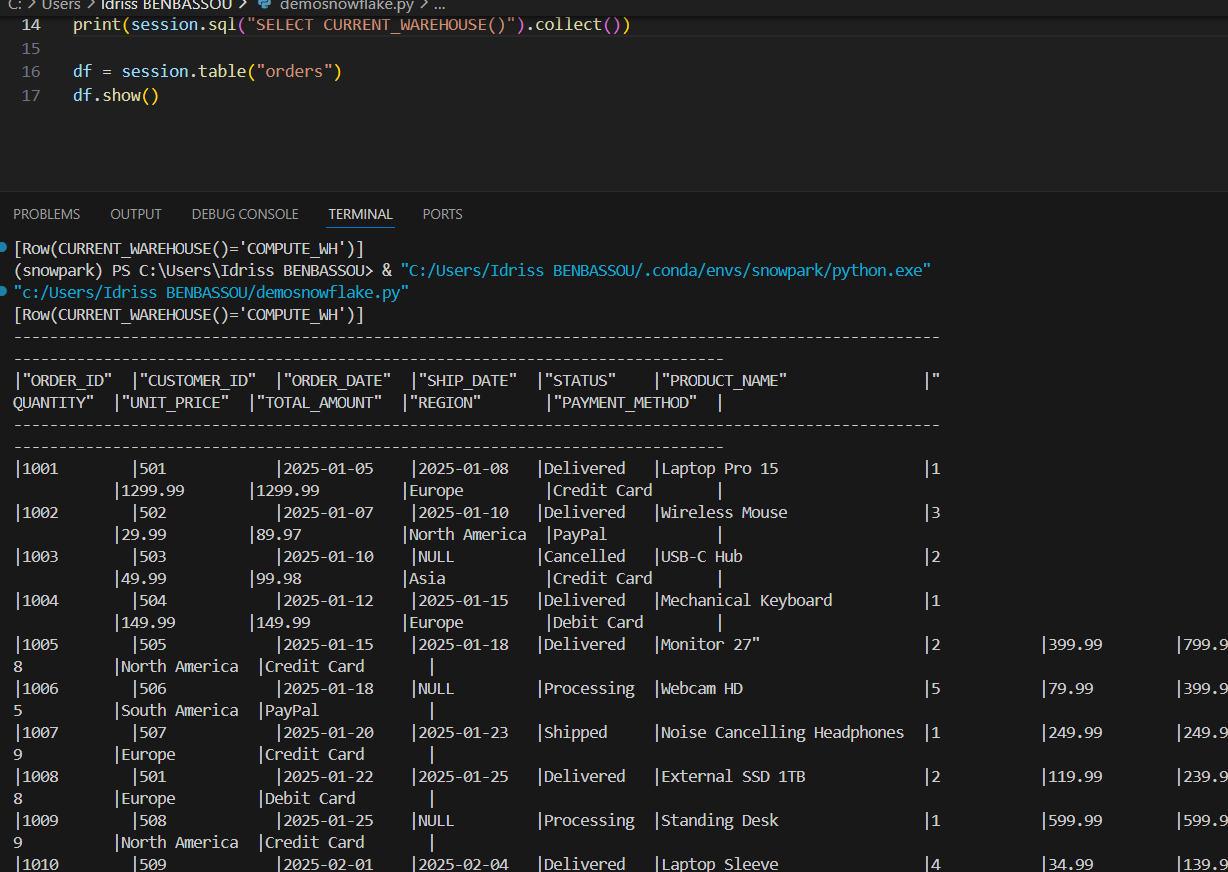
Lire une table
df = session.table("orders")
df.show()
C'est aussi simple que ça. df est un DataFrame qui pointe vers ta table orders. .show() déclenche l'exécution et affiche les résultats.
