
Dans les articles précédents, on a créer une solide démarche d'optimisation des performances en commençant par le Query Profile pour diagnostiquer, le Clustering pour réduire le volume de données lues, et le QAS pour accélérer les gros scans en parallélisant le travail.
Mais il y a un type de requête qu'on n'a pas encore couvert, et que ni le clustering ni le QAS ne gèrent bien.
Imagine une table ORDERS de plusieurs centaines de millions de lignes, et tu veux retrouver une commande précise comme par exemple
SELECT *
FROM orders
WHERE order_id = 'ORD-2024-00458712';Cette requête ne retourne qu'une seule ligne. Pourtant, sans optimisation, Snowflake peut scanner des centaines de micro-partitions pour la trouver. Le clustering ne t'aide pas forcément ici, parce que la table est peut-être déjà clusterisée sur order_date, pas sur order_id. Et le QAS ne sert à rien non plus, parce qu'il accélère les gros scans, pas les recherches d'une valeur précise.
Et si tu as bien suivi, c'est exactement le problème que résout le Search Optimization Service (SOS).
C'est quoi concrètement le Search Optimization Service ?
Le SOS est un service qui crée et maintient une structure de données supplémentaire appelée Search Access Path. Pour simplifier tu peux le voir comme un index car il sait exactement dans quelles micro-partitions se trouvent les valeurs d'une colonne.
Pour bien comprendre la différence avec ce qu'on a vu avant :
- Les métadonnées des micro-partitions (qu'on a vues dans l'article sur le l'architeture snowflake) stockent les min/max de chaque partition. Donc Snowflake peut éliminer les partitions dont la plage ne contient pas ta valeur.
- Le clustering réorganise les données pour que les valeurs similaires soient dans les mêmes partitions. Les min/max deviennent plus serrés et donc le pruning est plus efficace.
- Le Search Access Path va alors plus loin car il sait précisément quelles valeurs sont dans quelles partitions. Pas juste les min/max, mais les valeurs elles mêmes.
Pour une requête du type WHERE order_id = 'ORD-2024-00458712', le SOS peut pointer directement vers les 1 ou 2 partitions qui contiennent cette valeur, même si la table a 10 000 partitions.
SOS vs Clustering : quelle différence ?
C'est la question que je me suis poser au début et qui revient tout le temps, et c'est normal parce que les deux améliorent le pruning. Mais ils ne le font pas de la même manière.
Rappelle-toi dans l'article sur le Clustering et comme je l'ai mentionné précédemment le clustering réorganise physiquement les données pour que les valeurs similaires soient regroupées dans les mêmes micro-partitions. C'est une réorganisation des données elles-mêmes.
Le SOS ne touche pas aux données et au partition. Il crée une structure additionnelle (le Search Access Path ou un index si on veut simplifier les notions) qui référence où se trouvent les valeurs. Les micro-partitions restent exactement comme elles sont.
Alors concrètement :
- Le Clustering est fait pour les requêtes qui filtrent sur des plages de valeurs (
WHERE date BETWEEN ... AND ...,WHERE amount > 1000). Il est excellent quand tu filtres souvent sur les mêmes colonnes. - Le SOS est fait pour les requêtes qui cherchent des valeurs exactes (
WHERE id = ...,WHERE email = ...,WHERE status IN (...)). Il est parfait sur des colonnes à haute cardinalité.
Nb: les deux sont complémentaires car tu peux avoir une table clusterisée sur order_date et avec le SOS activé sur order_id. Donc le clustering accélère les requêtes par plage de dates, et le SOS accélère les recherches par ID.
Quels types de requêtes le SOS peut accélérer ?
