
Dans les offres d'emploi pour data engineer ou même data analyst aujourd'hui, que ce soit en CDI ou en freelance, il y a de grandes chances de trouver le mot cloud dans les prérequis. Des fois tu as un peu de contexte et les outils précis. Et des fois c'est les RH qui s'emballent avec des noms de services balancés sans trop de sens.
Quand on parle cloud, il y a trois gros acteurs dans le marché de la data ( AWS, Azure et GCP ). Les trois couvrent les mêmes besoins data (stocker, calculer, requêter, orchestrer), avec des noms de services différents mais la même logique derrière. Si tu en maîtrises un, tu transposes vite sur les autres.
Dans cette série, on va se concentrer sur AWS, parce que c'est celui que je connais le mieux, et c'est aussi le plus présent en France.
Maintenant, entrons dans le sujet. AWS, ce n'est pas un outil, c'est un catalogue de plus de 200 services. Et crois-moi, n'essaie pas de comprendre dès le début tous les acronymes du style EC2, VPC, IAM, ECS, EKS, SageMaker, DynamoDB… parce que tu vas avoir mal à la tête. Et, Spoiler, la moitié n'ont aucune importance dans notre métier de la data (data eng, data analyst ou même data scientist).
On ne va pas apprendre AWS en entier mais uniquement un sous-ensemble de service data d'AWS, et on va tout simplement ignorer le reste.
Comment se déroule un vrai projet data
Peu importe le cloud, un projet data suit toujours le même schéma. La donnée arrive brute quelque part, on la range, on la nettoie, on la transforme, on la rend consommable, et on automatise tout ça.
Concrètement, ça se découpe en sept étapes :
- Collecte : faire atterrir la donnée brute (fichiers, exports, API etc...).
- Stockage : ranger cette donnée dans un data lake, organisée par zones.
- Catalogue : décrire ce qu'on a stocké pour pouvoir l'interroger.
- Exploration : requêter la donnée brute pour la comprendre et la valider.
- Transformation : nettoyer, typer, modéliser, charger dans l'entrepôt.
- Orchestration : enchaîner toutes ces étapes automatiquement.
- Sécurité et coûts : protéger la donnée et maîtriser la facture.
Retiens cet ordre. C'est exactement celui qu'on suivra, article après article. Et c'est là qu'AWS prend tout son sens car chaque étape correspond à un ou deux services.
Les services AWS qui comptent pour la data
On reprend les étapes, et on pose le bon service sur chacune.
S3 : le data lake (stockage)
Amazon S3, c'est du stockage objet. En clair, tu y déposes des fichiers (CSV, TXT, JSON, Parquet....) et S3 les garde, point. C'est pas cher et quasiment infini.
C'est la fondation de tout. Sur AWS, le data lake c'est S3. Tes fichiers vivent dans des buckets (des conteneurs de S3, tu peux voir les buckets comme le dossier racine de ton lake), et à l'intérieur tu ranges tout avec des préfixes qui se comportent comme des dossiers. C'est là qu'on organise la donnée en zones (raw, clean, curated) qui correspondent au Bronze, Silver, Gold de l'architecture médaillon.
S3 est le centre de gravité d'AWS pour la data. Tous les autres services lisent ou écrivent dans S3.
Glue Data Catalog : le catalogue
Un fichier Parquet dans S3, tout seul, ce n'est qu'un paquet d'octets. Pour le requêter en SQL, il faut dire à AWS "ce dossier contient une table avec telles colonnes et tels types". Donc Glue Data Catalog est une sorte d'annuaire central qui décrit les données.
Athena : le SQL serverless (exploration)
Amazon Athena, c'est ce qui rend AWS magique pour un profil SQL. Tu poses tes fichiers dans S3, et tu fais du SELECT dessus directement. Pas de serveur à allumer, pas de cluster à gérer.
SELECT
customer_id,
COUNT(*) AS nb_commandes,
SUM(amount) AS ca_total
FROM commandes
WHERE order_date >= DATE '2026-01-01'
GROUP BY customer_id
ORDER BY ca_total DESC;Tu écris ta requête, Athena la lance sur les fichiers S3 et tu as le résultat comme une base de données classique. Tu payes uniquement la donnée scannée. C'est l'outil parfait pour explorer la donnée brute et la valider avant de la transformer.