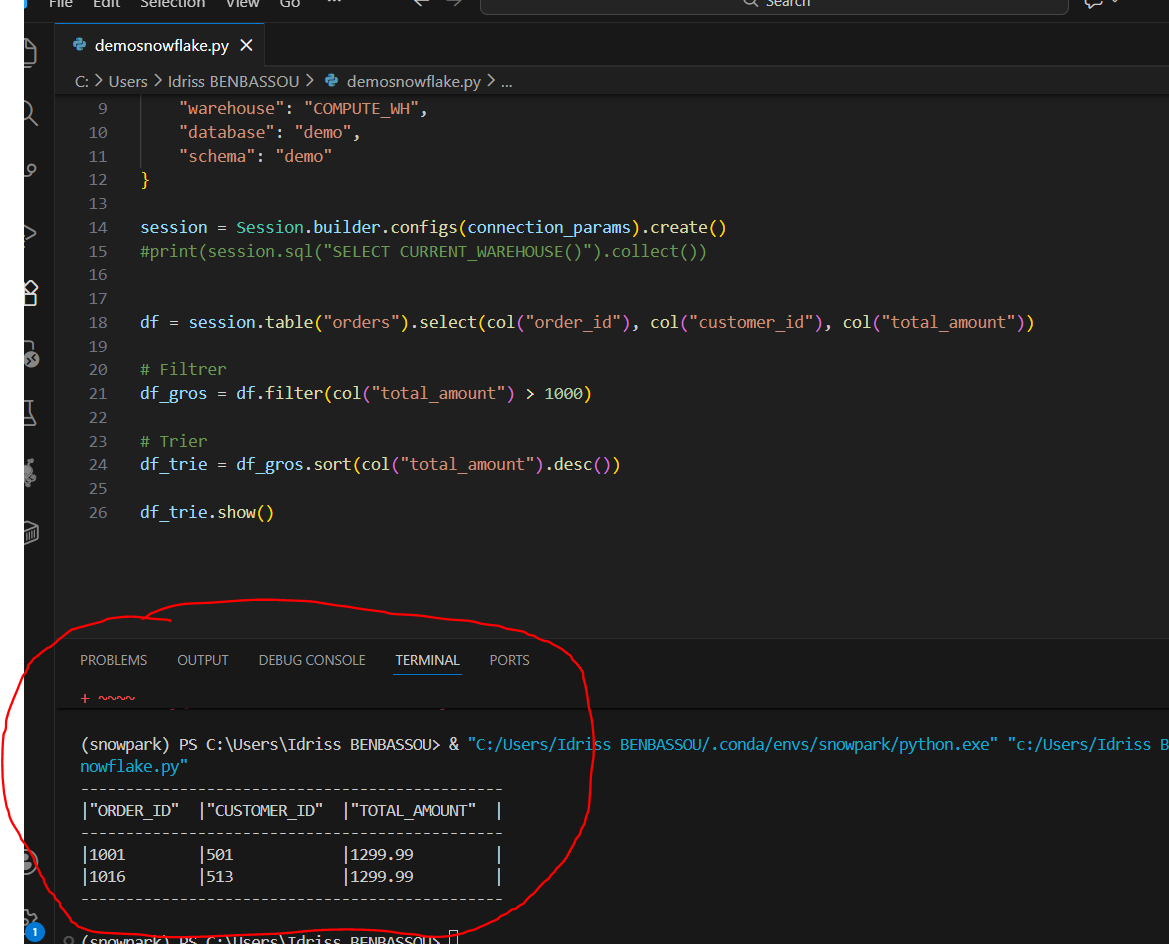
Filtrer, sélectionner, trier
from snowflake.snowpark.functions import col
# Sélectionner des colonnes
df = session.table("orders").select(col("order_id"), col("customer_id"), col("total_amount"))
# Filtrer
df_gros = df.filter(col("total_amount") > 1000)
# Trier
df_trie = df_gros.sort(col("total_amount").desc())
df_trie.show()
Jusque-là, c'est du SQL déguisé en Python. Et c'est exactement l'idée. Snowpark traduit cela en :
SELECT order_id, customer_id, total_amount