Le SOS couvre un large panel de requêtes, bien plus que juste les WHERE column = valeur :
Recherches par égalité et IN :
WHERE customer_id = 12345
WHERE status IN ('shipped', 'delivered')Recherches de sous-chaînes (LIKE, ILIKE, RLIKE) :
WHERE email LIKE '%@gmail.com'
WHERE product_name ILIKE '%snowflake%'Recherche plein texte avec SEARCH :
WHERE SEARCH(description, 'performance optimization')Recherche sur des données semi-structurées (VARIANT) :
WHERE payload:user:country::STRING = 'France'Recherche géospatiale (GEOGRAPHY) :
WHERE ST_WITHIN(location, polygon)Vérification de NULL :
WHERE column IS NULLRequêtes qui ne bénéficient pas du SOS
Le SOS ne fonctionne pas sur tous les cas :
- Les requêtes sur des colonnes de type FLOAT ou GEOMETRY
- Les requêtes avec un cast sur la colonne de la table (par exemple
WHERE CAST(col AS NUMBER) = 2). Et sans surprise, les transformations sur les colonnes cassent l'optimisation, que ce soit pour les métadonnées, le clustering, ou le SOS... - Les vues matérialisées
- Les tables petites (aucun intérêt)
Comment activer le SOS
Le SOS s'active au niveau de la table, pas de la warehouse (contrairement au QAS). Et la bonne pratique, c'est de l'activer sur des colonnes spécifiques, pas sur toute la table.
Activer le SOS sur des colonnes spécifiques (recommandé)
-- Activer le SOS pour les recherches par égalité sur customer_id et order_id
ALTER TABLE orders
ADD SEARCH OPTIMIZATION ON EQUALITY(customer_id, order_id);Activer le SOS pour les sous-chaînes
-- Activer le SOS pour les recherches LIKE sur email
ALTER TABLE orders
ADD SEARCH OPTIMIZATION ON SUBSTRING(email);Activer le SOS sur toute la table
-- Active le SOS pour les recherches par égalité sur toutes les colonnes éligibles
ALTER TABLE orders
ADD SEARCH OPTIMIZATION;Vérifier la configuration
DESCRIBE SEARCH OPTIMIZATION ON orders;Cette commande te montre quelles colonnes sont optimisées et avec quelles méthodes (EQUALITY, SUBSTRING, GEO...).
Le Search Access Path : ce qui se passe en arrière-plan
Quand tu actives le SOS, Snowflake lance un service de maintenance en arrière-plan qui construit le Search Access Path. Ce processus peut prendre du temps selon la taille de la table.
Tu peux suivre la progression avec :
SHOW TABLES LIKE 'orders';Regarde la colonne search_optimization_progress. Quand elle affiche 100%, la table est entièrement optimisée.
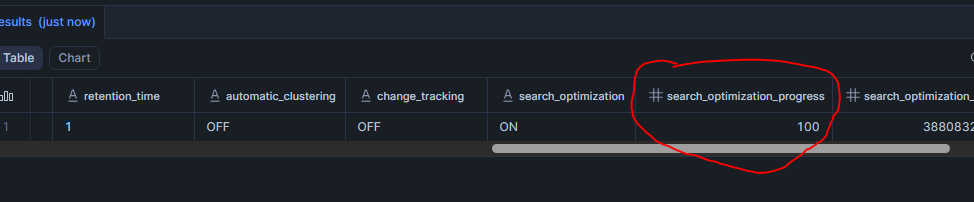
Et pour info, la création de Search Access Path ne bloque aucune opération sur la table et c'est un service serverless.
Estimer les coûts avant d'activer le SOS
Comme pour le clustering et le QAS, le SOS a un coût. Mais contrairement au QAS (qui ne coûte que quand il est utilisé), le SOS a deux types de coûts permanents :
- Stockage : le Search Access Path occupe de l'espace. En général, environ 1/4 de la taille de la table, mais ça peut aller jusqu'à la taille de la table si toutes les valeurs sont uniques.
- Compute de maintenance : chaque fois que les données changent, le Search Access Path doit être mis à jour. Plus ta table a des updates fréquents (insertions, mises à jour, suppressions fréquentes), plus ça coûte.
Avant d'activer le SOS, utilise la fonction d'estimation :
SELECT SYSTEM$ESTIMATE_SEARCH_OPTIMIZATION_COSTS('orders');Pour estimer le coût sur des colonnes spécifiques :
SELECT SYSTEM$ESTIMATE_SEARCH_OPTIMIZATION_COSTS(
'orders',
'EQUALITY(customer_id, order_id)'
);Le résultat te donne trois informations :
BuildCosts : le coût unique de création du Search Access Path (en crédits)
StorageCosts : le coût de stockage (en TB/mois)
MaintenanceCosts : le coût mensuel de maintenance (en crédits)
Exemple concret : point lookup sur LINEITEM
On reprend la table LINEITEM qu'on utilise depuis le début de la série, dans la base SNOWFLAKE_SAMPLE_DATA.