Glue ETL et Lambda : la transformation
Une fois la donnée comprise, il faut la nettoyer et la transformer. Deux outils selon le volume :
- Glue ETL : des jobs Spark (en PySpark) managés. C'est l'artillerie lourde pour traiter de gros volumes, convertir du CSV en Parquet, dédupliquer, joindre. Tu écris ta logique, AWS gère le cluster Spark derrière et le coupe quand c'est fini.
- Lambda : des petites fonctions qui se déclenchent sur événement. Un fichier arrive dans S3 ? Lambda part toute seule pour un traitement simple donc c'est parfait pour les micro-tâches mais pas pour du gros batch.
La règle simple : gros volume et transformation lourde => Glue ETL. Micro-traitements événementiels => Lambda.
Redshift : l'entrepôt (suite de transformation)
Amazon Redshift, c'est le data warehouse d'AWS. Une base colonnaire pensée pour l'analytique sur gros volumes, dans la même famille que Snowflake ou BigQuery.
La question que tout le monde se pose et c'est Athena ou Redshift ? ==> Athena pour requêter le lake à la demande sans rien gérer, Redshift quand tu veux un entrepôt structuré avec des perfs stables pour de la BI au quotidien. On creusera cela dans le futur dans un article dédié.
Step Functions : l'orchestration
On a maintenant plein de briques (un crawler, un job Glue, un chargement Redshift). Il faut les enchaîner dans le bon ordre, automatiquement, tous les matins. C'est le rôle de Step Functions où on décrit un pipeline comme une suite d'étapes, et AWS l'exécute, gère les erreurs et les relances.
À côté, tu peux voir un service au nom de EventBridge (c'est pour déclencher sur planning ou sur événement) et MWAA (du Airflow managé, si tu veux l'écosystème Airflow). Mais le réflexe par défaut pour démarrer, c'est Step Functions.
Lake Formation et KMS : la gouvernance (sécurité)
Quand la donnée commence à être partagée entre plusieurs personnes, il faut gérer qui voit quoi. AWS Lake Formation ajoute des permissions fines sur le catalogue et le lake (accès au niveau table, colonne, ligne). KMS gère le chiffrement. Et IAM, qu'on verra dès le départ, gouverne les accès de base.
Le pipeline complet, vue d'ensemble
Si on remet tout dans l'ordre du projet, ça donne ça :
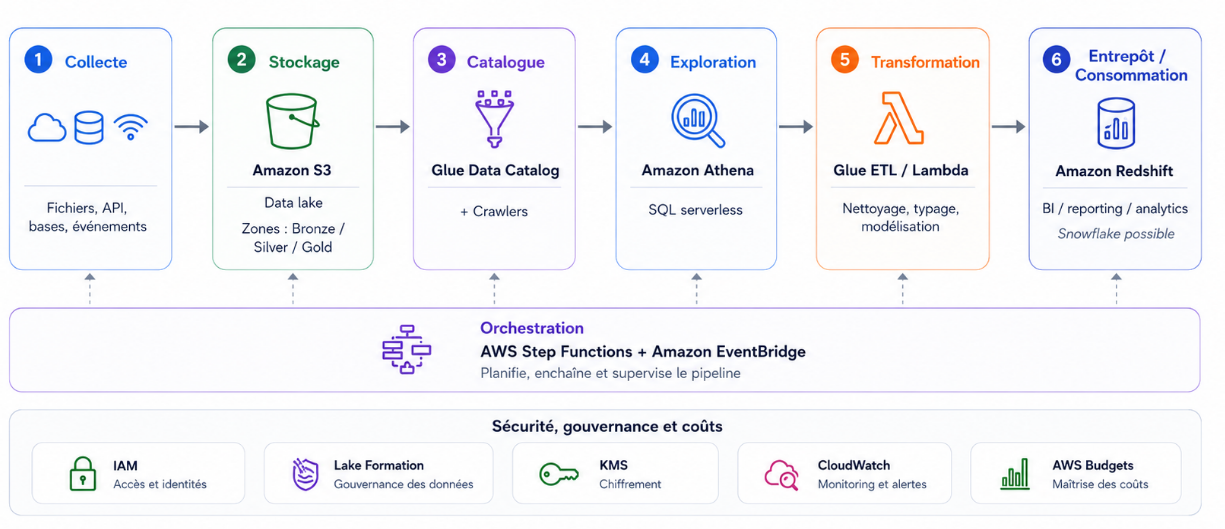
Chaque service fait une chose. Tu sais d'où vient la donnée et où elle va. Et tout ce qu'on construira dans la série passera par ce chemin.