FROM orders
WHERE total_amount > 1000
ORDER BY total_amount DESC;
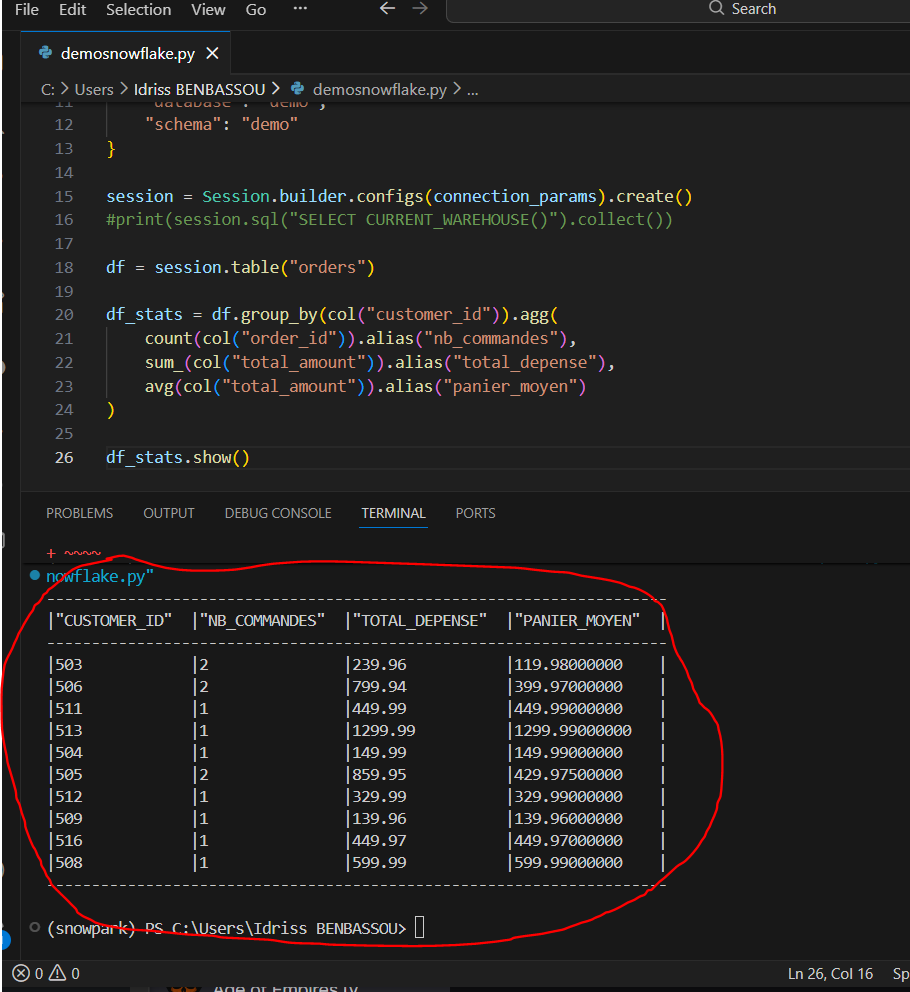
Agréger
from snowflake.snowpark.functions import col, sum as sum_, count, avg
df = session.table("orders")
df_stats = df.group_by(col("customer_id")).agg(
count(col("order_id")).alias("nb_commandes"),
sum_(col("total_amount")).alias("total_depense"),
avg(col("total_amount")).alias("panier_moyen")
)
df_stats.show()
Note : on importe sum avec un alias sum_ pour éviter le conflit avec le sum natif de Python.