Sans le SOS
SELECT *
FROM SNOWFLAKE_SAMPLE_DATA.TPCH_SF100.LINEITEM
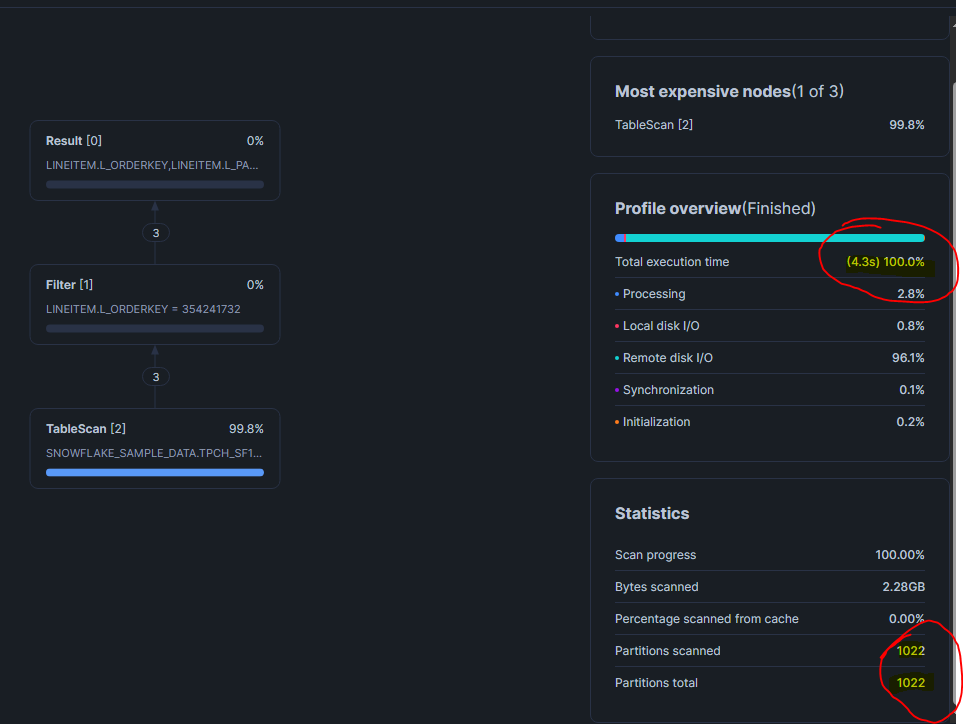
WHERE L_ORDERKEY = 354241732;Cette requête cherche toutes les lignes d'une commande précise dans LINEITEM. Sans le SOS, Snowflake utilise les métadonnées min/max des micro-partitions pour éliminer ce qu'il peut. Mais L_ORDERKEY a une très haute cardinalité (des centaines de millions de valeurs), et si la table n'est pas clusterisée sur cette colonne, Snowflake va quand même scanner beaucoup de partitions.
Dans le Query Profile, tu verrais un nombre élevé de partitions scannées par rapport au total, exactement comme dans nos exemples précédents.
Avec le SOS
-- On crée d'abord une copie pour pouvoir activer le SOS
CREATE TABLE lineitem_with_sos AS
SELECT * FROM SNOWFLAKE_SAMPLE_DATA.TPCH_SF100.LINEITEM;
-- On active le SOS sur L_ORDERKEY
ALTER TABLE lineitem_with_sos
ADD SEARCH OPTIMIZATION ON EQUALITY(L_ORDERKEY);Une fois le Search Access Path construit (vérifie avec SHOW TABLES) si le search_optimization_progress est à 100 et ensuite relance la même requête :
SELECT *
FROM lineitem_with_sos
WHERE L_ORDERKEY = 354241732;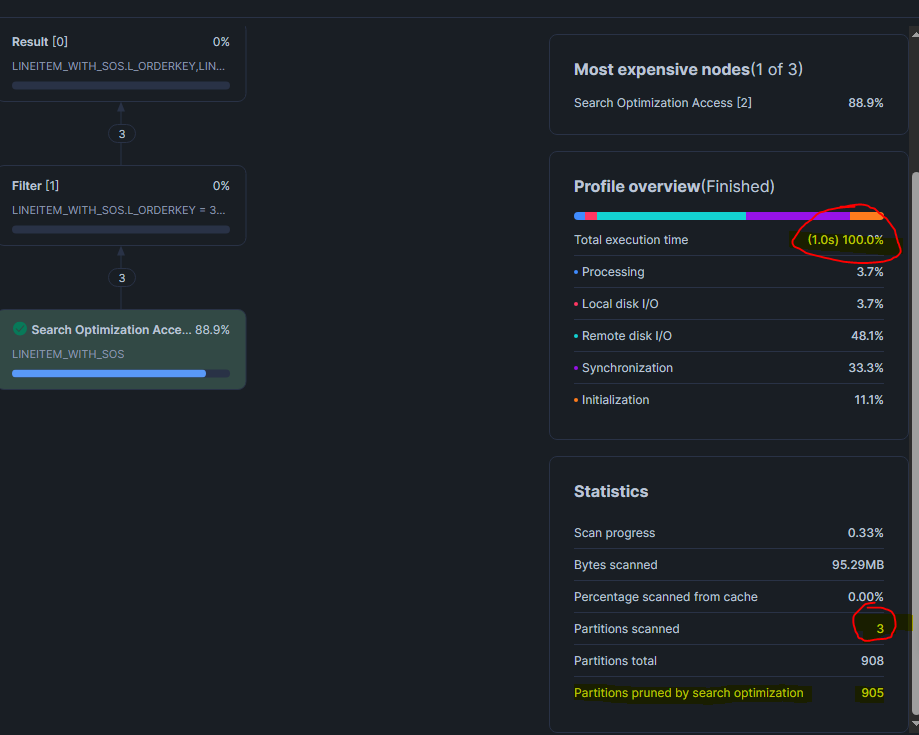
Dans le Query Profile, on constate que le nombre de partitions scannées est passé de 1022 à 3.
L_ORDERKEY a une très haute cardinalité et qu'on cherche une valeur exacte. C'est exactement le cas d'usage pour lequel les métadonnées min/max ne suffisent pas et où le clustering serait trop coûteux sur une colonne aussi granulaire.Surveiller les coûts du SOS
Comme pour le clustering et le QAS, surveille ce que le SOS te coûte réellement.
Voir les crédits
SELECT *