ELT, pas ETL : le pattern qu'on suit
Petit point d'architecture important, parce qu'il conditionne tout le reste.
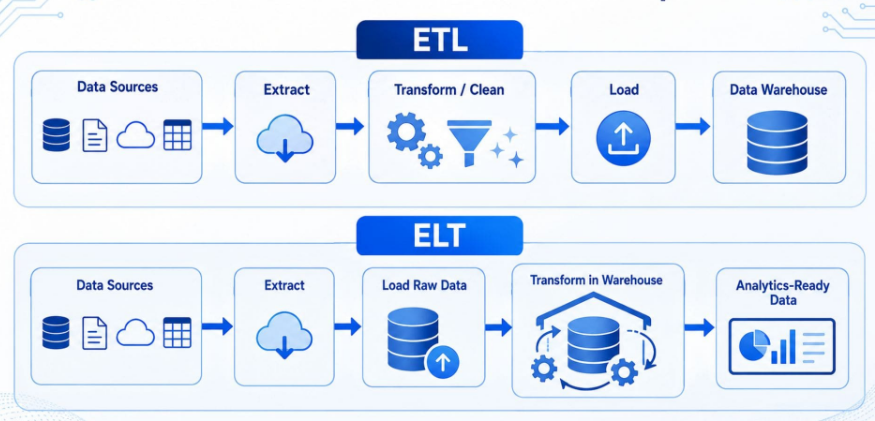
Dans l'ancien monde (Talend, Informatica), on faisait de l'ETL donc on extrayait la donnée, on la transformait sur un serveur dédié à côté, puis on la chargeait propre dans la base. Le problème, c'est que le serveur de transformation au milieu, il est couteux à acheter, à dimensionner et à maintenir.
Avec le cloud, on est passé à l'ELT donc on charge d'abord la donnée brute dans le lake ou l'entrepôt, et on la transforme dedans, avec la puissance de calcul du cloud. Pas de serveur ETL au milieu. C'est exactement la logique que j'expliquais dans l'article sur dbt, et c'est le pattern qu'on suit sur AWS car la donnée atterrit dans S3, et on la transforme avec Athena, Glue ou dbt sans jamais la sortir du cloud.
AWS pour la data en une phrase
Un data lake sur S3, un catalogue avec Glue, du SQL serverless avec Athena, un entrepôt avec Redshift, des traitements avec Glue ETL et Lambda, le tout orchestré par Step Functions.
Voilà. Si tu retiens cette phrase, tu as déjà la structure de base. Tous les autres services data gravitent autour de ces six-là.
Où AWS s'arrête et où Snowflake et dbt prennent le relais
C'est le point qui relie cette série au reste de mes formations.
AWS te donne l'infrastructure avec le stockage (S3), le moteur de requête (Athena), l'entrepôt (Redshift), les outils de transformation et d'orchestration. C'est le socle.
Mais ce socle ne te dit pas comment modéliser proprement tes transformations. Et c'est là que la stack se complète :
- Tu peux poser Snowflake comme entrepôt à la place de Redshift. Le pont est direct car ta donnée est déjà dans S3, et Snowflake la lit via un external stage et Snowpipe. On le fera dans la série.
- Tu peux brancher dbt sur Athena ou Redshift pour structurer tes modèles en couches (staging, marts), comme on le fait sur Snowflake.
Au final, AWS, Snowflake et dbt ne sont pas des sujets concurrents. C'est la même chaîne car AWS fournit le terrain, Snowflake ou Redshift servent d'entrepôt, dbt organise les transformations.
La suite ?
Cet article, c'était la carte avec les services qui comptent et l'ordre dans lequel on les utilise. Dans le prochain, on passe à la pratique avec la création du compte AWS.
Abonne-toi à la newsletter pour le recevoir directement dans ta boîte mail ;)
De nouveaux articles data chaque semaine
Aller plus loin
Tu prépares la certification AWS Certified Data Engineer Associate (DEA-C01) ? Cette série couvre son périmètre (S3, Glue, Athena, Redshift, Lambda, Step Functions, Lake Formation). Pour t'entraîner, j'ai créé des questions d'examen blanc en français.
👉 S'entraîner sur DataCertification.fr
Tu veux que je t'accompagne sur ton projet data (AWS, Snowflake, dbt, modélisation, coûts) ?