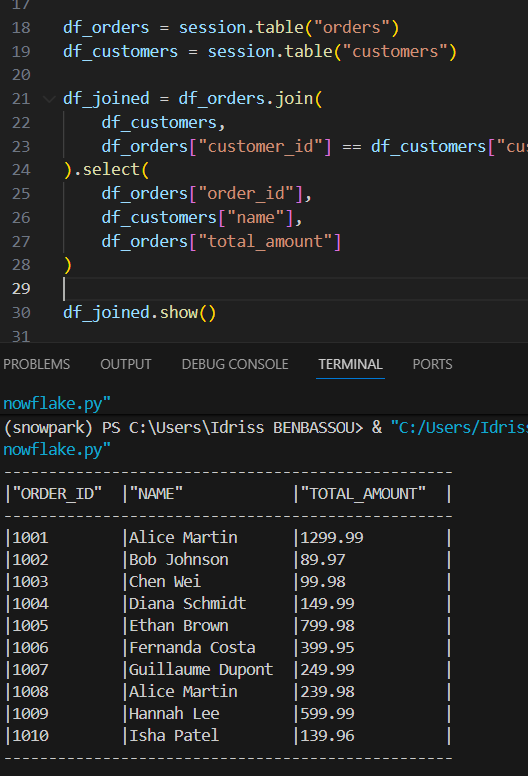
Joindre deux tables
df_orders = session.table("orders")
df_customers = session.table("customers")
df_joined = df_orders.join(
df_customers,
df_orders["customer_id"] == df_customers["customer_id"]
).select(
df_orders["order_id"],
df_customers["name"],
df_orders["total_amount"]
)
df_joined.show()
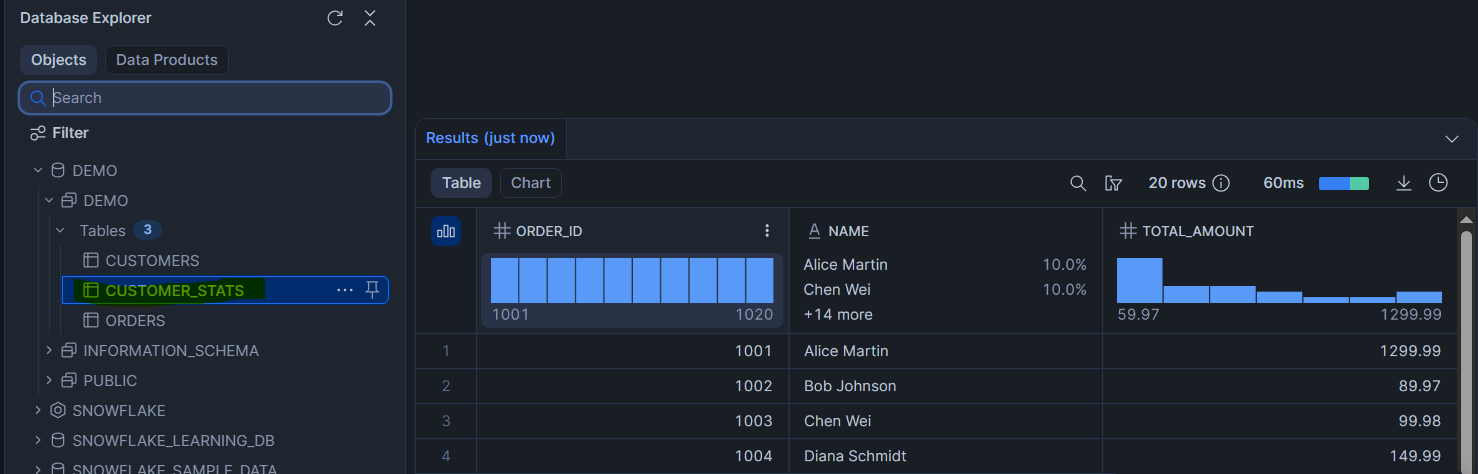
Écrire le résultat dans une table
df_joined.write.mode("overwrite").save_as_table("customer_stats")
Une ligne. Le DataFrame df_stats est matérialisé dans une nouvelle table customer_stats. Le mode overwrite remplace la table si elle existe déjà.
Voir le SQL généré
Un truc très pratique pour comprendre ce que Snowpark fait sous le capot, c'est d'afficher le SQL généré sans l'exécuter :
print(df_joined.queries)
Ça te montre la requête SQL que Snowpark va envoyer à Snowflake. C'est hyper utile pour debugger ou pour vérifier que le plan d'exécution a du sens.

Les UDF Python : exécuter du code custom Python sur chaque ligne
Le DataFrame, c'est bien pour les transformations classiques (filtrer, joindre, agréger). Mais parfois tu as besoin d'appliquer une logique Python sur chaque ligne et c'est là qu'interviennent les UDFs (User-Defined Functions).