FROM TABLE(INFORMATION_SCHEMA.SEARCH_OPTIMIZATION_HISTORY(
DATE_RANGE_START => DATEADD('day', -7, CURRENT_DATE())
))
ORDER BY START_TIME DESC;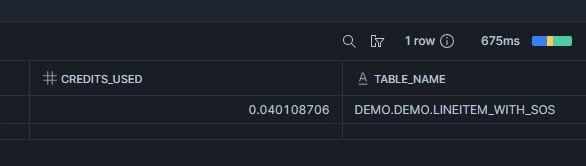
Désactiver le SOS si nécessaire
Si les coûts ne sont pas justifiés, tu peux désactiver le SOS sur des colonnes spécifiques ou sur toute la table :
-- Désactiver sur une colonne
ALTER TABLE orders
DROP SEARCH OPTIMIZATION ON EQUALITY(customer_id);
-- Désactiver complètement
ALTER TABLE orders
DROP SEARCH OPTIMIZATION;Où se situe le SOS dans la boîte à outils performance
On a maintenant quatre leviers d'optimisation mais chacun répond à un problème différent :
1. Query Profile → Diagnostiquer. Comprendre où Snowflake passe son temps et combien de partitions sont scannées.
2. Clustering → Réorganiser. Regrouper les données pour que les filtres par plage (dates, catégories) éliminent plus de partitions.
3. QAS → Paralléliser. Ajouter de la puissance de calcul temporaire pour les gros scans qui ne peuvent pas être réduits davantage.
4. SOS → Indexer. Créer un accès direct aux valeurs exactes sur des colonnes à haute cardinalité.
Si y'a une définition à retenir c'est que le clustering organise mieux les données, le QAS lit plus vite, et le SOS sait exactement où chercher.
Et pour finir, une règle ne change jamais et qui ne se discute pas, peu importe la problématique, commence toujours par le Query Profile. ;)
Aller plus loin : Formation Snowflake
J'ai regroupé tous mes articles Snowflake dans un parcours complet.
👉 Parcours Snowflake : modules et cas pratiques
Vous voulez que je vous accompagne sur votre projet data (Snowflake, ingestion, modélisation, performance, coûts, gouvernance) ?