Avec Snowpark, tu peux créer une UDF Python et l'appliquer directement dans tes requêtes. Le code Python est envoyé à Snowflake et exécuté côté serveur, sur le virtual warehouse.
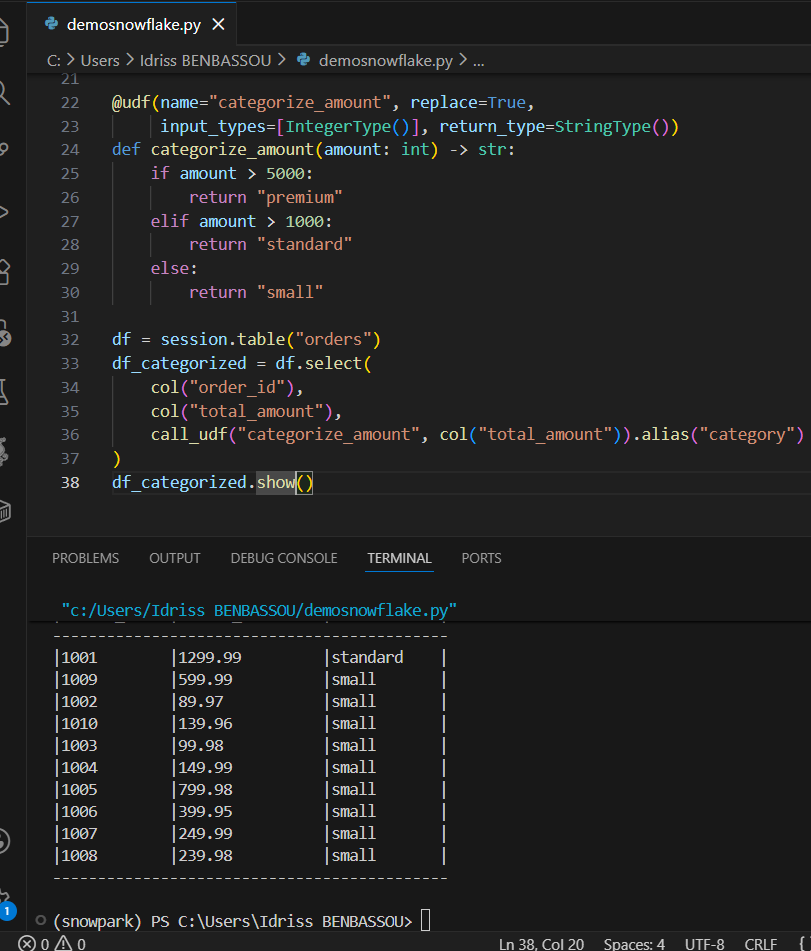
Exemple UDF :
from snowflake.snowpark.functions import udf
from snowflake.snowpark.types import StringType, IntegerType
# Définir une UDF qui catégorise le montant
@udf(name="categorize_amount", replace=True,
input_types=[IntegerType()], return_type=StringType())
def categorize_amount(amount: int) -> str:
if amount > 5000:
return "premium"
elif amount > 1000:
return "standard"
else:
return "small"
Ensuite, tu l'utilises comme n'importe quelle fonction dans ton DataFrame :
from snowflake.snowpark.functions import col, call_udf
df = session.table("orders")
df_categorized = df.select(
col("order_id"),
col("total_amount"),
call_udf("categorize_amount", col("total_amount")).alias("category")
)
df_categorized.show()
Et tu peux même l'appeler directement en SQL dans un worksheet Snowflake :
SELECT order_id, total_amount, categorize_amount(total_amount ) AS category
FROM orders;
L'UDF est exécutée côté serveur, sur le virtual warehouse. Ton code Python est pushé vers Snowflake, pas l'inverse. Les données ne sortent jamais de la plateforme.
Les Stored Procedures Snowpark
Si les UDFs transforment des données ligne par ligne, les stored procedures Snowpark sont faites pour des traitements plus complexes comme orchestrer un pipeline, charger et transformer des données, appeler plusieurs tables, écrire des résultats....
Exemple : une stored procedure qui calcule des stats client
from snowflake.snowpark.functions import sproc
from snowflake.snowpark.types import StringType
@sproc(name="build_customer_stats", replace=True,
packages=["snowflake-snowpark-python"],
is_permanent=True, stage_location="@demo_stage")
def build_customer_stats(session) -> str:
df = session.table("orders")
df_stats = df.group_by("customer_id").agg(
{"order_id": "count", "total_amount": "sum"}
)
df_stats = df_stats.to_df(
"customer_id", "nb_commandes", "total_depense"
)
df_stats.write.mode("overwrite").save_as_table("customer_stats")
return "customer_stats mis à jour"
Tu appelles la stored procedure en SQL :
CALL build_customer_stats();
Et tu peux la planifier avec une task :
CREATE OR REPLACE TASK task_customer_stats
WAREHOUSE = WH_ETL
SCHEDULE = 'USING CRON 0 6 * * * UTC'
AS
CALL build_customer_stats();
Maintenant, chaque matin à 6h, Snowflake exécute ta logique Python automatiquement. Le pipeline est entièrement dans Snowflake.
Snowpark vs SQL
Nb : Snowpark ne remplace pas le SQL car les deux coexistent. Et dans beaucoup de cas, le SQL pur reste plus simple et plus efficace.
| Situation | Recommandation |
|---|---|
| Transformations classiques (filtrer, joindre, agréger) | SQL ou DataFrame Snowpark (les deux marchent bien) |
| Logique métier complexe, conditions imbriquées | Snowpark / UDF Python |
| Appel à une API externe ou une librairie Python (scikit-learn, pandas…) | Snowpark |
| Machine learning (entraînement, scoring) | Snowpark + Snowpark ML |
| Pipeline ETL/ELT simple | SQL + streams + tasks ou dynamic tables |
| Pipeline avec du code Python | Snowpark stored procedures + tasks |
| Requêtes ponctuelles, exploration de données | SQL avec Snowsight |
La règle est simple, si tu peux le faire en SQL de façon lisible, fais-le en SQL. Si le SQL devient un monstre illisible ou qu'il te faut du Python (librairies, API, ML), passe à Snowpark.
Où est exécuté le code Snowpark
C'est un point qui crée souvent de la confusion. Il y a deux modes d'exécution :
Client-side (côté client) : Quand tu écris un script Snowpark dans ton IDE (VS Code par exemple), le code Python tourne sur ta machine locale. Mais les opérations sur les DataFrames sont traduites en SQL et envoyées à Snowflake. Donc le compute lourd est fait par le warehouse, mais l'orchestration est locale.
Server-side (côté serveur) : Quand le code est une stored procedure ou une UDF, tout est exécuté directement sur le virtual warehouse Snowflake.
En développement, tu bosses en local. En prod, tu déploies dans une stored procedure pour que tout tourne dans Snowflake.
Les packages disponibles
Snowpark supporte un grand nombre de librairies Python via le canal Anaconda intégré à Snowflake. Tu n'as rien à installer côté serveur, tu déclares juste les packages dont tu as besoin :
@sproc(packages=["snowflake-snowpark-python", "pandas", "scikit-learn"])
def my_procedure(session) -> str:
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
# ...........
Sauf pour les package custom qui ne sont pas dans Anaconda, tu dois le uploader manuellement dans un stage.
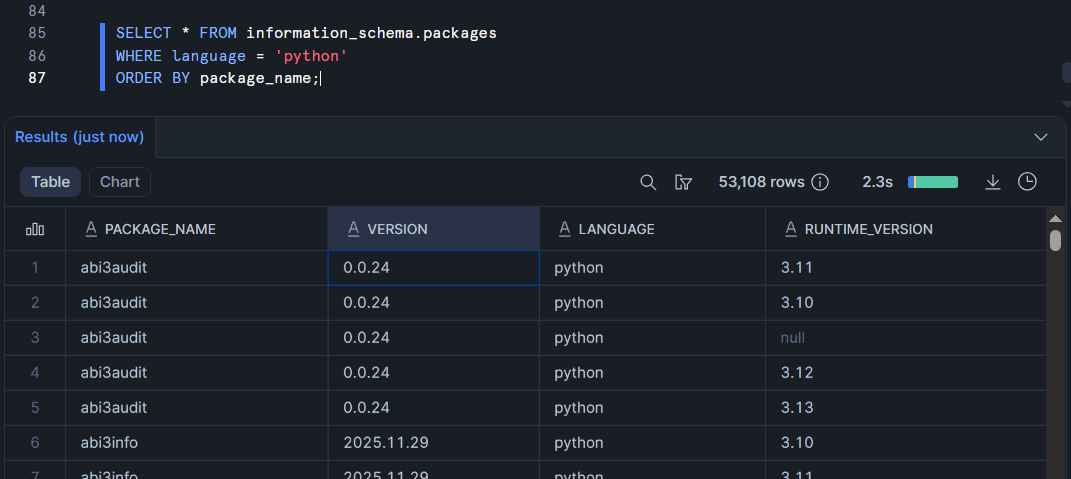
Pour voir tous les packages disponibles :
SELECT * FROM information_schema.packages
WHERE language = 'python'
ORDER BY package_name;
Parmi les packages les plus utilisés : pandas, numpy, scikit-learn, xgboost, scipy, requests, et bien sûr snowflake-snowpark-python lui-même.
Un exemple complet : du stage à la table finale
Pour finir, voici un exemple concret de bout en bout qui combine plusieurs concepts vus dans la formation. On charge 2 fichiers CSV depuis un stage, on les transforment avec Snowpark, et on écrit le résultat dans une table.
from snowflake.snowpark import Session
from snowflake.snowpark.functions import col, upper, when
from snowflake.snowpark.types import StructType, StructField, StringType, IntegerType, DecimalType, DateType
#Lire le fichier orders.csv depuis un stage
df_orders_raw = session.read.schema(
StructType([
StructField("order_id", IntegerType()),
StructField("customer_id", IntegerType()),
StructField("order_date", DateType()),
StructField("ship_date", DateType()),
StructField("status", StringType()),
StructField("product_name", StringType()),
StructField("quantity", IntegerType()),
StructField("unit_price", DecimalType(10, 2)),
StructField("total_amount", DecimalType(10, 2)),
StructField("region", StringType()),
StructField("payment_method", StringType())
])
).option("field_delimiter", ",").option("skip_header", 1).csv("@demo_stage/orders.csv")
#Lire le fichier customers.csv depuis un stage
df_customers_raw = session.read.schema(
StructType([
StructField("customer_id", IntegerType()),
StructField("name", StringType()),
StructField("email", StringType()),
StructField("city", StringType()),
StructField("country", StringType()),
StructField("signup_date", DateType())
])
).option("field_delimiter", ",").option("skip_header", 1).csv("@demo_stage/customers.csv")
#Joindre les deux DataFrames
df_joined = df_orders_raw.join(
df_customers_raw,
df_orders_raw["customer_id"] == df_customers_raw["customer_id"]
)
#mettre le nom en majuscule, catégoriser le montant
df_clean = df_joined.select(
df_orders_raw["order_id"],
upper(col("name")).alias("customer_name"),
col("city"),
col("region"),
col("product_name"),
col("total_amount"),
col("status"),
when(col("total_amount") > 500, "premium")
.when(col("total_amount") > 100, "standard")
.otherwise("small")
.alias("category")
)
#écrire dans une table
df_clean.write.mode("overwrite").save_as_table("orders_clean")
#display
session.table("orders_clean").show()Aller plus loin : Formation Snowflake
J'ai regroupé tous mes articles Snowflake dans un parcours complet.
Vous voulez que je vous accompagne sur votre projet data (Snowflake, ingestion, modélisation, performance, coûts, gouvernance) ?